 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Disparity while Maximizing Reward: Tight Anytime Guarantee for Improving Bandits
Aug 19, 2022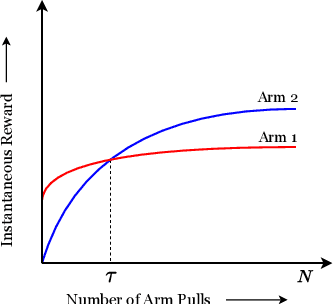
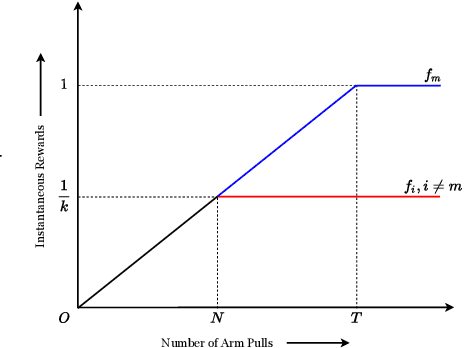
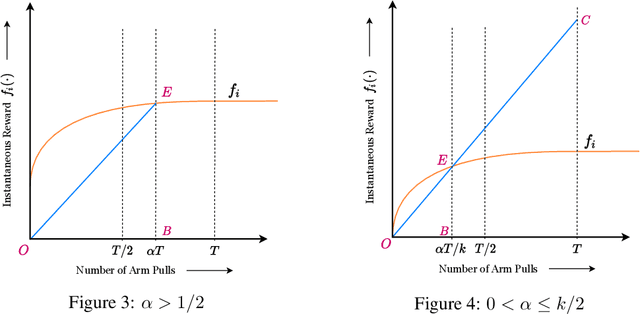
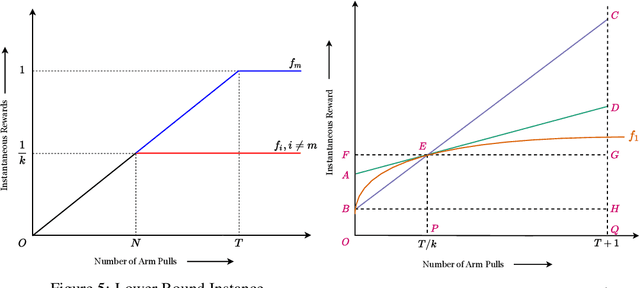
We study the Improving Multi-Armed Bandit (IMAB) problem, where the reward obtained from an arm increases with the number of pulls it receives. This model provides an elegant abstraction for many real-world problems in domains such as education and employment, where decisions about the distribution of opportunities can affect the future capabilities of communities and the disparity between them. A decision-maker in such settings must consider the impact of her decisions on future rewards in addition to the standard objective of maximizing her cumulative reward at any time. In many of these applications, the time horizon is unknown to the decision-maker beforehand, which motivates the study of the IMAB problem in the technically more challenging horizon-unaware setting. We study the tension that arises between two seemingly conflicting objectives in the horizon-unaware setting: a) maximizing the cumulative reward at any time based on current rewards of the arms, and b) ensuring that arms with better long-term rewards get sufficient opportunities even if they initially have low rewards. We show that, surprisingly, the two objectives are aligned with each other in this setting. Our main contribution is an anytime algorithm for the IMAB problem that achieves the best possible cumulative reward while ensuring that the arms reach their true potential given sufficient time. Our algorithm mitigates the initial disparity due to lack of opportunity and continues pulling an arm till it stops improving. We prove the optimality of our algorithm by showing that a) any algorithm for the IMAB problem, no matter how utilitarian, must suffer $\Omega(T)$ policy regret and $\Omega(k)$ competitive ratio with respect to the optimal offline policy, and b) the competitive ratio of our algorithm is $O(k)$.
