 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting formation of a Tropical Cyclone Using Reanalysis Data
Dec 10, 2022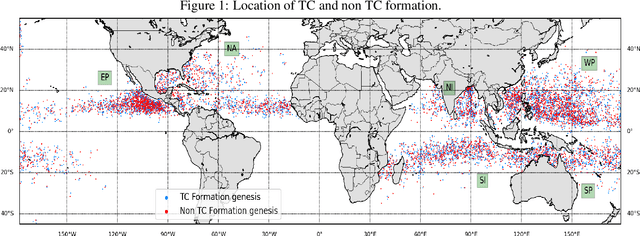
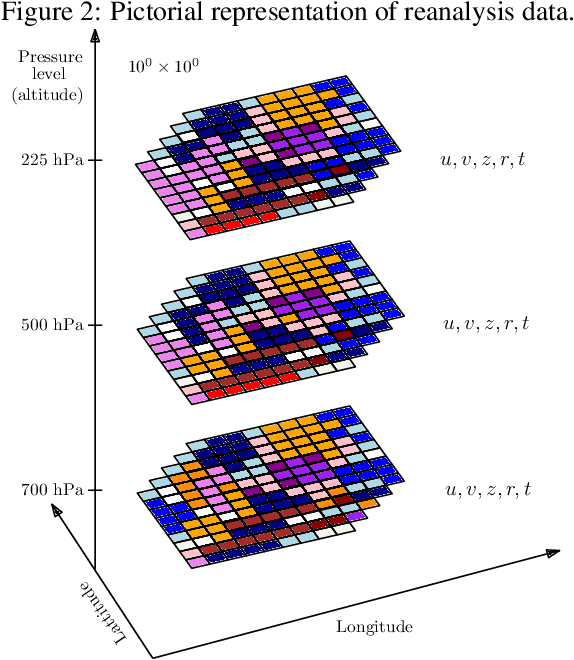
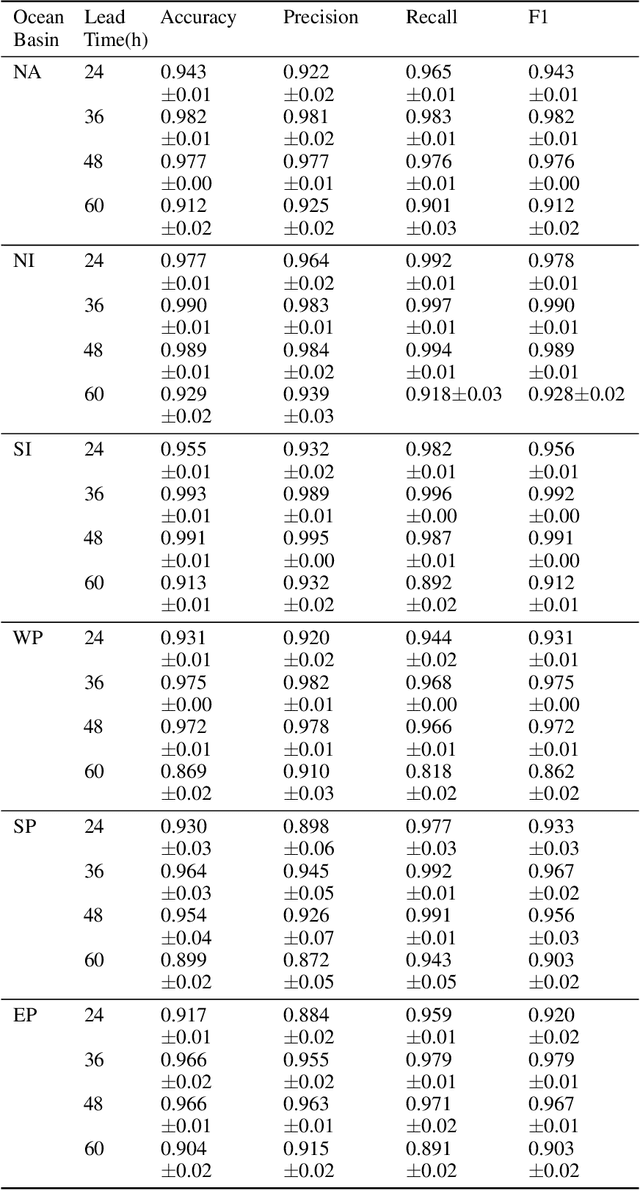
The tropical cyclone formation process is one of the most complex natural phenomena which is governed by various atmospheric, oceanographic, and geographic factors that varies with time and space. Despite several years of research, accurately predicting tropical cyclone formation remains a challenging task. While the existing numerical models have inherent limitations, the machine learning models fail to capture the spatial and temporal dimensions of the causal factors behind TC formation. In this study, a deep learning model has been proposed that can forecast the formation of a tropical cyclone with a lead time of up to 60 hours with high accuracy. The model uses the high-resolution reanalysis data ERA5 (ECMWF reanalysis 5th generation), and best track data IBTrACS (International Best Track Archive for Climate Stewardship) to forecast tropical cyclone formation in six ocean basins of the world. For 60 hours lead time the models achieve an accuracy in the range of 86.9% - 92.9% across the six ocean basins. The model takes about 5-15 minutes of training time depending on the ocean basin, and the amount of data used and can predict within seconds, thereby making it suitable for real-life usage.
