 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Quality of Denoising Diffusion Models in Wasserstein Distance: Noisy Score and Optimal Bounds
Jun 11, 2025Generative modeling aims to produce new random examples from an unknown target distribution, given access to a finite collection of examples. Among the leading approaches, denoising diffusion probabilistic models (DDPMs) construct such examples by mapping a Brownian motion via a diffusion process driven by an estimated score function. In this work, we first provide empirical evidence that DDPMs are robust to constant-variance noise in the score evaluations. We then establish finite-sample guarantees in Wasserstein-2 distance that exhibit two key features: (i) they characterize and quantify the robustness of DDPMs to noisy score estimates, and (ii) they achieve faster convergence rates than previously known results. Furthermore, we observe that the obtained rates match those known in the Gaussian case, implying their optimality.
Parallelized Midpoint Randomization for Langevin Monte Carlo
Feb 23, 2024
We explore the sampling problem within the framework where parallel evaluations of the gradient of the log-density are feasible. Our investigation focuses on target distributions characterized by smooth and strongly log-concave densities. We revisit the parallelized randomized midpoint method and employ proof techniques recently developed for analyzing its purely sequential version. Leveraging these techniques, we derive upper bounds on the Wasserstein distance between the sampling and target densities. These bounds quantify the runtime improvement achieved by utilizing parallel processing units, which can be considerable.
Guaranteed Optimal Generative Modeling with Maximum Deviation from the Empirical Distribution
Jul 31, 2023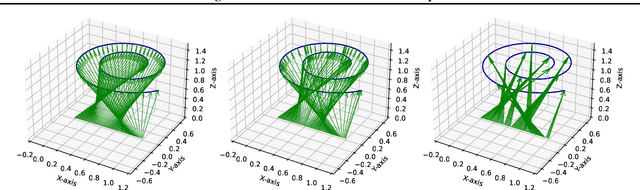
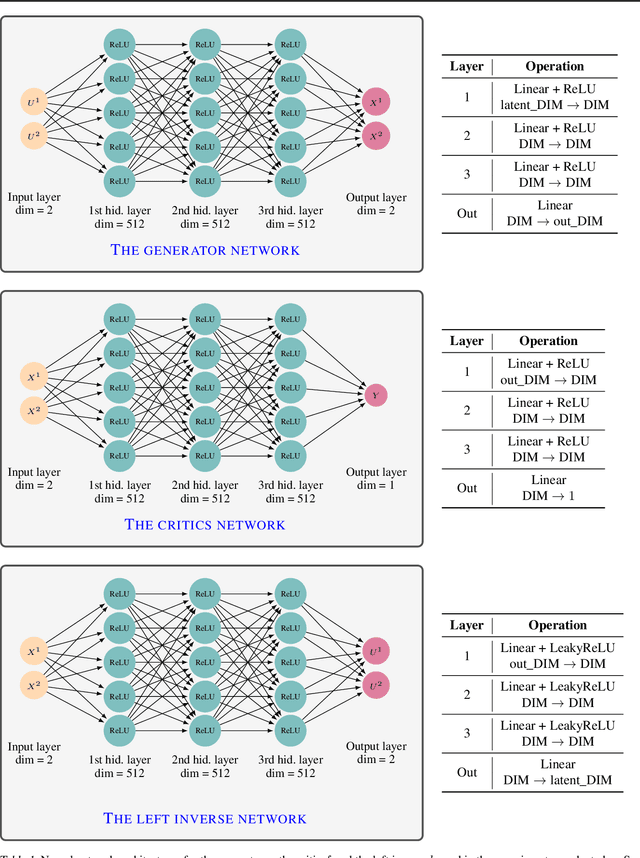

Generative modeling is a widely-used machine learning method with various applications in scientific and industrial fields. Its primary objective is to simulate new examples drawn from an unknown distribution given training data while ensuring diversity and avoiding replication of examples from the training data. This paper presents theoretical insights into training a generative model with two properties: (i) the error of replacing the true data-generating distribution with the trained data-generating distribution should optimally converge to zero as the sample size approaches infinity, and (ii) the trained data-generating distribution should be far enough from any distribution replicating examples in the training data. We provide non-asymptotic results in the form of finite sample risk bounds that quantify these properties and depend on relevant parameters such as sample size, the dimension of the ambient space, and the dimension of the latent space. Our results are applicable to general integral probability metrics used to quantify errors in probability distribution spaces, with the Wasserstein-$1$ distance being the central example. We also include numerical examples to illustrate our theoretical findings.