Fairness and Welfare Quantification for Regret in Multi-Armed Bandits
May 27, 2022We extend the notion of regret with a welfarist perspective. Focussing on the classic multi-armed bandit (MAB) framework, the current work quantifies the performance of bandit algorithms by applying a fundamental welfare function, namely the Nash social welfare (NSW) function. This corresponds to equating algorithm's performance to the geometric mean of its expected rewards and leads us to the study of Nash regret, defined as the difference between the -- a priori unknown -- optimal mean (among the arms) and the algorithm's performance. Since NSW is known to satisfy fairness axioms, our approach complements the utilitarian considerations of average (cumulative) regret, wherein the algorithm is evaluated via the arithmetic mean of its expected rewards. This work develops an algorithm that, given the horizon of play $T$, achieves a Nash regret of $O \left( \sqrt{\frac{{k \log T}}{T}} \right)$, here $k$ denotes the number of arms in the MAB instance. Since, for any algorithm, the Nash regret is at least as much as its average regret (the AM-GM inequality), the known lower bound on average regret holds for Nash regret as well. Therefore, our Nash regret guarantee is essentially tight. In addition, we develop an anytime algorithm with a Nash regret guarantee of $O \left( \sqrt{\frac{{k\log T}}{T}} \log T \right)$.
Approximation Algorithms for ROUND-UFP and ROUND-SAP
Feb 07, 2022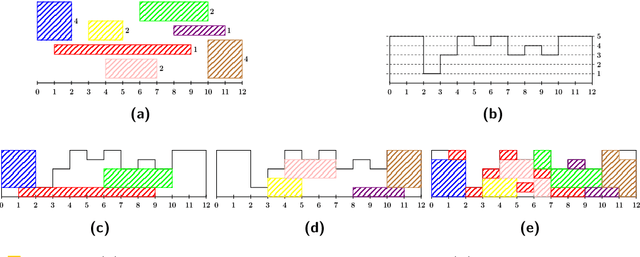

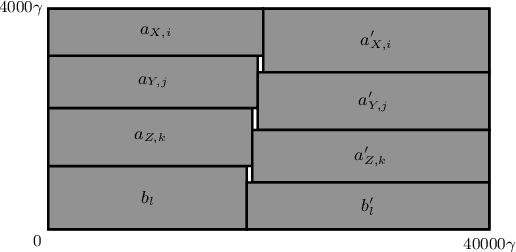
We study ROUND-UFP and ROUND-SAP, two generalizations of the classical BIN PACKING problem that correspond to the unsplittable flow problem on a path (UFP) and the storage allocation problem (SAP), respectively. We are given a path with capacities on its edges and a set of tasks where for each task we are given a demand and a subpath. In ROUND-UFP, the goal is to find a packing of all tasks into a minimum number of copies (rounds) of the given path such that for each copy, the total demand of tasks on any edge does not exceed the capacity of the respective edge. In ROUND-SAP, the tasks are considered to be rectangles and the goal is to find a non-overlapping packing of these rectangles into a minimum number of rounds such that all rectangles lie completely below the capacity profile of the edges. We show that in contrast to BIN PACKING, both the problems do not admit an asymptotic polynomial-time approximation scheme (APTAS), even when all edge capacities are equal. However, for this setting, we obtain asymptotic $(2+\varepsilon)$-approximations for both problems. For the general case, we obtain an $O(\log\log n)$-approximation algorithm and an $O(\log\log\frac{1}{\delta})$-approximation under $(1+\delta)$-resource augmentation for both problems. For the intermediate setting of the no bottleneck assumption (i.e., the maximum task demand is at most the minimum edge capacity), we obtain absolute $12$- and asymptotic $(16+\varepsilon)$-approximation algorithms for ROUND-UFP and ROUND-SAP, respectively.
Streaming Algorithms for Stochastic Multi-armed Bandits
Dec 09, 2020
We study the Stochastic Multi-armed Bandit problem under bounded arm-memory. In this setting, the arms arrive in a stream, and the number of arms that can be stored in the memory at any time, is bounded. The decision-maker can only pull arms that are present in the memory. We address the problem from the perspective of two standard objectives: 1) regret minimization, and 2) best-arm identification. For regret minimization, we settle an important open question by showing an almost tight hardness. We show {\Omega}(T^{2/3}) cumulative regret in expectation for arm-memory size of (n-1), where n is the number of arms. For best-arm identification, we study two algorithms. First, we present an O(r) arm-memory r-round adaptive streaming algorithm to find an {\epsilon}-best arm. In r-round adaptive streaming algorithm for best-arm identification, the arm pulls in each round are decided based on the observed outcomes in the earlier rounds. The best-arm is the output at the end of r rounds. The upper bound on the sample complexity of our algorithm matches with the lower bound for any r-round adaptive streaming algorithm. Secondly, we present a heuristic to find the {\epsilon}-best arm with optimal sample complexity, by storing only one extra arm in the memory.