 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasking Kernel for Learning Energy-Efficient Speech Representation
Feb 08, 2023



Modern smartphones are equipped with powerful audio hardware and processors, allowing them to acquire and perform on-device speech processing at high sampling rates. However, energy consumption remains a concern, especially for resource-intensive DNNs. Prior mobile speech processing reduced computational complexity by compacting the model or reducing input dimensions via hyperparameter tuning, which reduced accuracy or required more training iterations. This paper proposes gradient descent for optimizing energy-efficient speech recording format (length and sampling rate). The goal is to reduce the input size, which reduces data collection and inference energy. For a backward pass, a masking function with non-zero derivatives (Gaussian, Hann, and Hamming) is used as a windowing function and a lowpass filter. An energy-efficient penalty is introduced to incentivize the reduction of the input size. The proposed masking outperformed baselines by 8.7% in speaker recognition and traumatic brain injury detection using 49% shorter duration, sampled at a lower frequency.
A comparative study for interpreting deep learning prediction of the Parkinson's disease diagnosis from SPECT imaging
Aug 23, 2019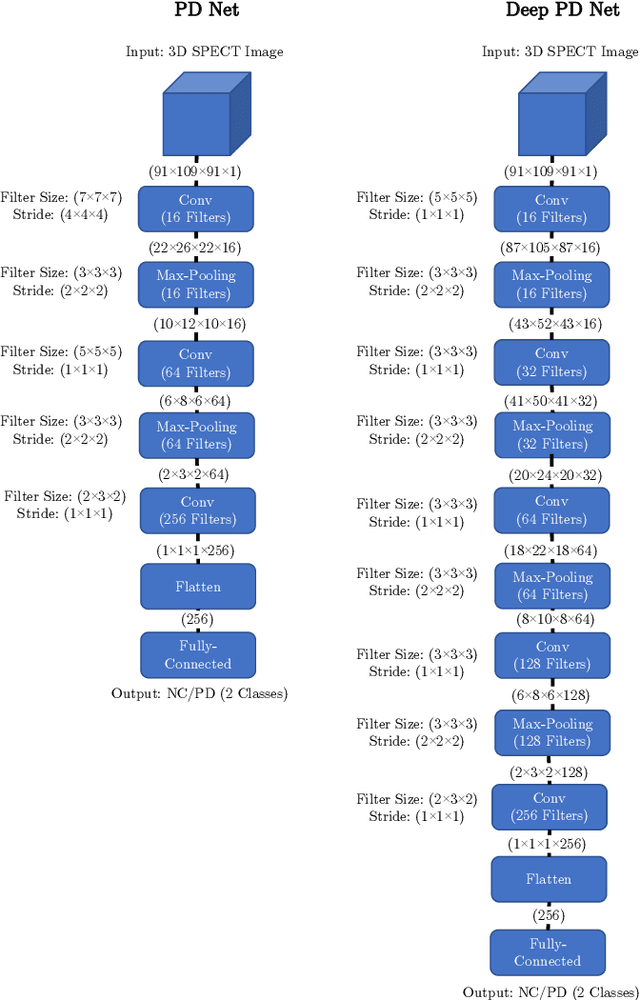
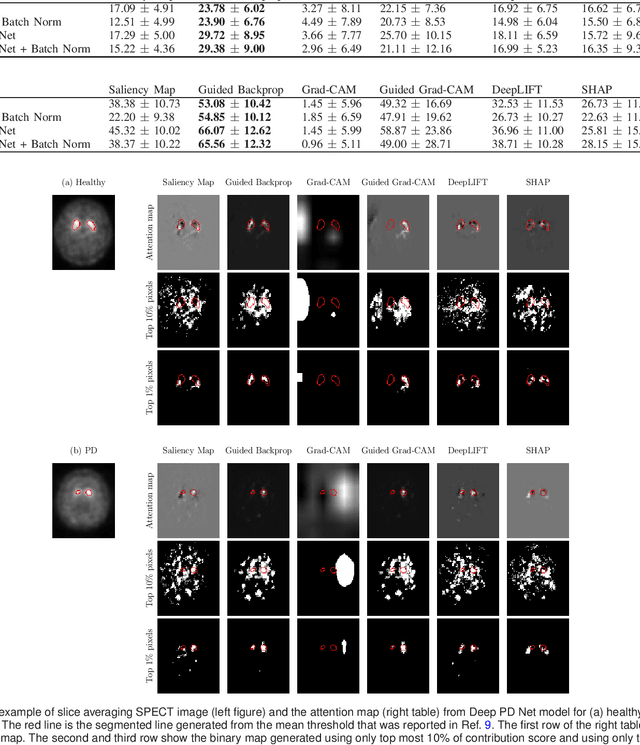
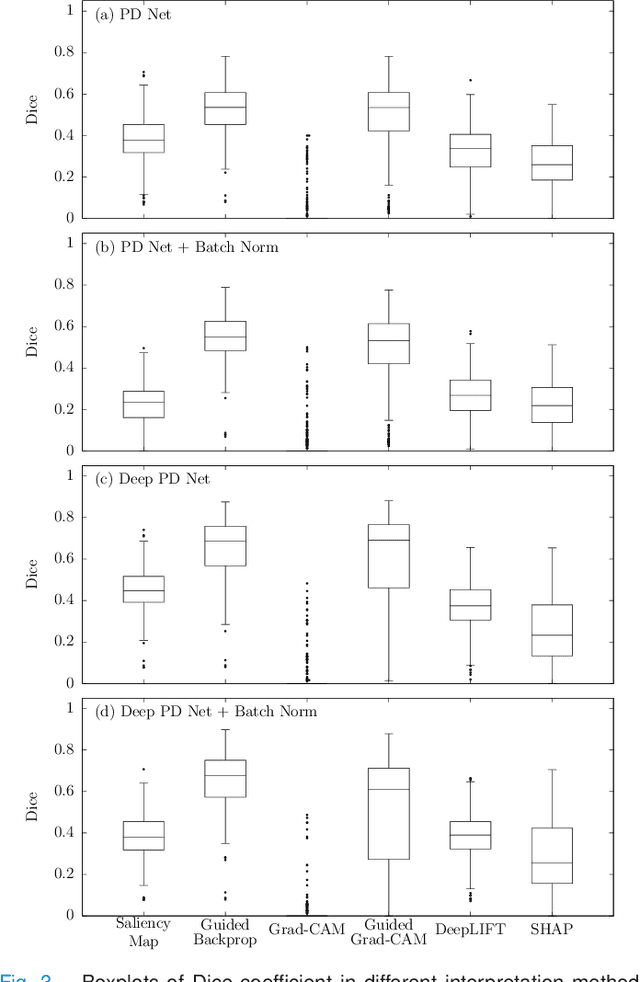

