 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Era: Intelligent Tutoring Systems Will Transform Online Learning for Millions
Mar 03, 2022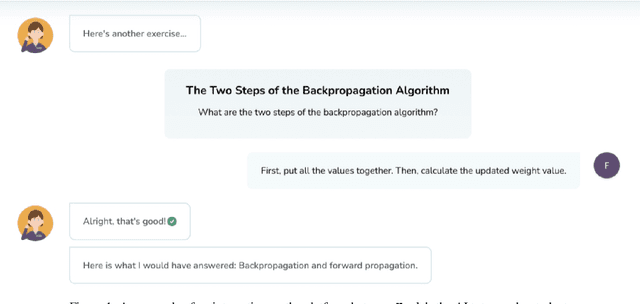
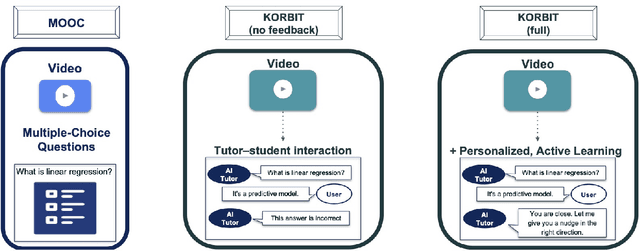
Despite artificial intelligence (AI) having transformed major aspects of our society, less than a fraction of its potential has been explored, let alone deployed, for education. AI-powered learning can provide millions of learners with a highly personalized, active and practical learning experience, which is key to successful learning. This is especially relevant in the context of online learning platforms. In this paper, we present the results of a comparative head-to-head study on learning outcomes for two popular online learning platforms (n=199 participants): A MOOC platform following a traditional model delivering content using lecture videos and multiple-choice quizzes, and the Korbit learning platform providing a highly personalized, active and practical learning experience. We observe a huge and statistically significant increase in the learning outcomes, with students on the Korbit platform providing full feedback resulting in higher course completion rates and achieving learning gains 2 to 2.5 times higher than both students on the MOOC platform and students in a control group who don't receive personalized feedback on the Korbit platform. The results demonstrate the tremendous impact that can be achieved with a personalized, active learning AI-powered system. Making this technology and learning experience available to millions of learners around the world will represent a significant leap forward towards the democratization of education.
Comparative Study of Learning Outcomes for Online Learning Platforms
Apr 15, 2021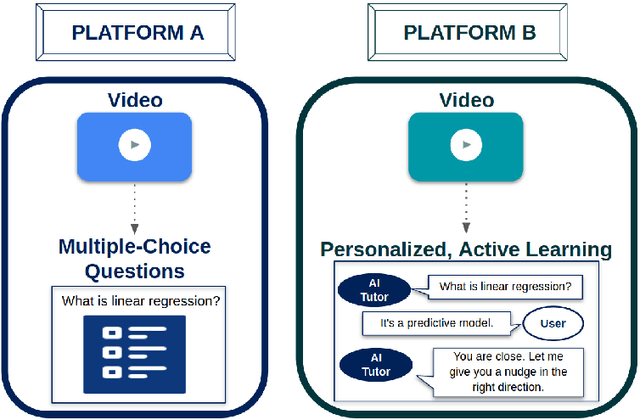

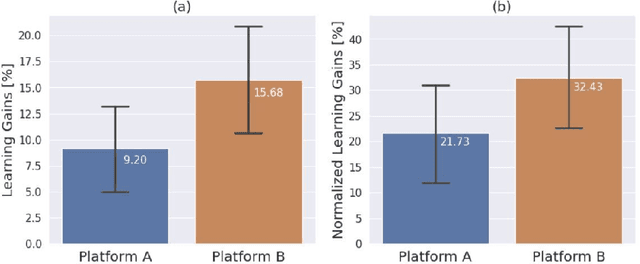
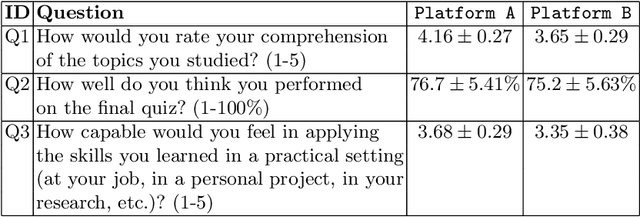
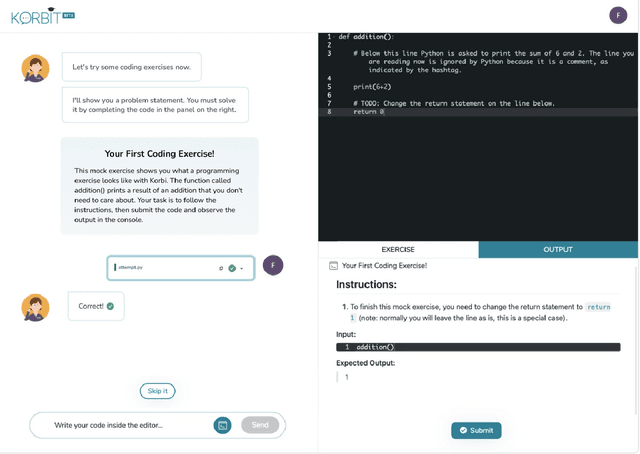
Personalization and active learning are key aspects to successful learning. These aspects are important to address in intelligent educational applications, as they help systems to adapt and close the gap between students with varying abilities, which becomes increasingly important in the context of online and distance learning. We run a comparative head-to-head study of learning outcomes for two popular online learning platforms: Platform A, which