 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMU: smooth activation function for deep networks using smoothing maximum technique
Nov 08, 2021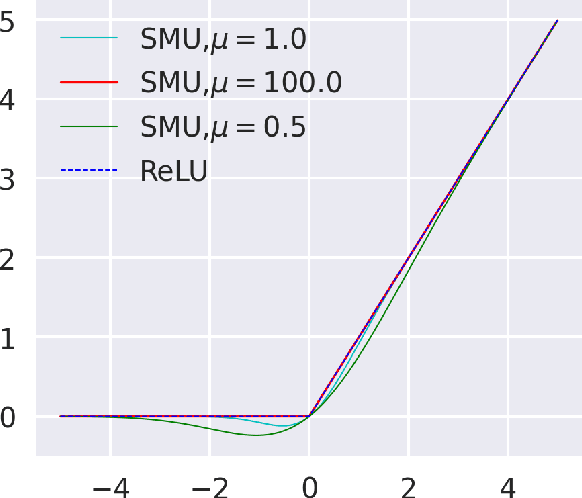

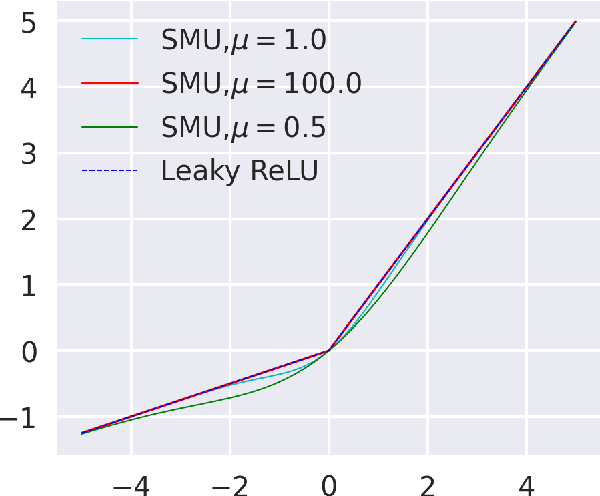
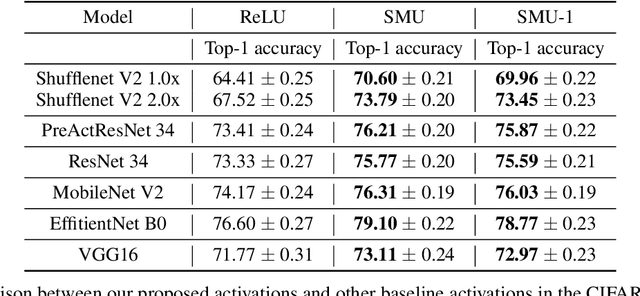
Deep learning researchers have a keen interest in proposing two new novel activation functions which can boost network performance. A good choice of activation function can have significant consequences in improving network performance. A handcrafted activation is the most common choice in neural network models. ReLU is the most common choice in the deep learning community due to its simplicity though ReLU has some serious drawbacks. In this paper, we have proposed a new novel activation function based on approximation of known activation functions like Leaky ReLU, and we call this function Smooth Maximum Unit (SMU). Replacing ReLU by SMU, we have got 6.22% improvement in the CIFAR100 dataset with the ShuffleNet V2 model.
