 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuaranteed Optimal Generative Modeling with Maximum Deviation from the Empirical Distribution
Jul 31, 2023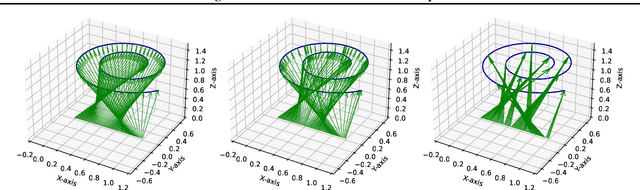
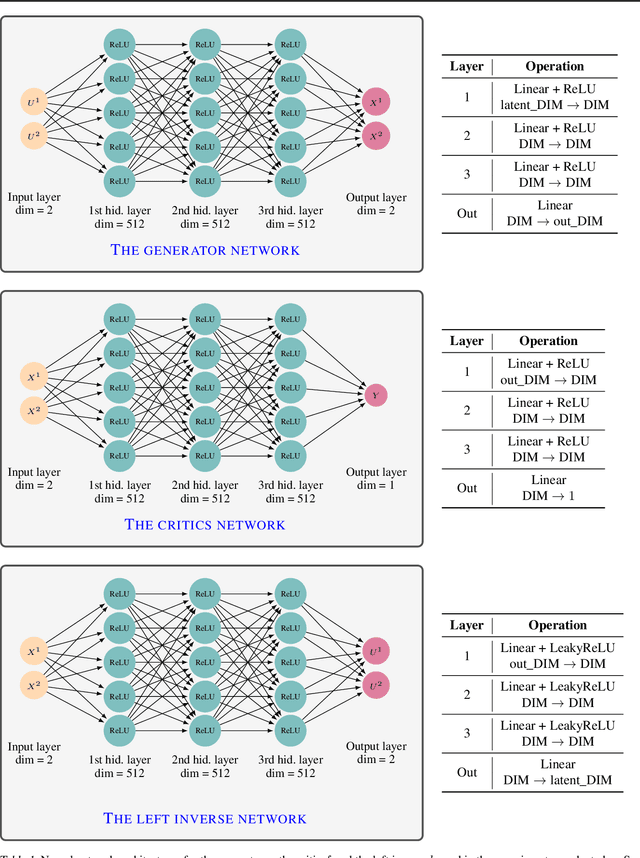

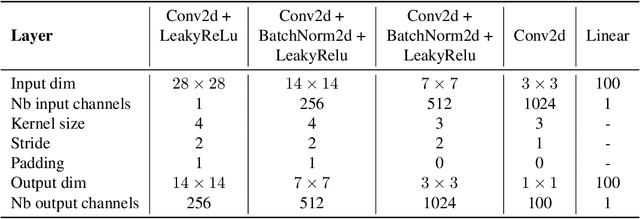
Generative modeling is a widely-used machine learning method with various applications in scientific and industrial fields. Its primary objective is to simulate new examples drawn from an unknown distribution given training data while ensuring diversity and avoiding replication of examples from the training data. This paper presents theoretical insights into training a generative model with two properties: (i) the error of replacing the true data-generating distribution with the trained data-generating distribution should optimally converge to zero as the sample size approaches infinity, and (ii) the trained data-generating distribution should be far enough from any distribution replicating examples in the training data. We provide non-asymptotic results in the form of finite sample risk bounds that quantify these properties and depend on relevant parameters such as sample size, the dimension of the ambient space, and the dimension of the latent space. Our results are applicable to general integral probability metrics used to quantify errors in probability distribution spaces, with the Wasserstein-$1$ distance being the central example. We also include numerical examples to illustrate our theoretical findings.
Matching Map Recovery with an Unknown Number of Outliers
Oct 24, 2022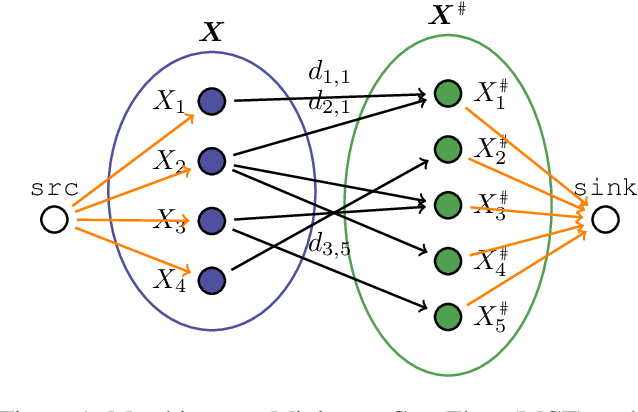
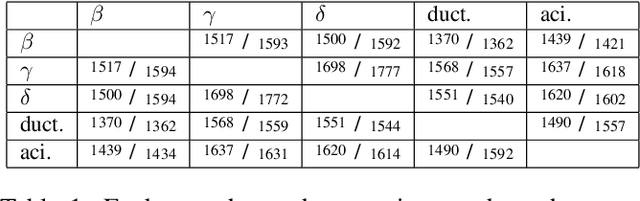

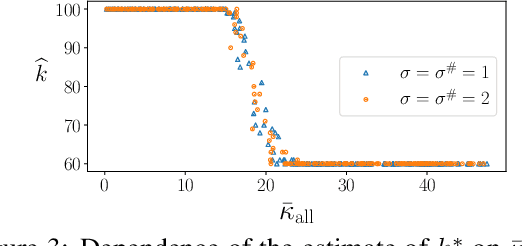
We consider the problem of finding the matching map between two sets of $d$-dimensional noisy feature-vectors. The distinctive feature of our setting is that we do not assume that all the vectors of the first set have their corresponding vector in the second set. If $n$ and $m$ are the sizes of these two sets, we assume that the matching map that should be recovered is defined on a subset of unknown cardinality $k^*\le \min(n,m)$. We show that, in the high-dimensional setting, if the signal-to-noise ratio is larger than $5(d\log(4nm/\alpha))^{1/4}$, then the true matching map can be recovered with probability $1-\alpha$. Interestingly, this threshold does not depend on $k^*$ and is the same as the one obtained in prior work in the case of $k = \min(n,m)$. The procedure for which the aforementioned property is proved is obtained by a data-driven selection among candidate mappings $\{\hat\pi_k:k\in[\min(n,m)]\}$. Each $\hat\pi_k$ minimizes the sum of squares of distances between two sets of size $k$. The resulting optimization problem can be formulated as a minimum-cost flow problem, and thus solved efficiently. Finally, we report the results of numerical experiments on both synthetic and real-world data that illustrate our theoretical results and provide further insight into the properties of the algorithms studied in this work.