follows a traditional model delivering content over a series of lecture videos and multiple-choice quizzes, and Platform B, which creates a personalized learning environment and provides problem-solving exercises and personalized feedback. We report on the results of our study using pre- and post-assessment quizzes with participants taking courses on an introductory data science topic on two platforms. We observe a statistically significant increase in the learning outcomes on Platform B, highlighting the impact of well-designed and well-engineered technology supporting active learning and problem-based learning in online education. Moreover, the results of the self-assessment questionnaire, where participants reported on perceived learning gains, suggest that participants using Platform B improve their metacognition.
Latent Variable Modelling with Hyperbolic Normalizing Flows
Feb 18, 2020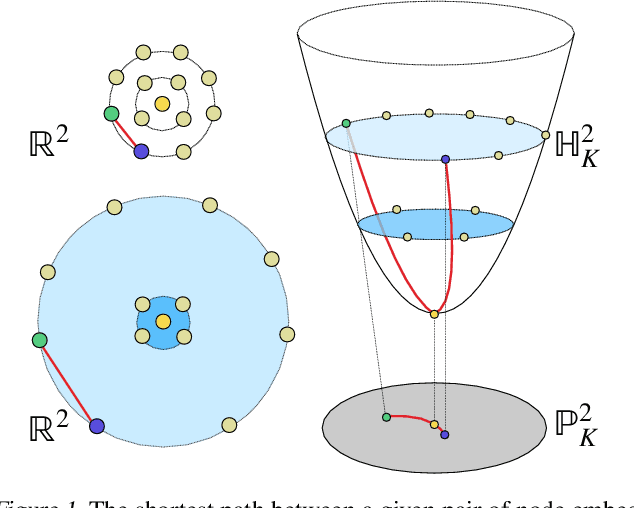
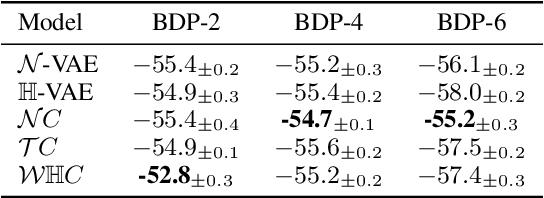
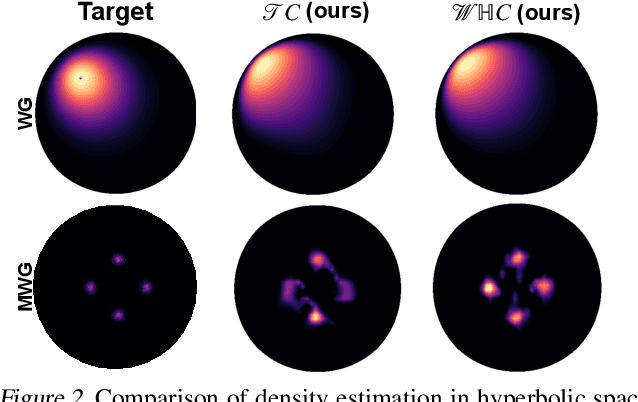

The choice of approximate posterior distributions plays a central role in stochastic variational inference (SVI). One effective solution is the use of normalizing flows \cut{defined on Euclidean spaces} to construct flexible posterior distributions. However, one key limitation of existing normalizing flows is that they are restricted to the Euclidean space and are ill-equipped to model data with an underlying hierarchical structure. To address this fundamental limitation, we present the first extension of normalizing flows to hyperbolic spaces. We first elevate normalizing flows to hyperbolic spaces using coupling transforms defined on the tangent bundle, termed Tangent Coupling ($\mathcal{TC}$). We further introduce Wrapped Hyperboloid Coupling ($\mathcal{W}\mathbb{H}C$), a fully invertible and learnable transformation that explicitly utilizes the geometric structure of hyperbolic spaces, allowing for expressive posteriors while being efficient to sample from. We demonstrate the efficacy of our novel normalizing flow over hyperbolic VAEs and Euclidean normalizing flows. Our approach achieves improved performance on density estimation, as well as reconstruction of real-world graph data, which exhibit a hierarchical structure. Finally, we show that our approach can be used to power a generative model over hierarchical data using hyperbolic latent variables.