The application of deep learning to single-photon emission computed tomography (SPECT) imaging in Parkinson's disease shows effectively high diagnosis accuracy. However, difficulties in model interpretation were occurred due to the complexity of the deep learning model. Although several interpretation methods were created to show the attention map that contains important features of the input data, it is still uncertain whether these methods can be applied in PD diagnosis. Four different models of the deep learning approach based on 3-dimensional convolution neural network (3D-CNN) of well-established architectures have been trained with an accuracy up to 95-96% in classification performance. These four models have been used as the comparative study for well-known interpretation methods. Generally, radiologists interpret SPECT images by confirming the shape of the I123-Ioflupane uptake in the striatal nuclei. To evaluate the interpretation performance, the segmented striatal nuclei of SPECT images are chosen as the ground truth. Results suggest that guided backpropagation and SHAP which were developed recently, provided the best interpretation performance. Guided backpropagation has the best performance to generate the attention map that focuses on the location of striatal nuclei. On the other hand, SHAP surpasses other methods in suggesting the change of the striatal nucleus uptake shape from healthy to PD subjects. Results from both methods confirm that 3D-CNN focuses on the striatal nuclei in the same way as the radiologist, and both methods should be suggested to increase the credibility of the model.
Affective EEG-Based Person Identification Using the Deep Learning Approach
Jul 15, 2018
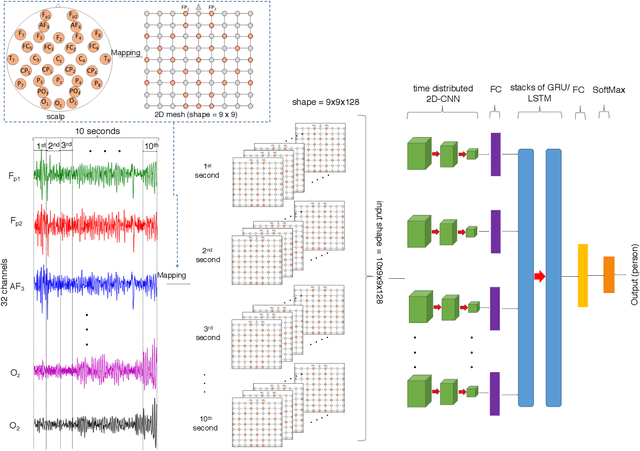


There are several reports available on affective electroencephalography-based personal identification (affective EEG-based PI), one of which uses a small dataset and another reaching less than 90% of the mean correct recognition rate \emph{CRR},. Thus, the aim of this paper is to improve and evaluate the performance of affective EEG-based PI using a deep learning approach. The state-of-the-art EEG dataset DEAP was used as the standard for affective recognition. Thirty-two healthy participants participated in the experiment. They were asked to watch affective elicited music videos and score subjective ratings for forty video clips during the EEG measurement. An EEG amplifier with thirty-two electrodes was used to record affective EEG measurements from the participants. To identify personal EEG, a cascade of deep learning architectures was proposed, using a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). CNNs are used to handle the spatial information from the EEG while RNNs extract the temporal information. There has been a cascade of CNNs, with recurrent models known as Long Short-Term Memory (CNN-LSTM) and Gate Recurrent Unit (CNN-GRU) for comparison. Experimental results indicate that CNN-GRU and CNN-LSTM can deal with an EEG (4--40 Hz) rom different affective states and reach up to 99.90--100% mean \emph{CRR}. On the other hand, a traditional machine learning approach such as a support vector machine (SVM) using power spectral density (PSD) as a feature does not reach 50% mean \emph{CRR}. To reduce the number of EEG electrodes from thirty-two to five for more practical application, $F_{3}$, $F_{4}$, $F_{z}$, $F_{7}$ and $F_{8}$ were found to be the best five electrodes for application in similar scenarios to those in this study. CNN-GRU and CNN-LSTM reached up to 99.17% and 98.23% mean \emph{CRR}, respectively.