SAU: Smooth activation function using convolution with approximate identities
Sep 27, 2021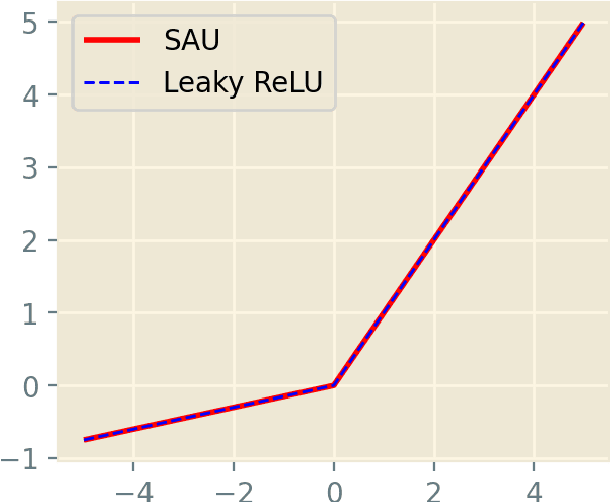
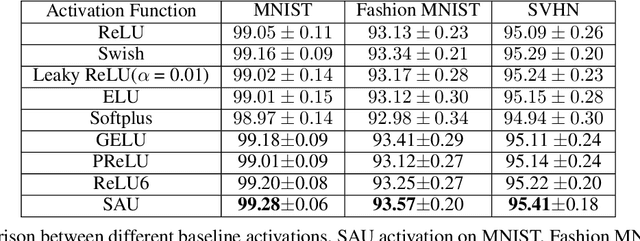
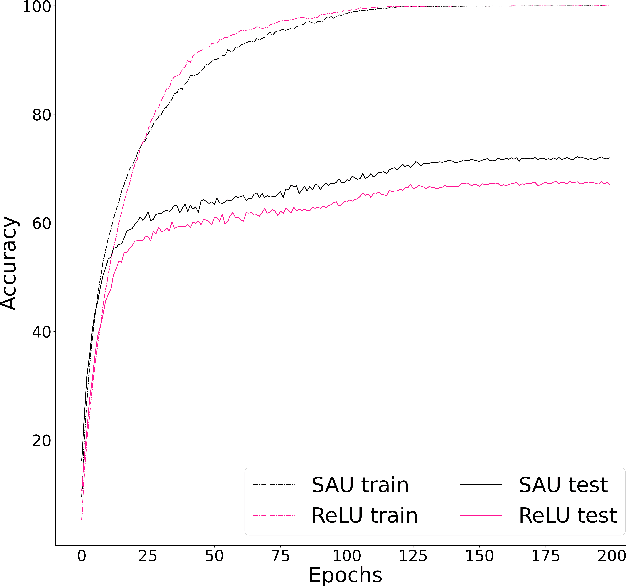

Well-known activation functions like ReLU or Leaky ReLU are non-differentiable at the origin. Over the years, many smooth approximations of ReLU have been proposed using various smoothing techniques. We propose new smooth approximations of a non-differentiable activation function by convolving it with approximate identities. In particular, we present smooth approximations of Leaky ReLU and show that they outperform several well-known activation functions in various datasets and models. We call this function Smooth Activation Unit (SAU). Replacing ReLU by SAU, we get 5.12% improvement with ShuffleNet V2 (2.0x) model on CIFAR100 dataset.
ErfAct and PSerf: Non-monotonic smooth trainable Activation Functions
Sep 19, 2021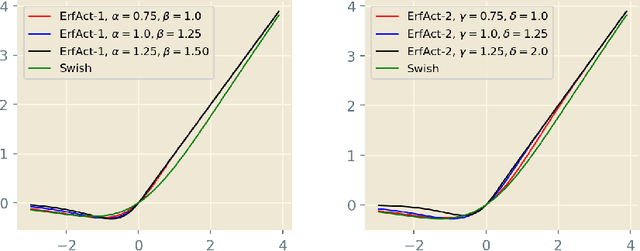

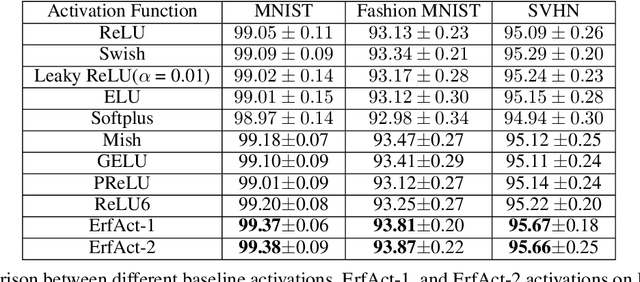
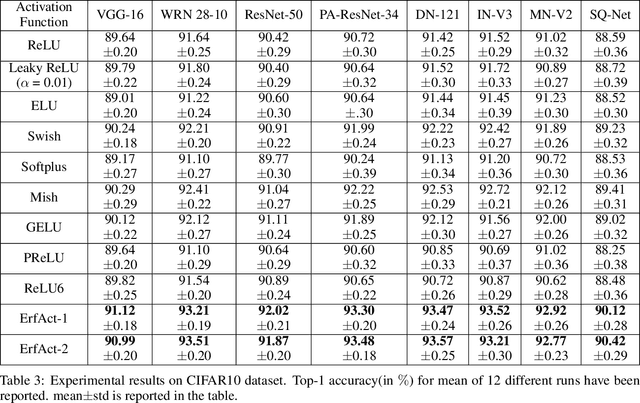
An activation function is a crucial component of a neural network that introduces non-linearity in the network. The state-of-the-art performance of a neural network depends on the perfect choice of an activation function. We propose two novel non-monotonic smooth trainable activation functions, called ErfAct and PSerf. Experiments suggest that the proposed functions improve the network performance significantly compared to the widely used activations like ReLU, Swish, and Mish. Replacing ReLU by ErfAct and PSerf, we have 5.21% and 5.04% improvement for top-1 accuracy on PreactResNet-34 network in CIFAR100 dataset, 2.58% and 2.76% improvement for top-1 accuracy on PreactResNet-34 network in CIFAR10 dataset, 1.0%, and 1.0% improvement on mean average precision (mAP) on SSD300 model in Pascal VOC dataset.