SMU: smooth activation function for deep networks using smoothing maximum technique
Nov 08, 2021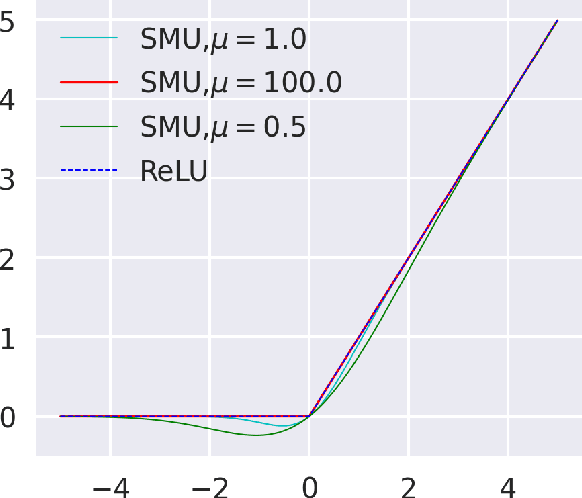

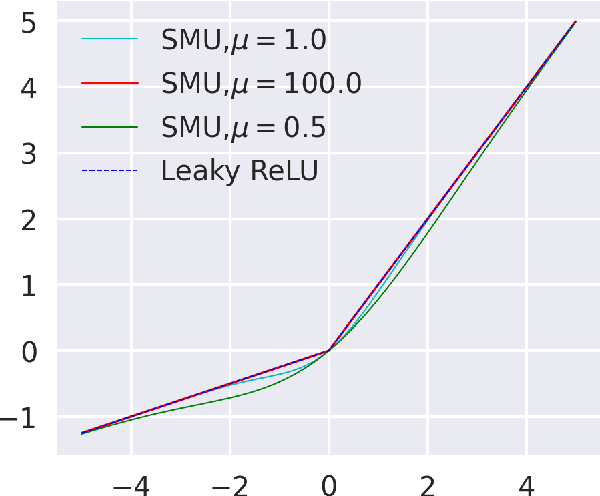
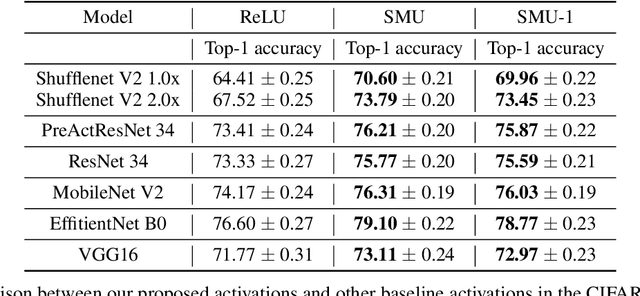
Deep learning researchers have a keen interest in proposing two new novel activation functions which can boost network performance. A good choice of activation function can have significant consequences in improving network performance. A handcrafted activation is the most common choice in neural network models. ReLU is the most common choice in the deep learning community due to its simplicity though ReLU has some serious drawbacks. In this paper, we have proposed a new novel activation function based on approximation of known activation functions like Leaky ReLU, and we call this function Smooth Maximum Unit (SMU). Replacing ReLU by SMU, we have got 6.22% improvement in the CIFAR100 dataset with the ShuffleNet V2 model.