Langevin Monte Carlo for strongly log-concave distributions: Randomized midpoint revisited
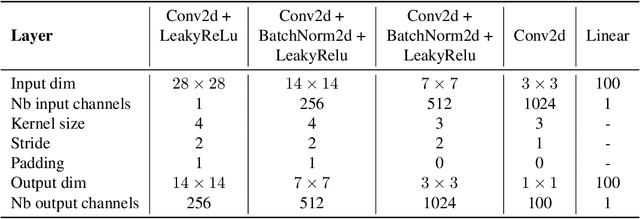
Jun 16, 2023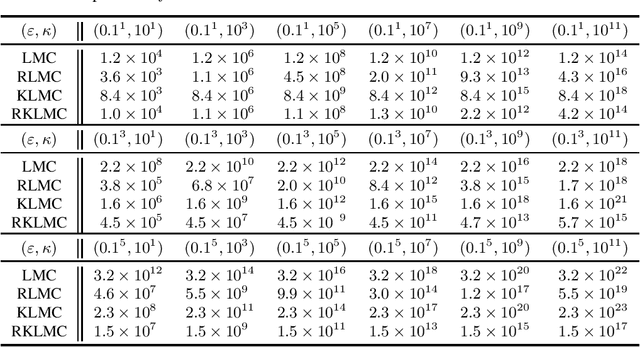
We revisit the problem of sampling from a target distribution that has a smooth strongly log-concave density everywhere in $\mathbb R^p$. In this context, if no additional density information is available, the randomized midpoint discretization for the kinetic Langevin diffusion is known to be the most scalable method in high dimensions with large condition numbers. Our main result is a nonasymptotic and easy to compute upper bound on the Wasserstein-2 error of this method. To provide a more thorough explanation of our method for establishing the computable upper bound, we conduct an analysis of the midpoint discretization for the vanilla Langevin process. This analysis helps to clarify the underlying principles and provides valuable insights that we use to establish an improved upper bound for the kinetic Langevin process with the midpoint discretization. Furthermore, by applying these techniques we establish new guarantees for the kinetic Langevin process with Euler discretization, which have a better dependence on the condition number than existing upper bounds.
Matching Map Recovery with an Unknown Number of Outliers
Oct 24, 2022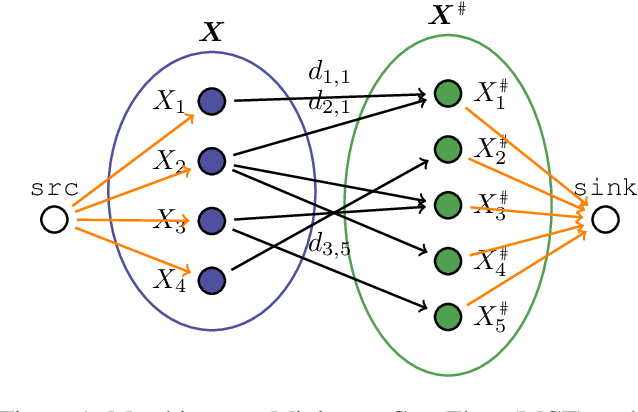
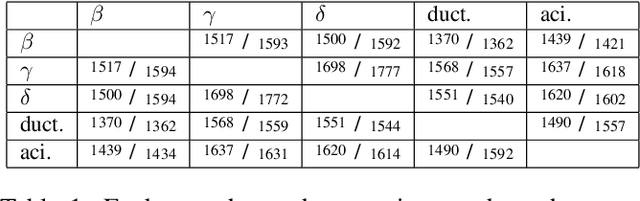

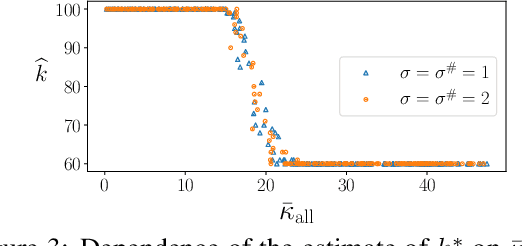
We consider the problem of finding the matching map between two sets of $d$-dimensional noisy feature-vectors. The distinctive feature of our setting is that we do not assume that all the vectors of the first set have their corresponding vector in the second set. If $n$ and $m$ are the sizes of these two sets, we assume that the matching map that should be recovered is defined on a subset of unknown cardinality $k^*\le \min(n,m)$. We show that, in the high-dimensional setting, if the signal-to-noise ratio is larger than $5(d\log(4nm/\alpha))^{1/4}$, then the true matching map can be recovered with probability $1-\alpha$. Interestingly, this threshold does not depend on $k^*$ and is the same as the one obtained in prior work in the case of $k = \min(n,m)$. The procedure for which the aforementioned property is proved is obtained by a data-driven selection among candidate mappings $\{\hat\pi_k:k\in[\min(n,m)]\}$. Each $\hat\pi_k$ minimizes the sum of squares of distances between two sets of size $k$. The resulting optimization problem can be formulated as a minimum-cost flow problem, and thus solved efficiently. Finally, we report the results of numerical experiments on both synthetic and real-world data that illustrate our theoretical results and provide further insight into the properties of the algorithms studied in this work.
