 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OOD Generalization of Pre-trained Encoders via Aligned Embedding-Space Ensembles
Nov 20, 2024



The quality of self-supervised pre-trained embeddings on out-of-distribution (OOD) data is poor without fine-tuning. A straightforward and simple approach to improving the generalization of pre-trained representation to OOD data is the use of deep ensembles. However, obtaining an effective ensemble in the embedding space with only unlabeled data remains an unsolved problem. We first perform a theoretical analysis that reveals the relationship between individual hyperspherical embedding spaces in an ensemble. We then design a principled method to align these embedding spaces in an unsupervised manner. Experimental results on the MNIST dataset show that our embedding-space ensemble method improves pre-trained embedding quality on in-distribution and OOD data compared to single encoders.
Representation Extraction and Deep Neural Recommendation for Collaborative Filtering
Dec 09, 2020
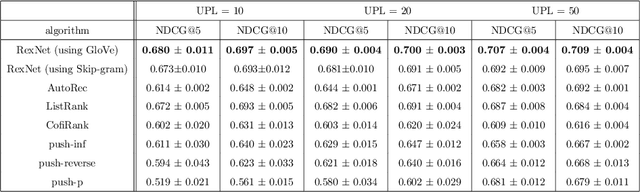
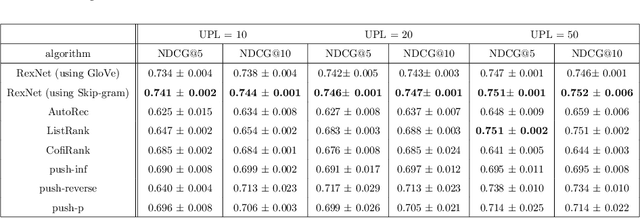
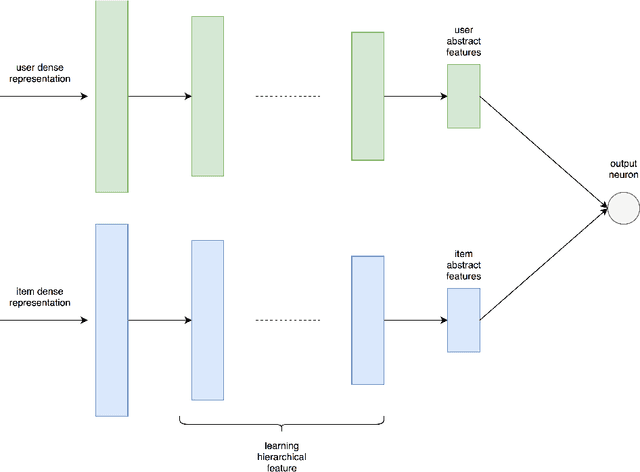
Many Deep Learning approaches solve complicated classification and regression problems by hierarchically constructing complex features from the raw input data. Although a few works have investigated the application of deep neural networks in recommendation domain, they mostly extract entity features by exploiting unstructured auxiliary data such as visual and textual information, and when it comes to using user-item rating matrix, feature extraction is done by using matrix factorization. As matrix factorization has some limitations, some works have been done to replace it with deep neural network. but these works either need to exploit unstructured data such item's reviews or images, or are specially designed to use implicit data and don't take user-item rating matrix into account. In this paper, we investigate the usage of novel representation learning algorithms to extract users and items representations from rating matrix, and offer a deep neural network for Collaborative Filtering. Our proposed approach is a modular algorithm consisted of two main phases: REpresentation eXtraction and a deep neural NETwork (RexNet). Using two joint and parallel neural networks in RexNet enables it to extract a hierarchy of features for each entity in order to predict the degree of interest of users to items. The resulted predictions are then used for the final recommendation. Unlike other deep learning recommendation approaches, RexNet is not dependent to unstructured auxiliary data such as visual and textual information, instead, it uses only the user-item rate matrix as its input. We evaluated RexNet in an extensive set of experiments against state of the art recommendation methods. The results show that RexNet significantly outperforms the baseline algorithms in a variety of data sets with different degrees of density.