SAU: Smooth activation function using convolution with approximate identities
Sep 27, 2021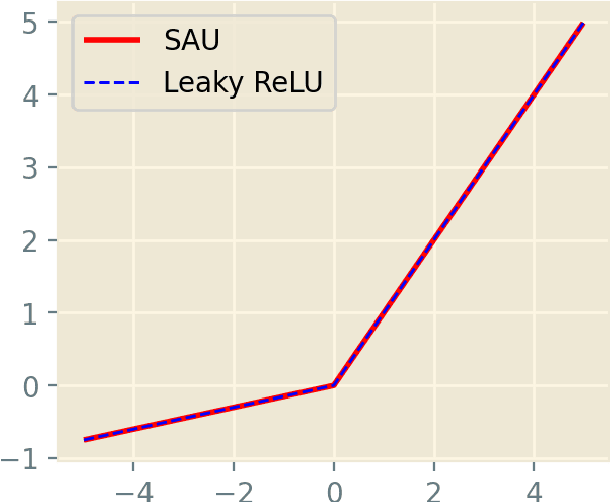
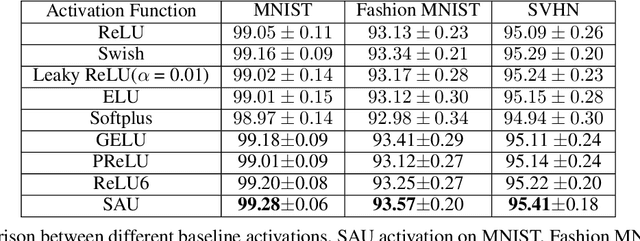
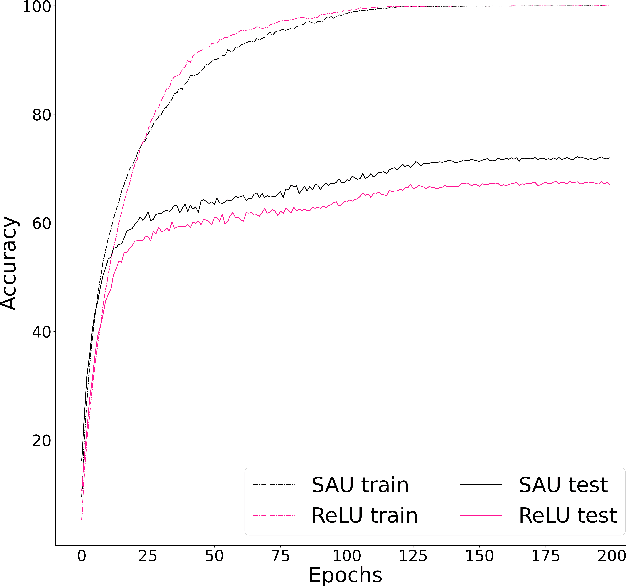

Well-known activation functions like ReLU or Leaky ReLU are non-differentiable at the origin. Over the years, many smooth approximations of ReLU have been proposed using various smoothing techniques. We propose new smooth approximations of a non-differentiable activation function by convolving it with approximate identities. In particular, we present smooth approximations of Leaky ReLU and show that they outperform several well-known activation functions in various datasets and models. We call this function Smooth Activation Unit (SAU). Replacing ReLU by SAU, we get 5.12% improvement with ShuffleNet V2 (2.0x) model on CIFAR100 dataset.
ErfAct and PSerf: Non-monotonic smooth trainable Activation Functions
Sep 19, 2021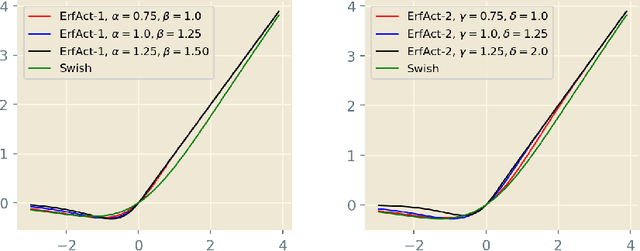

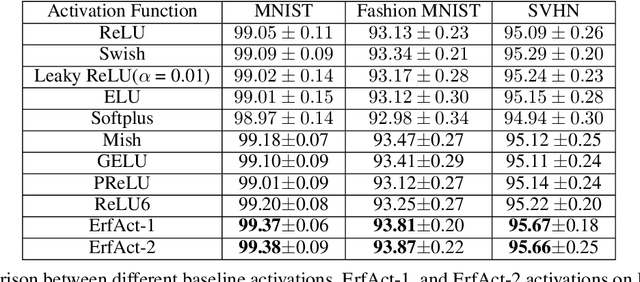
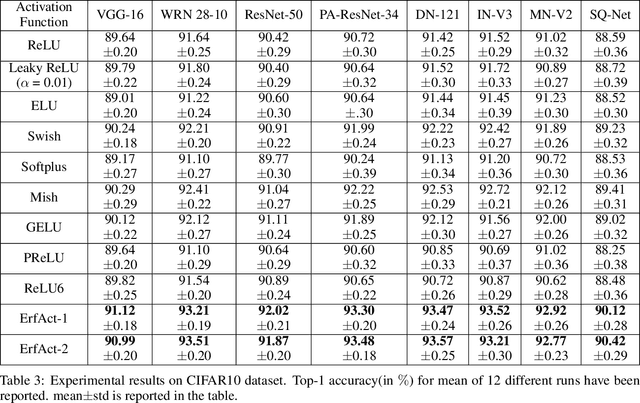
An activation function is a crucial component of a neural network that introduces non-linearity in the network. The state-of-the-art performance of a neural network depends on the perfect choice of an activation function. We propose two novel non-monotonic smooth trainable activation functions, called ErfAct and PSerf. Experiments suggest that the proposed functions improve the network performance significantly compared to the widely used activations like ReLU, Swish, and Mish. Replacing ReLU by ErfAct and PSerf, we have 5.21% and 5.04% improvement for top-1 accuracy on PreactResNet-34 network in CIFAR100 dataset, 2.58% and 2.76% improvement for top-1 accuracy on PreactResNet-34 network in CIFAR10 dataset, 1.0%, and 1.0% improvement on mean average precision (mAP) on SSD300 model in Pascal VOC dataset.