Orthogonal-Padé Activation Functions: Trainable Activation functions for smooth and faster convergence in deep networks
Jun 17, 2021

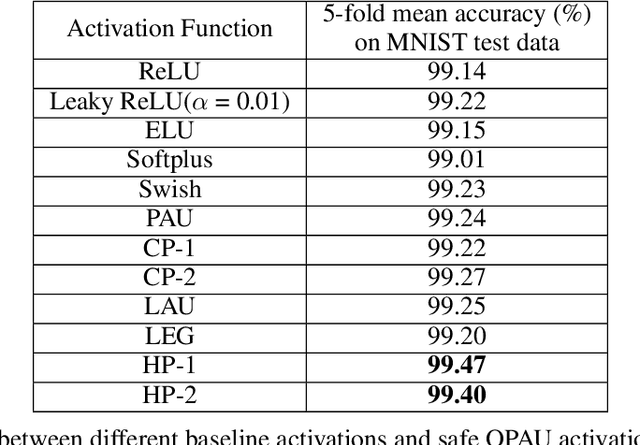
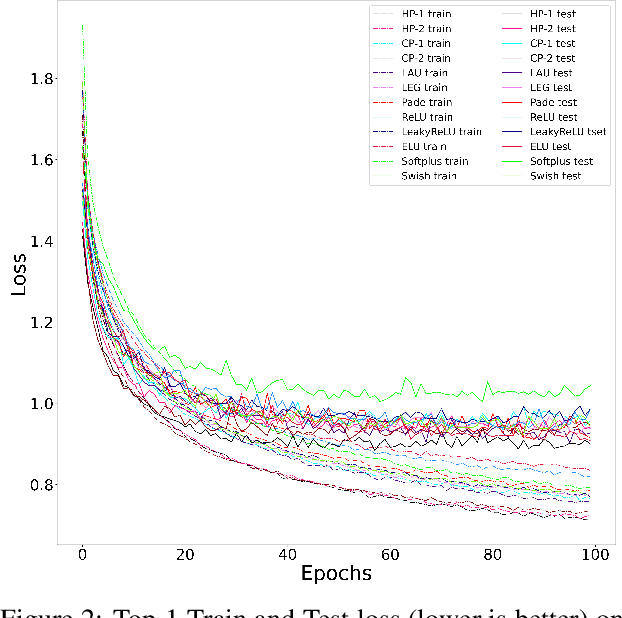
We have proposed orthogonal-Pad\'e activation functions, which are trainable activation functions and show that they have faster learning capability and improves the accuracy in standard deep learning datasets and models. Based on our experiments, we have found two best candidates out of six orthogonal-Pad\'e activations, which we call safe Hermite-Pade (HP) activation functions, namely HP-1 and HP-2. When compared to ReLU, HP-1 and HP-2 has an increment in top-1 accuracy by 5.06% and 4.63% respectively in PreActResNet-34, by 3.02% and 2.75% respectively in MobileNet V2 model on CIFAR100 dataset while on CIFAR10 dataset top-1 accuracy increases by 2.02% and 1.78% respectively in PreActResNet-34, by 2.24% and 2.06% respectively in LeNet, by 2.15% and 2.03% respectively in Efficientnet B0.