Optimal detection of the feature matching map in presence of noise and outliers
Jun 13, 2021
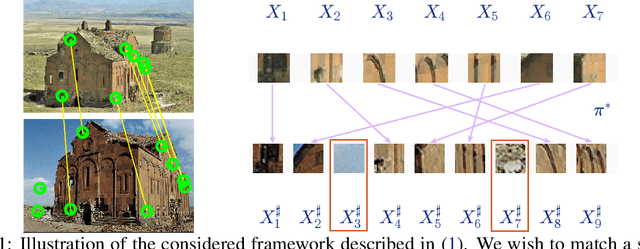
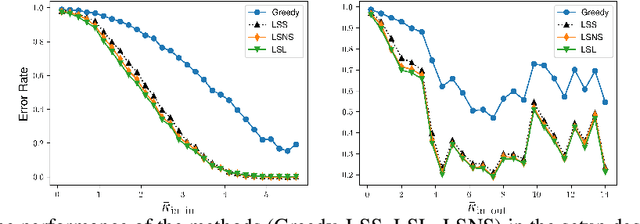
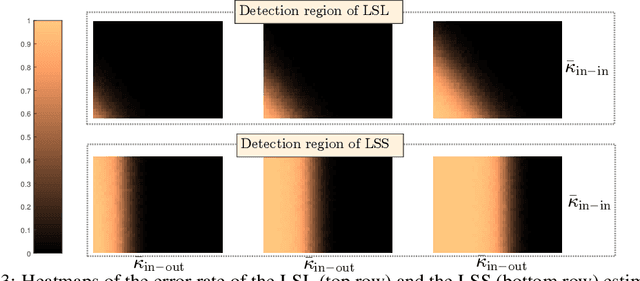
We consider the problem of finding the matching map between two sets of $d$ dimensional vectors from noisy observations, where the second set contains outliers. The matching map is then an injection, which can be consistently estimated only if the vectors of the second set are well separated. The main result shows that, in the high-dimensional setting, a detection region of unknown injection can be characterized by the sets of vectors for which the inlier-inlier distance is of order at least $d^{1/4}$ and the inlier-outlier distance is of order at least $d^{1/2}$. These rates are achieved using the estimated matching minimizing the sum of logarithms of distances between matched pairs of points. We also prove lower bounds establishing optimality of these rates. Finally, we report results of numerical experiments on both synthetic and real world data that illustrate our theoretical results and provide further insight into the properties of the estimators studied in this work.
Statistical guarantees for generative models without domination
Oct 19, 2020
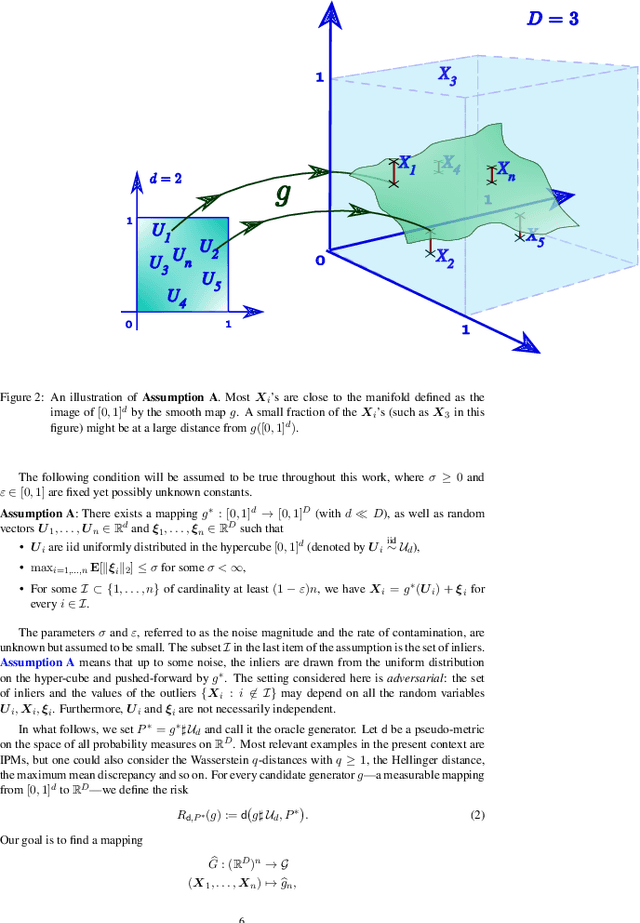
In this paper, we introduce a convenient framework for studying (adversarial) generative models from a statistical perspective. It consists in modeling the generative device as a smooth transformation of the unit hypercube of a dimension that is much smaller than that of the ambient space and measuring the quality of the generative model by means of an integral probability metric. In the particular case of integral probability metric defined through a smoothness class, we establish a risk bound quantifying the role of various parameters. In particular, it clearly shows the impact of dimension reduction on the error of the generative model.