Tropical cyclone intensity estimations over the Indian ocean using Machine Learning
Jul 07, 2021
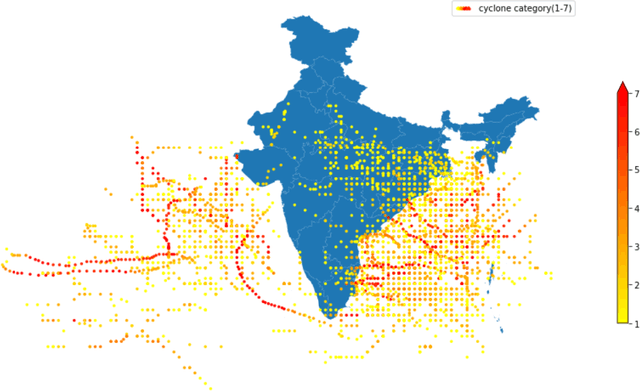
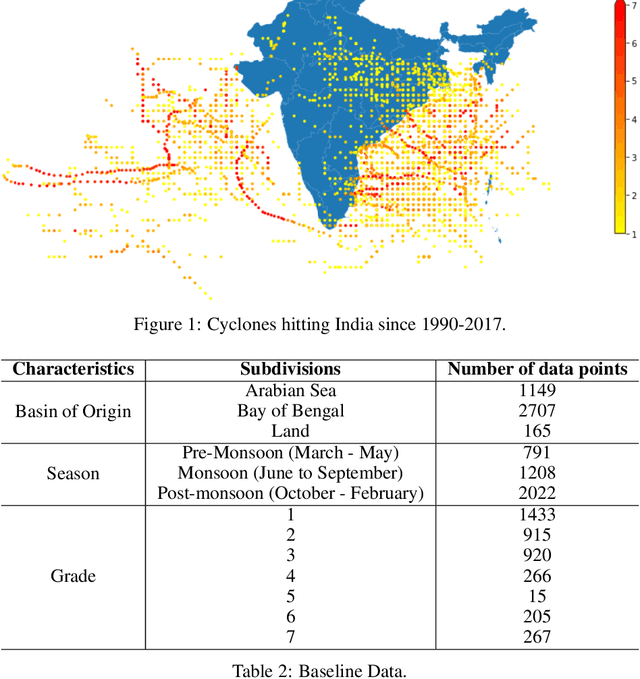
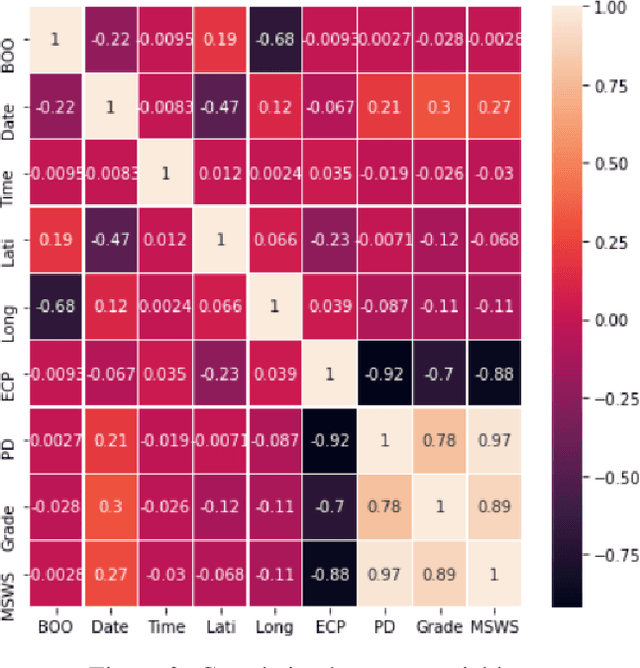
Tropical cyclones are one of the most powerful and destructive natural phenomena on earth. Tropical storms and heavy rains can cause floods, which lead to human lives and economic loss. Devastating winds accompanying cyclones heavily affect not only the coastal regions, even distant areas. Our study focuses on the intensity estimation, particularly cyclone grade and maximum sustained surface wind speed (MSWS) of a tropical cyclone over the North Indian Ocean. We use various machine learning algorithms to estimate cyclone grade and MSWS. We have used the basin of origin, date, time, latitude, longitude, estimated central pressure, and pressure drop as attributes of our models. We use multi-class classification models for the categorical outcome variable, cyclone grade, and regression models for MSWS as it is a continuous variable. Using the best track data of 28 years over the North Indian Ocean, we estimate grade with an accuracy of 88% and MSWS with a root mean square error (RMSE) of 2.3. For higher grade categories (5-7), accuracy improves to an average of 98.84%. We tested our model with two recent tropical cyclones in the North Indian Ocean, Vayu and Fani. For grade, we obtained an accuracy of 93.22% and 95.23% respectively, while for MSWS, we obtained RMSE of 2.2 and 3.4 and $R^2$ of 0.99 and 0.99, respectively.
