 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackward-Forward Algorithm: An Improvement towards Extreme Learning Machine
Jul 29, 2019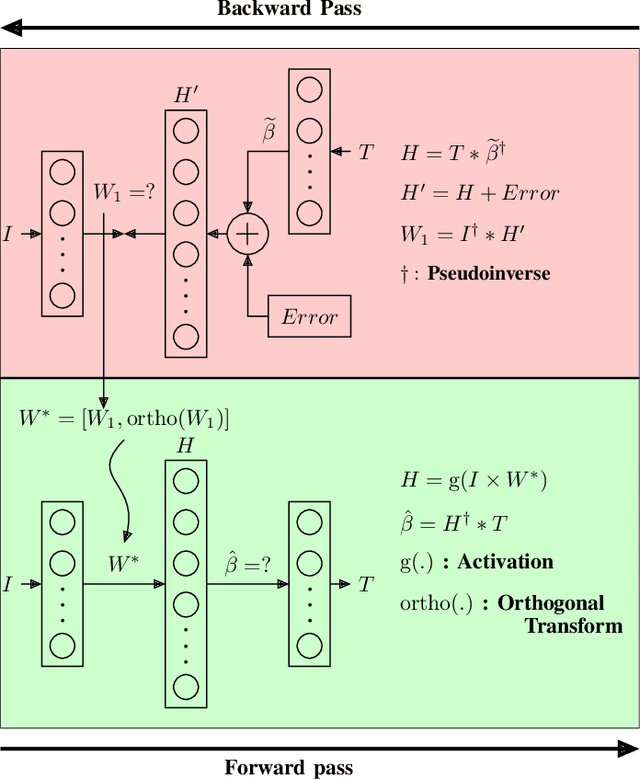
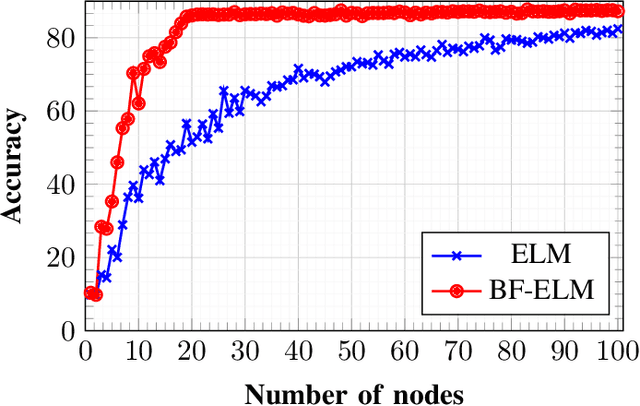
Extreme learning machine (ELM), a randomized learning paradigm for a single hidden layer feed-forward network, has gained significant attention for solving problems in diverse domains due to its faster learning ability. The output weights in ELM are determined by an analytic procedure, while the input weights and biases are randomly generated and fixed during the training phase. The learning performance of ELM is highly sensitive to many factors such as the number of nodes in the hidden layer, the initialization of input weight and the type of activation functions in the hidden layer. Moreover, the performance of ELM is affected due to the presence of random input weight and the model suffers from ill posed problem. Hence, here we propose a backward-forward algorithm for a single feed-forward neural network that improves the generalization capability of the network with fewer hidden nodes. Here, both input and output weights are determined mathematically which gives the network its performance advantages. The proposed model provides an improvement over extreme learning machine with respect to the number of nodes used for generalization.
The Unconstrained Ear Recognition Challenge 2019 - ArXiv Version With Appendix
Mar 14, 2019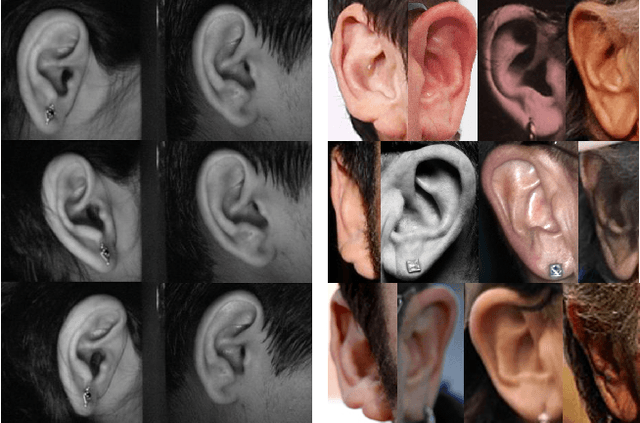

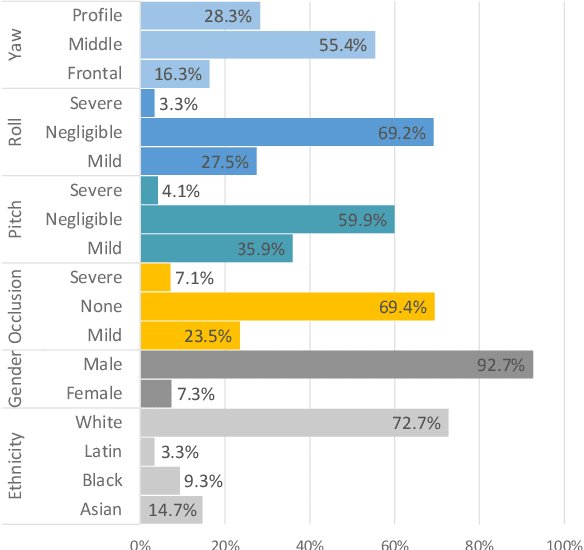
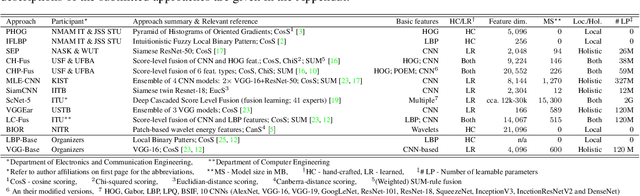
This paper presents a summary of the 2019 Unconstrained Ear Recognition Challenge (UERC), the second in a series of group benchmarking efforts centered around the problem of person recognition from ear images captured in uncontrolled settings. The goal of the challenge is to assess the performance of existing ear recognition techniques on a challenging large-scale ear dataset and to analyze performance of the technology from various viewpoints, such as generalization abilities to unseen data characteristics, sensitivity to rotations, occlusions and image resolution and performance bias on sub-groups of subjects, selected based on demographic criteria, i.e. gender and ethnicity. Research groups from 12 institutions entered the competition and submitted a total of 13 recognition approaches ranging from descriptor-based methods to deep-learning models. The majority of submissions focused on ensemble based methods