 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal-Padé Activation Functions: Trainable Activation functions for smooth and faster convergence in deep networks
Paper and Code
Jun 17, 2021

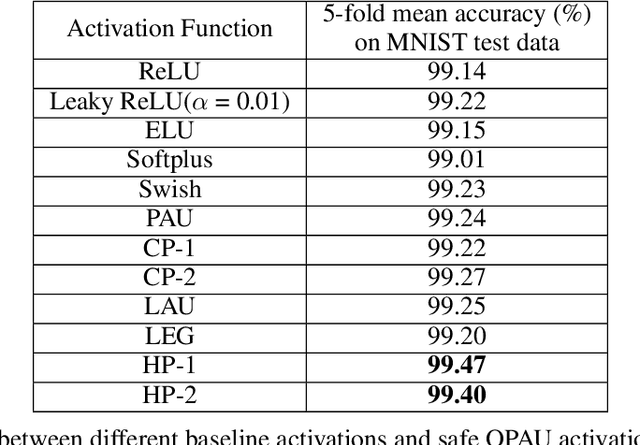
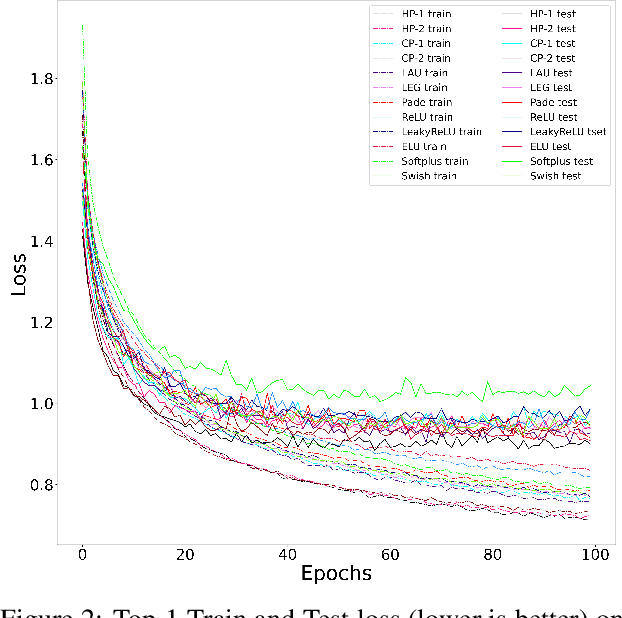
We have proposed orthogonal-Pad\'e activation functions, which are trainable activation functions and show that they have faster learning capability and improves the accuracy in standard deep learning datasets and models. Based on our experiments, we have found two best candidates out of six orthogonal-Pad\'e activations, which we call safe Hermite-Pade (HP) activation functions, namely HP-1 and HP-2. When compared to ReLU, HP-1 and HP-2 has an increment in top-1 accuracy by 5.06% and 4.63% respectively in PreActResNet-34, by 3.02% and 2.75% respectively in MobileNet V2 model on CIFAR100 dataset while on CIFAR10 dataset top-1 accuracy increases by 2.02% and 1.78% respectively in PreActResNet-34, by 2.24% and 2.06% respectively in LeNet, by 2.15% and 2.03% respectively in Efficientnet B0.