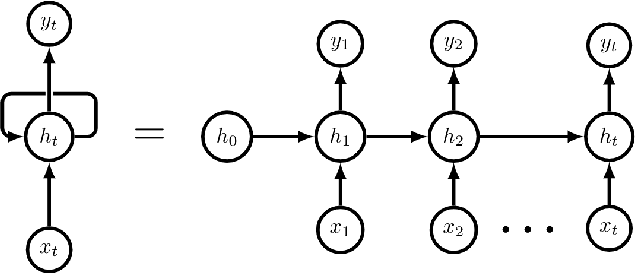
Intensity Prediction of Tropical Cyclones using Long Short-Term Memory Network
Jul 07, 2021
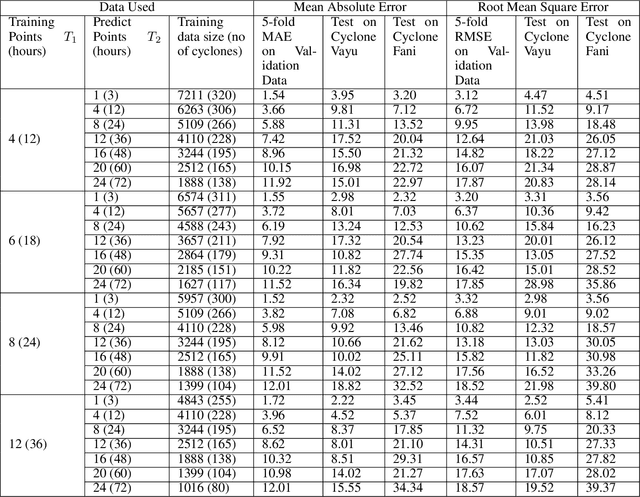
Tropical cyclones can be of varied intensity and cause a huge loss of lives and property if the intensity is high enough. Therefore, the prediction of the intensity of tropical cyclones advance in time is of utmost importance. We propose a novel stacked bidirectional long short-term memory network (BiLSTM) based model architecture to predict the intensity of a tropical cyclone in terms of Maximum surface sustained wind speed (MSWS). The proposed model can predict MSWS well advance in time (up to 72 h) with very high accuracy. We have applied the model on tropical cyclones in the North Indian Ocean from 1982 to 2018 and checked its performance on two recent tropical cyclones, namely, Fani and Vayu. The model predicts MSWS (in knots) for the next 3, 12, 24, 36, 48, 60, and 72 hours with a mean absolute error of 1.52, 3.66, 5.88, 7.42, 8.96, 10.15, and 11.92, respectively.