combining either representations from multiple deep models or hand-crafted with learned image descriptors. Our analysis shows that methods incorporating deep learning models clearly outperform techniques relying solely on hand-crafted descriptors, even though both groups of techniques exhibit similar behaviour when it comes to robustness to various covariates, such presence of occlusions, changes in (head) pose, or variability in image resolution. The results of the challenge also show that there has been considerable progress since the first UERC in 2017, but that there is still ample room for further research in this area.
Stratified SIFT Matching for Human Iris Recognition
Jan 06, 2013

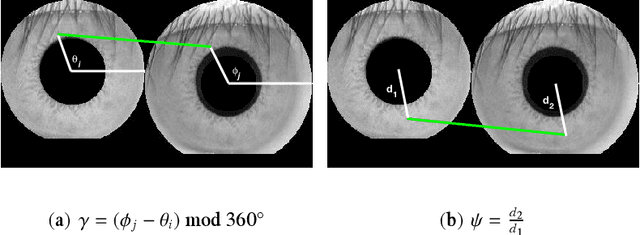
This paper proposes an efficient three fold stratified SIFT matching for iris recognition. The objective is to filter wrongly paired conventional SIFT matches. In Strata I, the keypoints from gallery and probe iris images are paired using traditional SIFT approach. Due to high image similarity at different regions of iris there may be some impairments. These are detected and filtered by finding gradient of paired keypoints in Strata II. Further, the scaling factor of paired keypoints is used to remove impairments in Strata III. The pairs retained after Strata III are likely to be potential matches for iris recognition. The proposed system performs with an accuracy of 96.08% and 97.15% on publicly available CASIAV3 and BATH databases respectively. This marks significant improvement of accuracy and FAR over the existing SIFT matching for iris.
* 7 pages
Feature Level Clustering of Large Biometric Database
Feb 02, 2010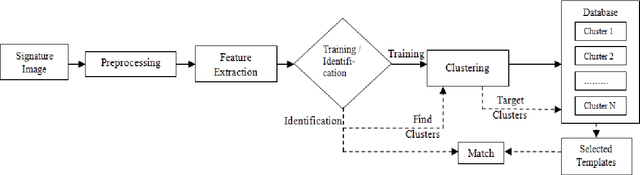
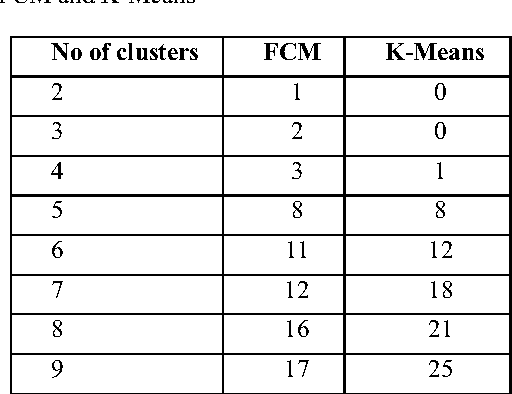
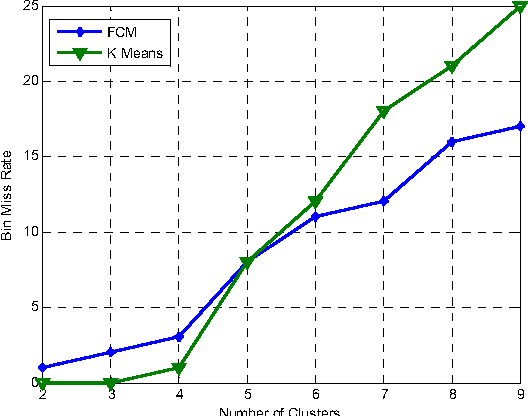
This paper proposes an efficient technique for partitioning large biometric database during identification. In this technique feature vector which comprises of global and local descriptors extracted from offline signature are used by fuzzy clustering technique to partition the database. As biometric features posses no natural order of sorting, thus it is difficult to index them alphabetically or numerically. Hence, some supervised criteria is required to partition the search space. At the time of identification the fuzziness criterion is introduced to find the nearest clusters for declaring the identity of query sample. The system is tested using bin-miss rate and performs better in comparison to traditional k-means approach.