U-CNNpred: A Universal CNN-based Predictor for Stock Markets
Nov 28, 2019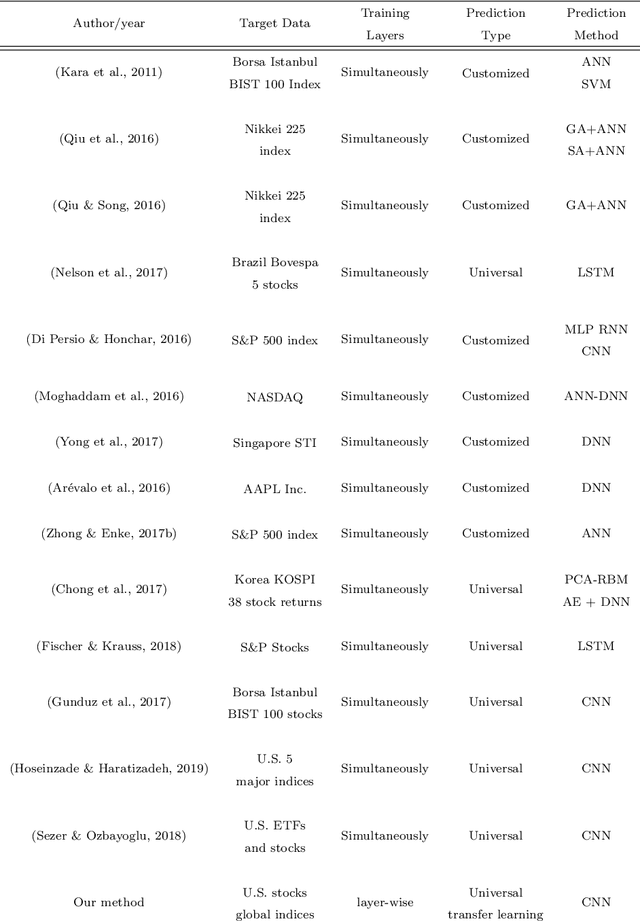
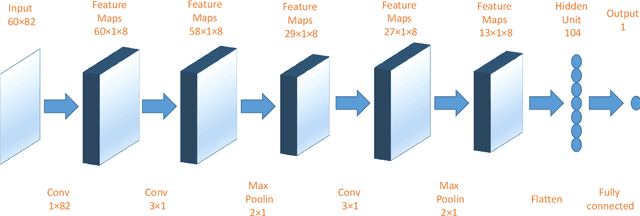
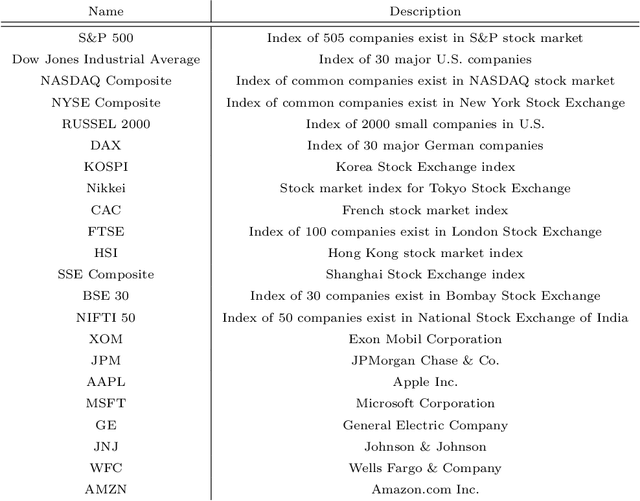
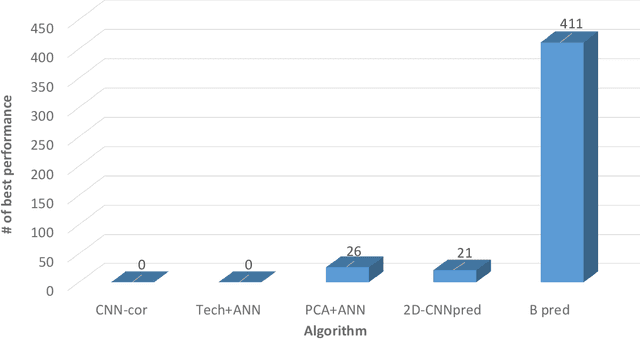
The performance of financial market prediction systems depends heavily on the quality of features it is using. While researchers have used various techniques for enhancing the stock specific features, less attention has been paid to extracting features that represent general mechanism of financial markets. In this paper, we investigate the importance of extracting such general features in stock market prediction domain and show how it can improve the performance of financial market prediction. We present a framework called U-CNNpred, that uses a CNN-based structure. A base model is trained in a specially designed layer-wise training procedure over a pool of historical data from many financial markets, in order to extract the common patterns from different markets. Our experiments, in which we have used hundreds of stocks in S\&P 500 as well as 14 famous indices around the world, show that this model can outperform baseline algorithms when predicting the directional movement of the markets for which it has been trained for. We also show that the base model can be fine-tuned for predicting new markets and achieve a better performance compared to the state of the art baseline algorithms that focus on constructing market-specific models from scratch.