Orthogonal-Padé Activation Functions: Trainable Activation functions for smooth and faster convergence in deep networks
Jun 17, 2021

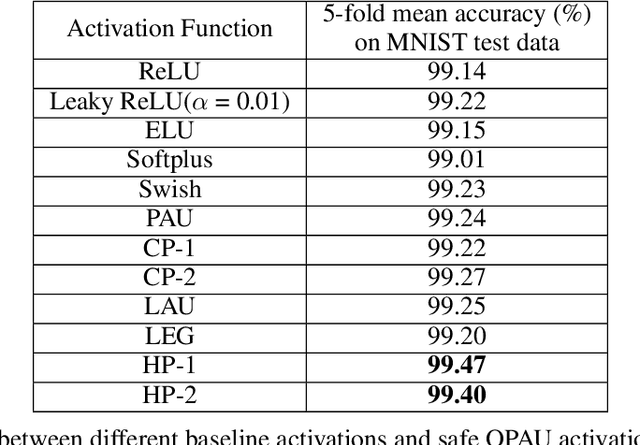
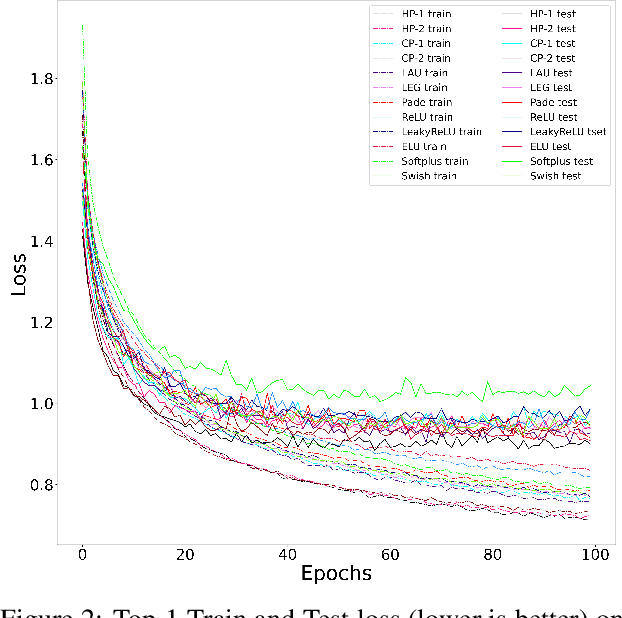
We have proposed orthogonal-Pad\'e activation functions, which are trainable activation functions and show that they have faster learning capability and improves the accuracy in standard deep learning datasets and models. Based on our experiments, we have found two best candidates out of six orthogonal-Pad\'e activations, which we call safe Hermite-Pade (HP) activation functions, namely HP-1 and HP-2. When compared to ReLU, HP-1 and HP-2 has an increment in top-1 accuracy by 5.06% and 4.63% respectively in PreActResNet-34, by 3.02% and 2.75% respectively in MobileNet V2 model on CIFAR100 dataset while on CIFAR10 dataset top-1 accuracy increases by 2.02% and 1.78% respectively in PreActResNet-34, by 2.24% and 2.06% respectively in LeNet, by 2.15% and 2.03% respectively in Efficientnet B0.
Prediction of Landfall Intensity, Location, and Time of a Tropical Cyclone
Mar 30, 2021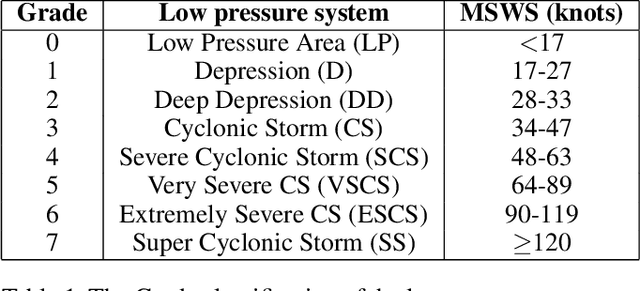
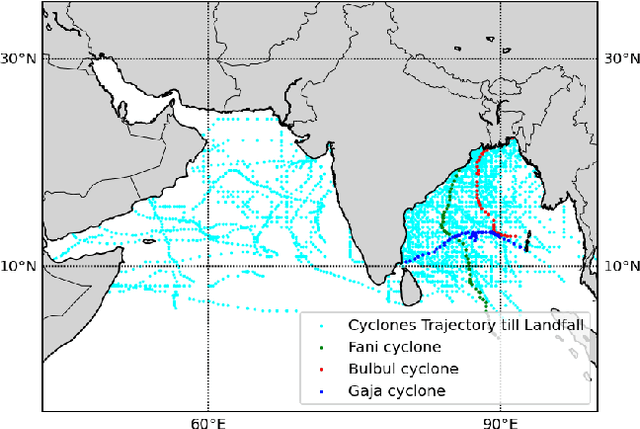
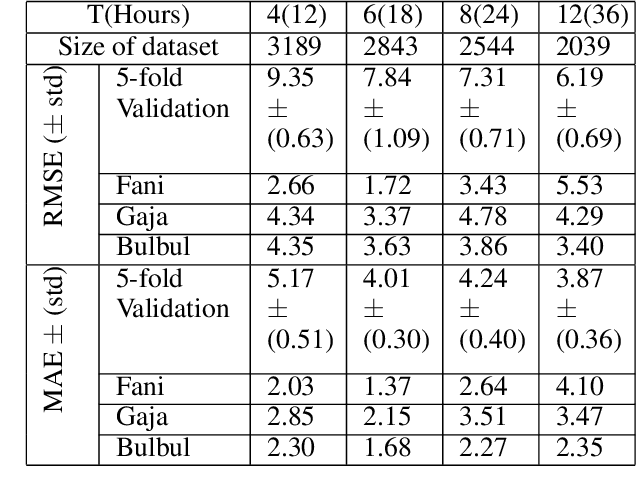
The prediction of the intensity, location and time of the landfall of a tropical cyclone well advance in time and with high accuracy can reduce human and material loss immensely. In this article, we develop a Long Short-Term memory based Recurrent Neural network model to predict intensity (in terms of maximum sustained surface wind speed), location (latitude and longitude), and time (in hours after the observation period) of the landfall of a tropical cyclone which originates in the North Indian ocean. The model takes as input the best track data of cyclone consisting of its location, pressure, sea surface temperature, and intensity for certain hours (from 12 to 36 hours) anytime during the course of the cyclone as a time series and then provide predictions with high accuracy. For example, using 24 hours data of a cyclone anytime during its course, the model provides state-of-the-art results by predicting landfall intensity, time, latitude, and longitude with a mean absolute error of 4.24 knots, 4.5 hours, 0.24 degree, and 0.37 degree respectively, which resulted in a distance error of 51.7 kilometers from the landfall location. We further check the efficacy of the model on three recent devastating cyclones Bulbul, Fani, and Gaja, and achieved better results than the test dataset.
