 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVix at SemEval-2022 Task 2: It Takes One to Know One? Idiomaticity Detection using Zero and One Shot Learning
Feb 04, 2022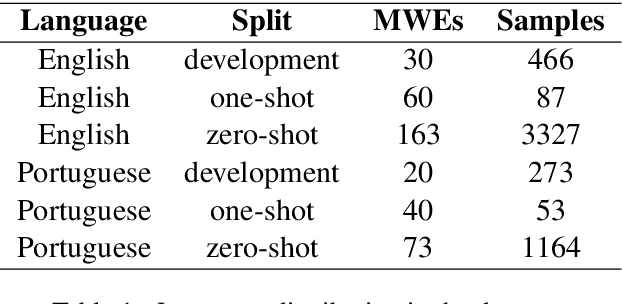
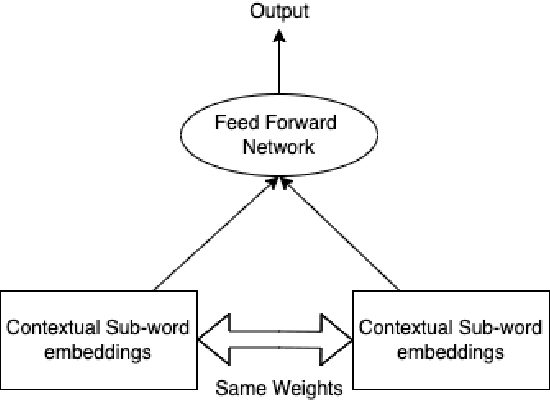

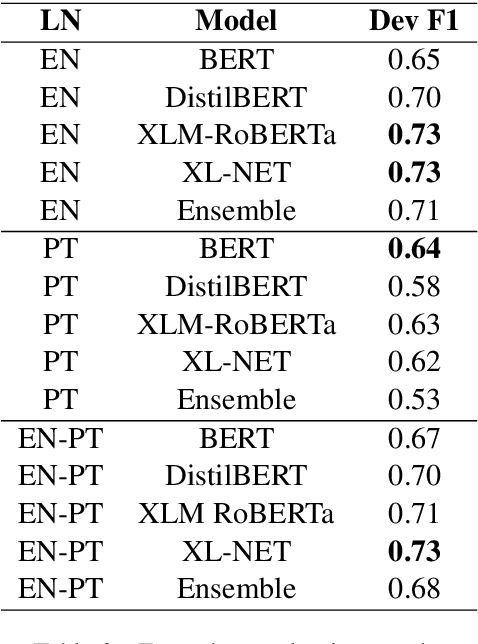
Large Language Models have been successful in a wide variety of Natural Language Processing tasks by capturing the compositionality of the text representations. In spite of their great success, these vector representations fail to capture meaning of idiomatic multi-word expressions (MWEs). In this paper, we focus on the detection of idiomatic expressions by using binary classification. We use a dataset consisting of the literal and idiomatic usage of MWEs in English and Portuguese. Thereafter, we perform the classification in two different settings: zero shot and one shot, to determine if a given sentence contains an idiom or not. N shot classification for this task is defined by N number of common idioms between the training and testing sets. In this paper, we train multiple Large Language Models in both the settings and achieve an F1 score (macro) of 0.73 for the zero shot setting and an F1 score (macro) of 0.85 for the one shot setting. An implementation of our work can be found at https://github.com/ashwinpathak20/Idiomaticity_Detection_Using_Few_Shot_Learning .
AbuseAnalyzer: Abuse Detection, Severity and Target Prediction for Gab Posts
Oct 08, 2020
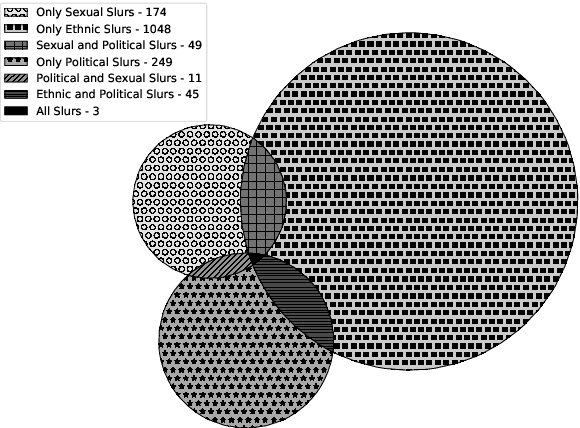
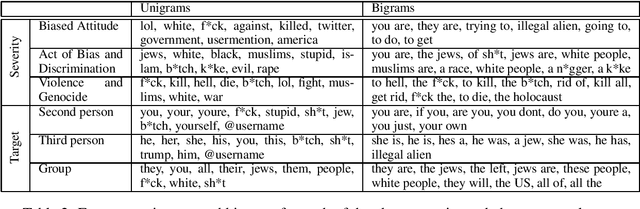

While extensive popularity of online social media platforms has made information dissemination faster, it has also resulted in widespread online abuse of different types like hate speech, offensive language, sexist and racist opinions, etc. Detection and curtailment of such abusive content is critical for avoiding its psychological impact on victim communities, and thereby preventing hate crimes. Previous works have focused on classifying user posts into various forms of abusive behavior. But there has hardly been any focus on estimating the severity of abuse and the target. In this paper, we present a first of the kind dataset with 7601 posts from Gab which looks at online abuse from the perspective of presence of abuse, severity and target of abusive behavior. We also propose a system to address these tasks, obtaining an accuracy of ~80% for abuse presence, ~82% for abuse target prediction, and ~65% for abuse severity prediction.