Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMU: smooth activation function for deep networks using smoothing maximum technique
Paper and Code
Nov 08, 2021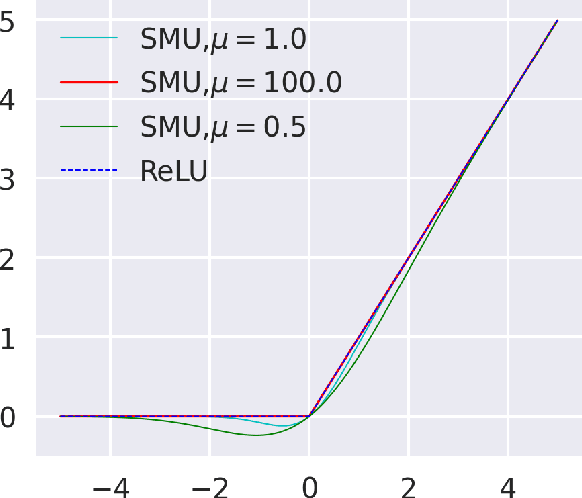

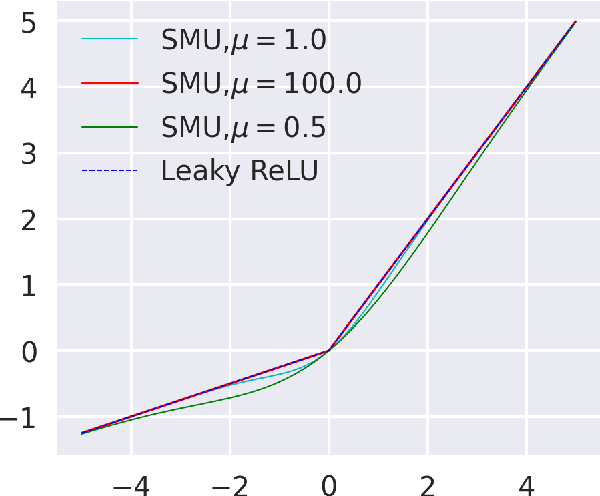
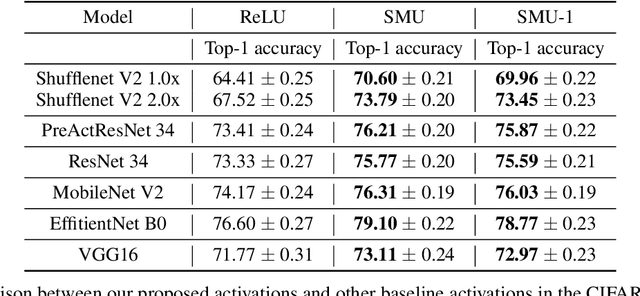
Deep learning researchers have a keen interest in proposing two new novel activation functions which can boost network performance. A good choice of activation function can have significant consequences in improving network performance. A handcrafted activation is the most common choice in neural network models. ReLU is the most common choice in the deep learning community due to its simplicity though ReLU has some serious drawbacks. In this paper, we have proposed a new novel activation function based on approximation of known activation functions like Leaky ReLU, and we call this function Smooth Maximum Unit (SMU). Replacing ReLU by SMU, we have got 6.22% improvement in the CIFAR100 dataset with the ShuffleNet V2 model.
* 7 pages
View paper on