Predicting Landfall's Location and Time of a Tropical Cyclone Using Reanalysis Data
Mar 30, 2021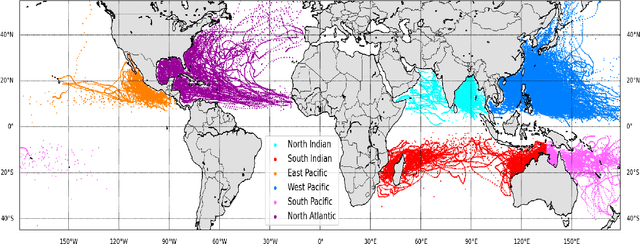

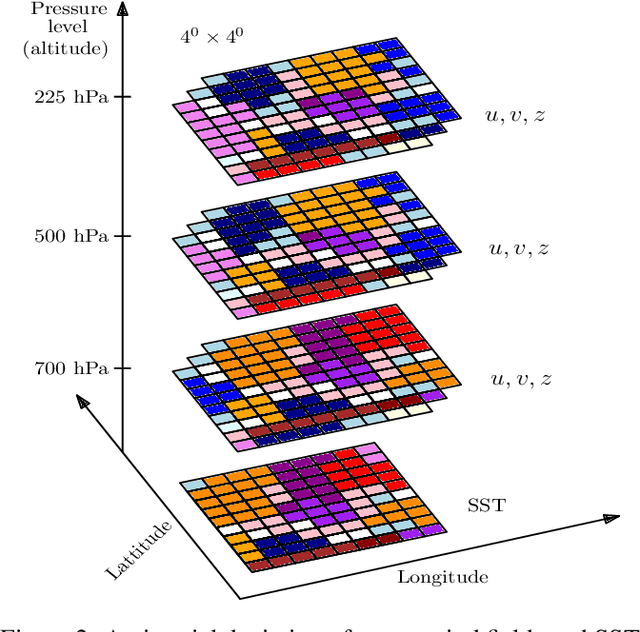
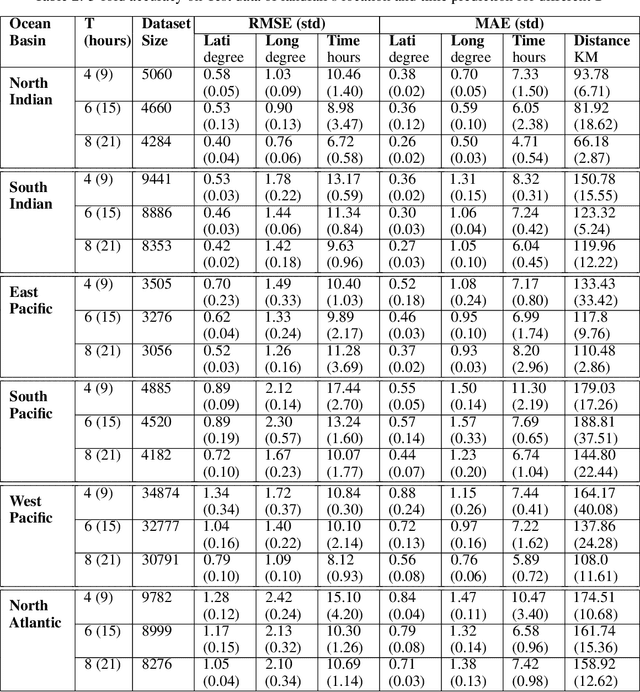
Landfall of a tropical cyclone is the event when it moves over the land after crossing the coast of the ocean. It is important to know the characteristics of the landfall in terms of location and time, well advance in time to take preventive measures timely. In this article, we develop a deep learning model based on the combination of a Convolutional Neural network and a Long Short-Term memory network to predict the landfall's location and time of a tropical cyclone in six ocean basins of the world with high accuracy. We have used high-resolution spacial reanalysis data, ERA5, maintained by European Center for Medium-Range Weather Forecasting (ECMWF). The model takes any 9 hours, 15 hours, or 21 hours of data, during the progress of a tropical cyclone and predicts its landfall's location in terms of latitude and longitude and time in hours. For 21 hours of data, we achieve mean absolute error for landfall's location prediction in the range of 66.18 - 158.92 kilometers and for landfall's time prediction in the range of 4.71 - 8.20 hours across all six ocean basins. The model can be trained in just 30 to 45 minutes (based on ocean basin) and can predict the landfall's location and time in a few seconds, which makes it suitable for real time prediction.
