 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Falcon Series of Open Language Models
Nov 29, 2023



We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--the largest openly documented pretraining run. Falcon-180B significantly outperforms models such as PaLM or Chinchilla, and improves upon concurrently developed models such as LLaMA 2 or Inflection-1. It nears the performance of PaLM-2-Large at a reduced pretraining and inference cost, making it, to our knowledge, one of the three best language models in the world along with GPT-4 and PaLM-2-Large. We report detailed evaluations, as well as a deep dive into the methods and custom tooling employed to pretrain Falcon. Notably, we report on our custom distributed training codebase, allowing us to efficiently pretrain these models on up to 4,096 A100s on cloud AWS infrastructure with limited interconnect. We release a 600B tokens extract of our web dataset, as well as the Falcon-7/40/180B models under a permissive license to foster open-science and accelerate the development of an open ecosystem of large language models.
8-bit Numerical Formats for Deep Neural Networks
Jun 06, 2022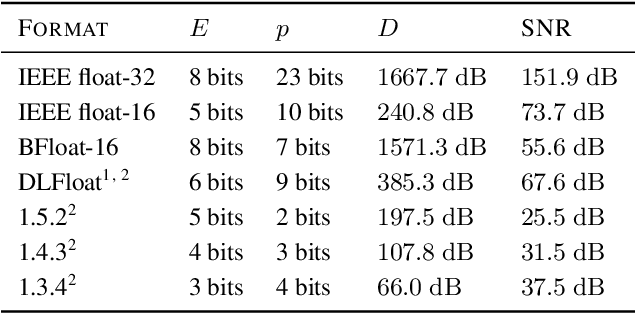
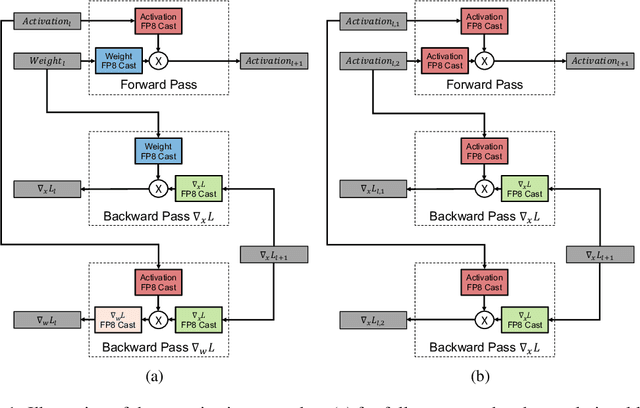
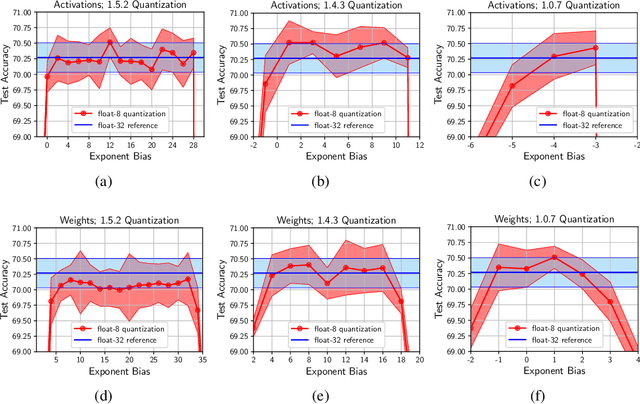
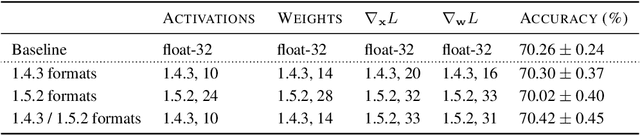
Given the current trend of increasing size and complexity of machine learning architectures, it has become of critical importance to identify new approaches to improve the computational efficiency of model training. In this context, we address the advantages of floating-point over fixed-point representation, and present an in-depth study on the use of 8-bit floating-point number formats for activations, weights, and gradients for both training and inference. We explore the effect of different bit-widths for exponents and significands and different exponent biases. The experimental results demonstrate that a suitable choice of these low-precision formats enables faster training and reduced power consumption without any degradation in accuracy for a range of deep learning models for image classification and language processing.
Parallel Training of Deep Networks with Local Updates
Dec 07, 2020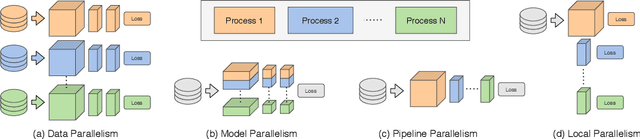
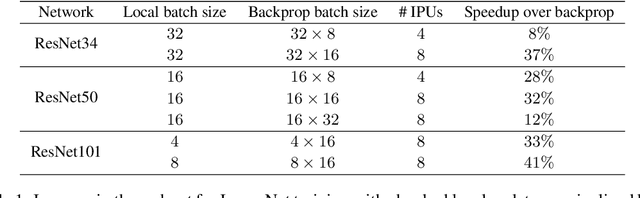
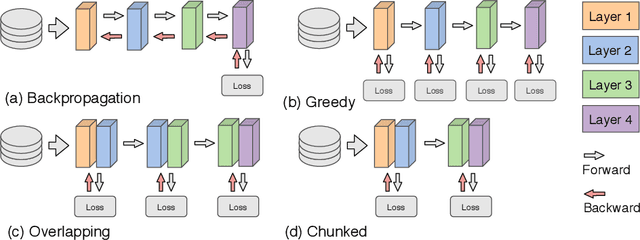
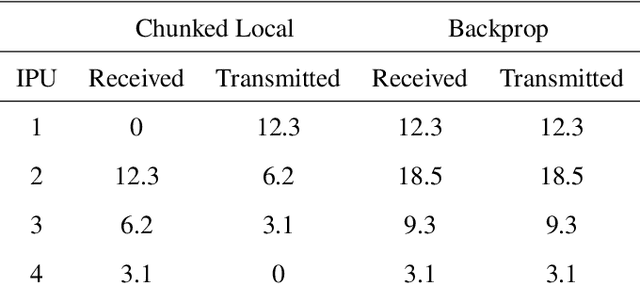
Deep learning models trained on large data sets have been widely successful in both vision and language domains. As state-of-the-art deep learning architectures have continued to grow in parameter count so have the compute budgets and times required to train them, increasing the need for compute-efficient methods that parallelize training. Two common approaches to parallelize the training of deep networks have been data and model parallelism. While useful, data and model parallelism suffer from diminishing returns in terms of compute efficiency for large batch sizes. In this paper, we investigate how to continue scaling compute efficiently beyond the point of diminishing returns for large batches through local parallelism, a framework which parallelizes training of individual layers in deep networks by replacing global backpropagation with truncated layer-wise backpropagation. Local parallelism enables fully asynchronous layer-wise parallelism with a low memory footprint, and requires little communication overhead compared with model parallelism. We show results in both vision and language domains across a diverse set of architectures, and find that local parallelism is particularly effective in the high-compute regime.