 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVix at SemEval-2022 Task 2: It Takes One to Know One? Idiomaticity Detection using Zero and One Shot Learning
Paper and Code
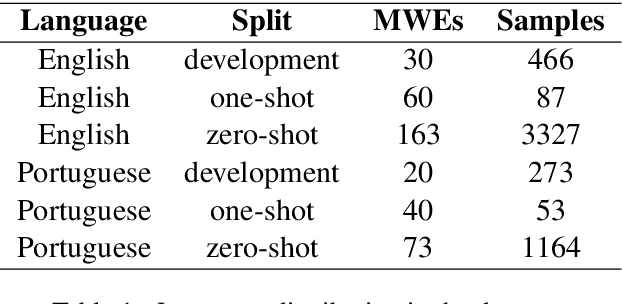
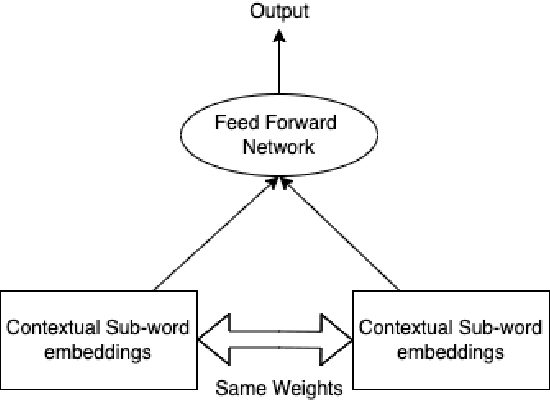

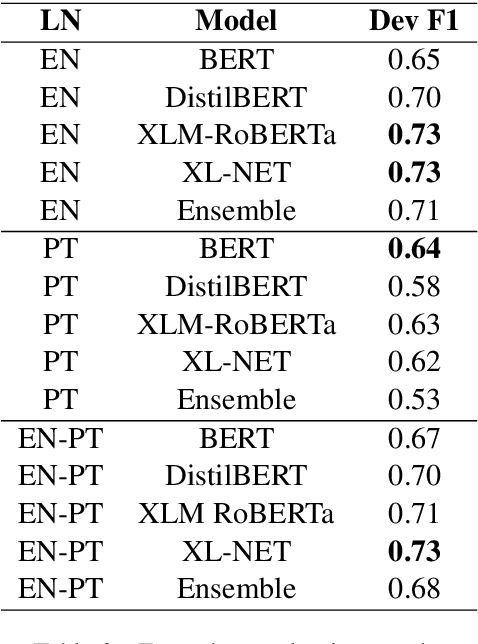
Large Language Models have been successful in a wide variety of Natural Language Processing tasks by capturing the compositionality of the text representations. In spite of their great success, these vector representations fail to capture meaning of idiomatic multi-word expressions (MWEs). In this paper, we focus on the detection of idiomatic expressions by using binary classification. We use a dataset consisting of the literal and idiomatic usage of MWEs in English and Portuguese. Thereafter, we perform the classification in two different settings: zero shot and one shot, to determine if a given sentence contains an idiom or not. N shot classification for this task is defined by N number of common idioms between the training and testing sets. In this paper, we train multiple Large Language Models in both the settings and achieve an F1 score (macro) of 0.73 for the zero shot setting and an F1 score (macro) of 0.85 for the one shot setting. An implementation of our work can be found at https://github.com/ashwinpathak20/Idiomaticity_Detection_Using_Few_Shot_Learning .