EIS -- a family of activation functions combining Exponential, ISRU, and Softplus
Oct 12, 2020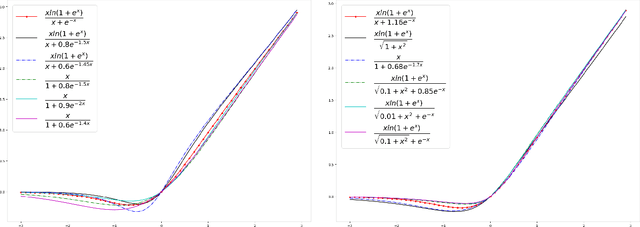
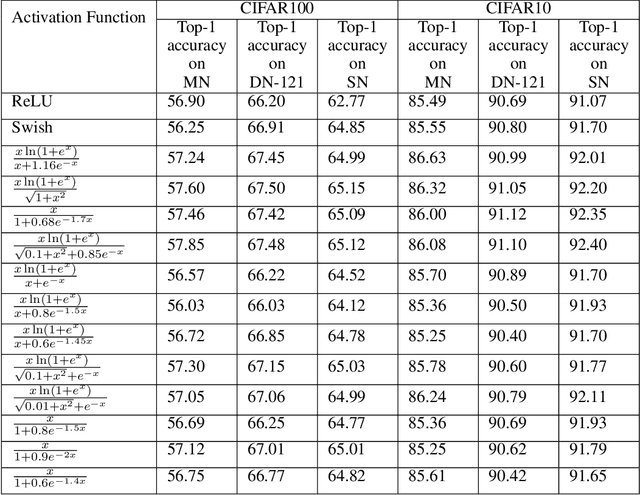
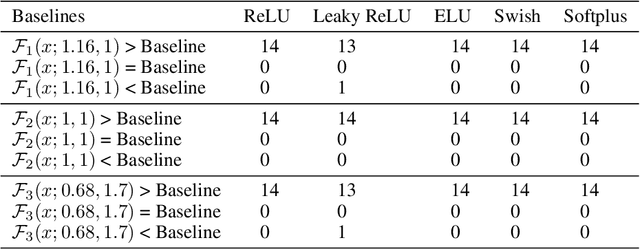
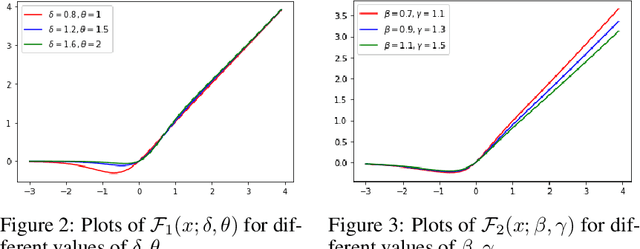
Activation functions play a pivotal role in the function learning using neural networks. The non-linearity in the learned function is achieved by repeated use of the activation function. Over the years, numerous activation functions have been proposed to improve accuracy in several tasks. Basic functions like ReLU, Sigmoid, Tanh, or Softplus have been favorite among the deep learning community because of their simplicity. In recent years, several novel activation functions arising from these basic functions have been proposed, which have improved accuracy in some challenging datasets. We propose a five hyper-parameters family of activation functions, namely EIS, defined as, \[ \frac{x(\ln(1+e^x))^\alpha}{\sqrt{\beta+\gamma x^2}+\delta e^{-\theta x}}. \] We show examples of activation functions from the EIS family which outperform widely used activation functions on some well known datasets and models. For example, $\frac{x\ln(1+e^x)}{x+1.16e^{-x}}$ beats ReLU by 0.89\% in DenseNet-169, 0.24\% in Inception V3 in CIFAR100 dataset while 1.13\% in Inception V3, 0.13\% in DenseNet-169, 0.94\% in SimpleNet model in CIFAR10 dataset. Also, $\frac{x\ln(1+e^x)}{\sqrt{1+x^2}}$ beats ReLU by 1.68\% in DenseNet-169, 0.30\% in Inception V3 in CIFAR100 dataset while 1.0\% in Inception V3, 0.15\% in DenseNet-169, 1.13\% in SimpleNet model in CIFAR10 dataset.
TanhSoft -- a family of activation functions combining Tanh and Softplus
Sep 08, 2020



Deep learning at its core, contains functions that are composition of a linear transformation with a non-linear function known as activation function. In past few years, there is an increasing interest in construction of novel activation functions resulting in better learning. In this work, we propose a family of novel activation functions, namely TanhSoft, with four undetermined hyper-parameters of the form tanh({\alpha}x+{\beta}e^{{\gamma}x})ln({\delta}+e^x) and tune these hyper-parameters to obtain activation functions which are shown to outperform several well known activation functions. For instance, replacing ReLU with xtanh(0.6e^x)improves top-1 classification accuracy on CIFAR-10 by 0.46% for DenseNet-169 and 0.7% for Inception-v3 while with tanh(0.87x)ln(1 +e^x) top-1 classification accuracy on CIFAR-100 improves by 1.24% for DenseNet-169 and 2.57% for SimpleNet model.