EIS -- a family of activation functions combining Exponential, ISRU, and Softplus
Oct 12, 2020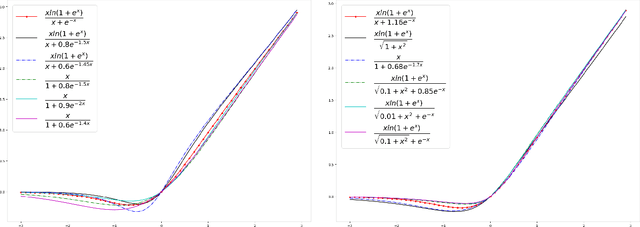
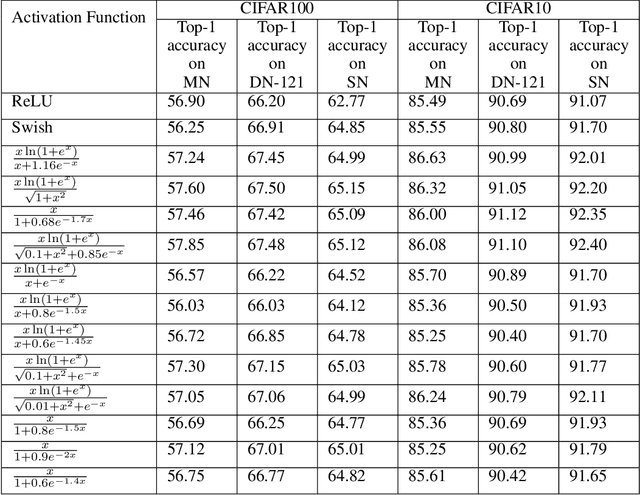
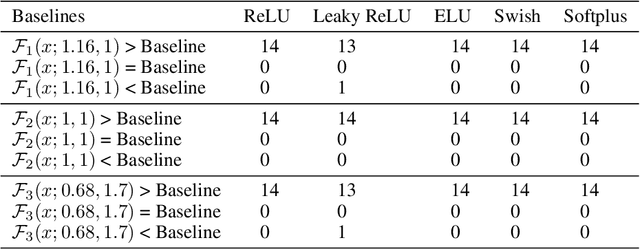
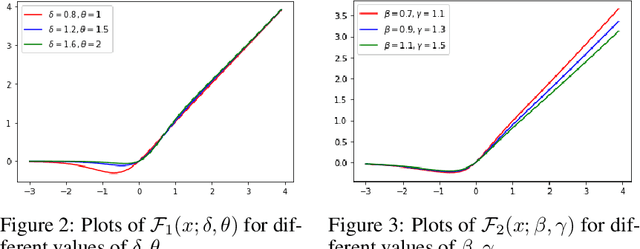
Activation functions play a pivotal role in the function learning using neural networks. The non-linearity in the learned function is achieved by repeated use of the activation function. Over the years, numerous activation functions have been proposed to improve accuracy in several tasks. Basic functions like ReLU, Sigmoid, Tanh, or Softplus have been favorite among the deep learning community because of their simplicity. In recent years, several novel activation functions arising from these basic functions have been proposed, which have improved accuracy in some challenging datasets. We propose a five hyper-parameters family of activation functions, namely EIS, defined as, \[ \frac{x(\ln(1+e^x))^\alpha}{\sqrt{\beta+\gamma x^2}+\delta e^{-\theta x}}. \] We show examples of activation functions from the EIS family which outperform widely used activation functions on some well known datasets and models. For example, $\frac{x\ln(1+e^x)}{x+1.16e^{-x}}$ beats ReLU by 0.89\% in DenseNet-169, 0.24\% in Inception V3 in CIFAR100 dataset while 1.13\% in Inception V3, 0.13\% in DenseNet-169, 0.94\% in SimpleNet model in CIFAR10 dataset. Also, $\frac{x\ln(1+e^x)}{\sqrt{1+x^2}}$ beats ReLU by 1.68\% in DenseNet-169, 0.30\% in Inception V3 in CIFAR100 dataset while 1.0\% in Inception V3, 0.15\% in DenseNet-169, 1.13\% in SimpleNet model in CIFAR10 dataset.