Improving Exploration in Soft-Actor-Critic with Normalizing Flows Policies
Jun 06, 2019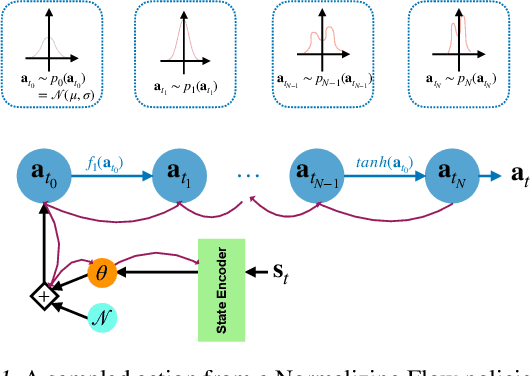
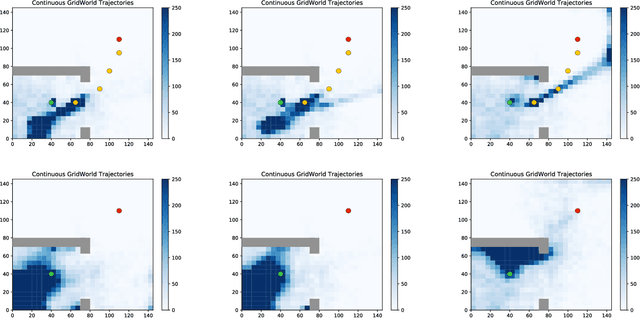
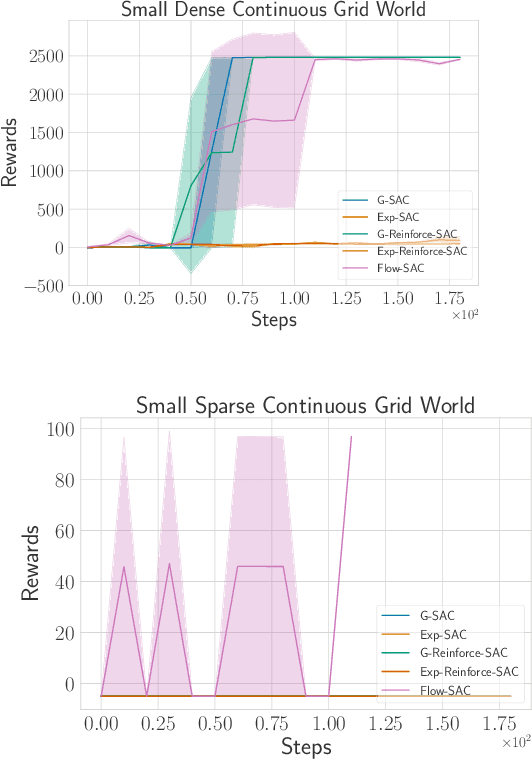
Deep Reinforcement Learning (DRL) algorithms for continuous action spaces are known to be brittle toward hyperparameters as well as \cut{being}sample inefficient. Soft Actor Critic (SAC) proposes an off-policy deep actor critic algorithm within the maximum entropy RL framework which offers greater stability and empirical gains. The choice of policy distribution, a factored Gaussian, is motivated by \cut{chosen due}its easy re-parametrization rather than its modeling power. We introduce Normalizing Flow policies within the SAC framework that learn more expressive classes of policies than simple factored Gaussians. \cut{We also present a series of stabilization tricks that enable effective training of these policies in the RL setting.}We show empirically on continuous grid world tasks that our approach increases stability and is better suited to difficult exploration in sparse reward settings.