GEMRank: Global Entity Embedding For Collaborative Filtering
Nov 05, 2018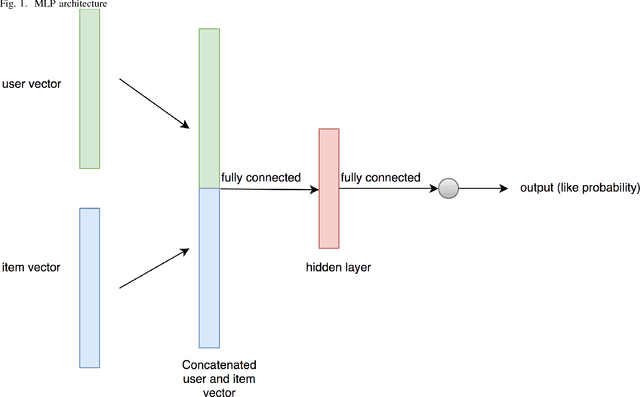
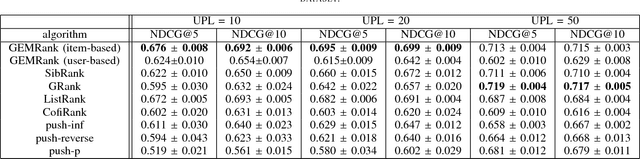
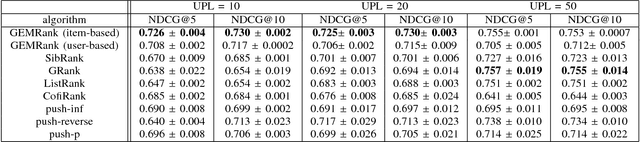
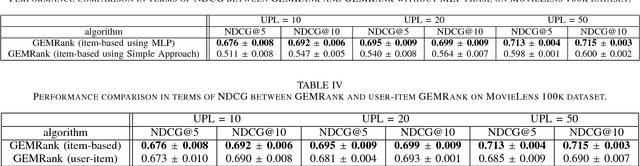
Recently, word embedding algorithms have been applied to map the entities of recommender systems, such as users and items, to new feature spaces using textual element-context relations among them. Unlike many other domains, this approach has not achieved a desired performance in collaborative filtering problems, probably due to unavailability of appropriate textual data. In this paper we propose a new recommendation framework, called GEMRank that can be applied when the user-item matrix is the sole available souce of information. It uses the concept of profile co-occurrence for defining relations among entities and applies a factorization method for embedding the users and items. GEMRank then feeds the extracted representations to a neural network model to predict user-item like/dislike relations which the final recommendations are made based on. We evaluated GEMRank in an extensive set of experiments against state of the art recommendation methods. The results show that GEMRank significantly outperforms the baseline algorithms in a variety of data sets with different degrees of density.