 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Collaborative 3D Object Detection in Presence of Pose Errors
Nov 15, 2022Collaborative 3D object detection exploits information exchange among multiple agents to enhance accuracy of object detection in presence of sensor impairments such as occlusion. However, in practice, pose estimation errors due to imperfect localization would cause spatial message misalignment and significantly reduce the performance of collaboration. To alleviate adverse impacts of pose errors, we propose CoAlign, a novel hybrid collaboration framework that is robust to unknown pose errors. The proposed solution relies on a novel agent-object pose graph modeling to enhance pose consistency among collaborating agents. Furthermore, we adopt a multi-scale data fusion strategy to aggregate intermediate features at multiple spatial resolutions. Comparing with previous works, which require ground-truth pose for training supervision, our proposed CoAlign is more practical since it doesn't require any ground-truth pose supervision in the training and makes no specific assumptions on pose errors. Extensive evaluation of the proposed method is carried out on multiple datasets, certifying that CoAlign significantly reduce relative localization error and achieving the state of art detection performance when pose errors exist. Code are made available for the use of the research community at https://github.com/yifanlu0227/CoAlign.
3D Point Cloud Processing and Learning for Autonomous Driving
Mar 01, 2020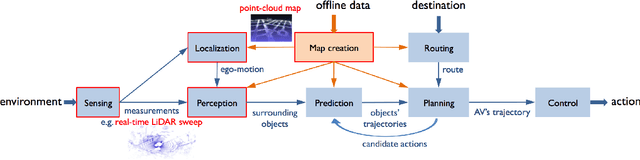
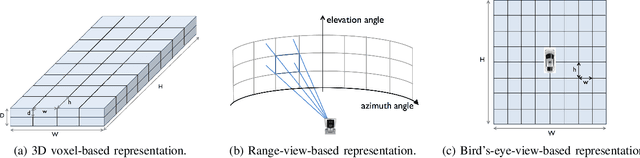

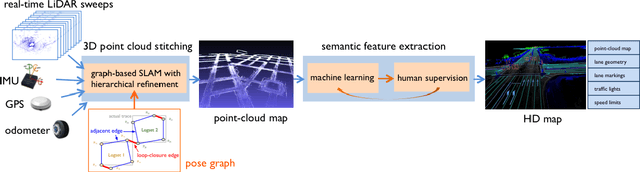
We present a review of 3D point cloud processing and learning for autonomous driving. As one of the most important sensors in autonomous vehicles, light detection and ranging (LiDAR) sensors collect 3D point clouds that precisely record the external surfaces of objects and scenes. The tools for 3D point cloud processing and learning are critical to the map creation, localization, and perception modules in an autonomous vehicle. While much attention has been paid to data collected from cameras, such as images and videos, an increasing number of researchers have recognized the importance and significance of LiDAR in autonomous driving and have proposed processing and learning algorithms to exploit 3D point clouds. We review the recent progress in this research area and summarize what has been tried and what is needed for practical and safe autonomous vehicles. We also offer perspectives on open issues that are needed to be solved in the future.
Large-scale 3D point cloud representations via graph inception networks with applications to autonomous driving
Jun 26, 2019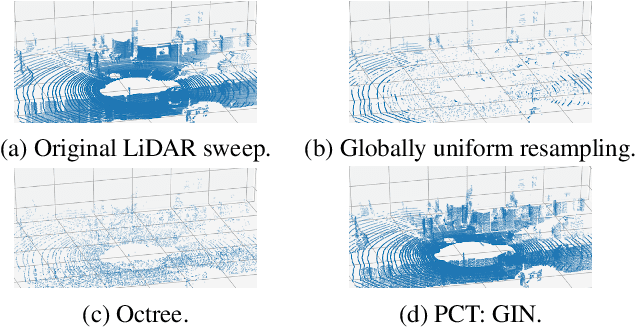

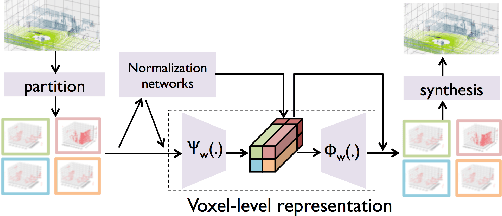

We present a novel graph-neural-network-based system to effectively represent large-scale 3D point clouds with the applications to autonomous driving. Many previous works studied the representations of 3D point clouds based on two approaches, voxelization, which causes discretization errors and learning, which is hard to capture huge variations in large-scale scenarios. In this work, we combine voxelization and learning: we discretize the 3D space into voxels and propose novel graph inception networks to represent 3D points in each voxel. This combination makes the system avoid discretization errors and work for large-scale scenarios. The entire system for large-scale 3D point clouds acts like the blocked discrete cosine transform for 2D images; we thus call it the point cloud neural transform (PCT). We further apply the proposed PCT to represent real-time LiDAR sweeps produced by self-driving cars and the PCT with graph inception networks significantly outperforms its competitors.