 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022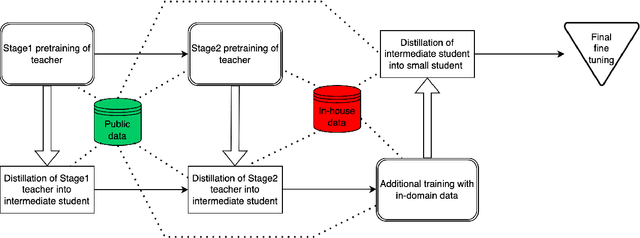
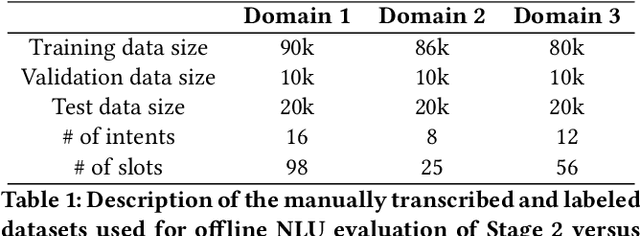
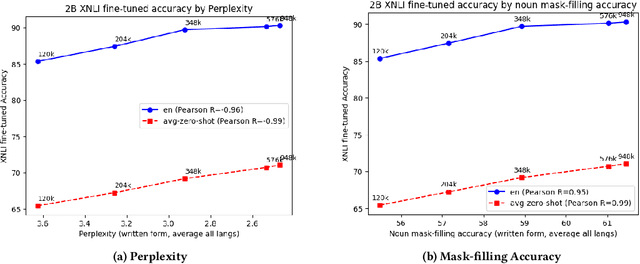
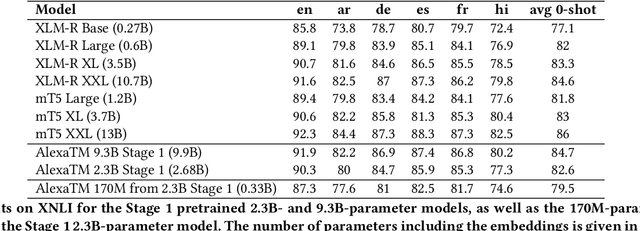
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Metamorphic Testing of a Deep Learning based Forecaster
Jul 13, 2019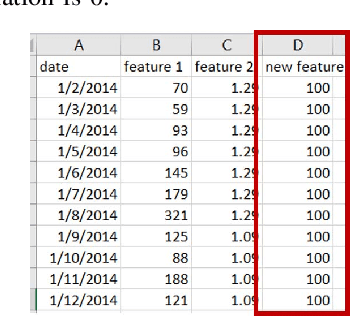
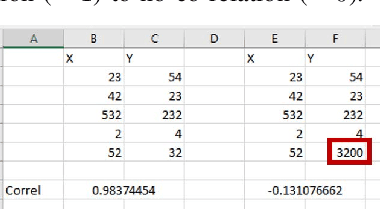
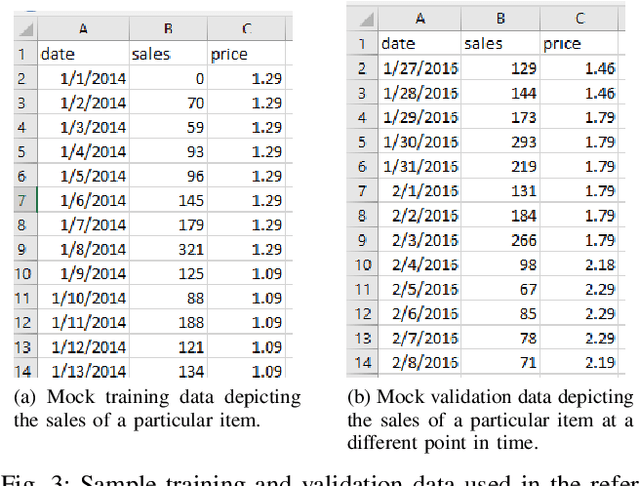
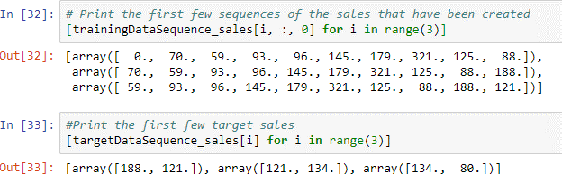
In this paper, we present the Metamorphic Testing of an in-use deep learning based forecasting application. The application looks at the past data of system characteristics (e.g. `memory allocation') to predict outages in the future. We focus on two statistical / machine learning based components - a) detection of co-relation between system characteristics and b) estimating the future value of a system characteristic using an LSTM (a deep learning architecture). In total, 19 Metamorphic Relations have been developed and we provide proofs & algorithms where applicable. We evaluated our method through two settings. In the first, we executed the relations on the actual application and uncovered 8 issues not known before. Second, we generated hypothetical bugs, through Mutation Testing, on a reference implementation of the LSTM based forecaster and found that 65.9% of the bugs were caught through the relations.
Identifying Implementation Bugs in Machine Learning based Image Classifiers using Metamorphic Testing
Aug 16, 2018
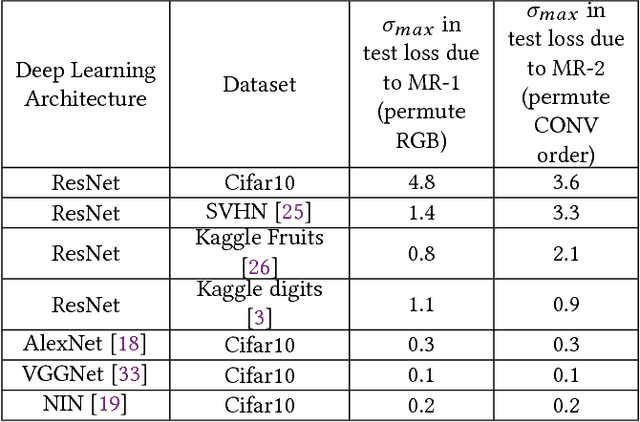

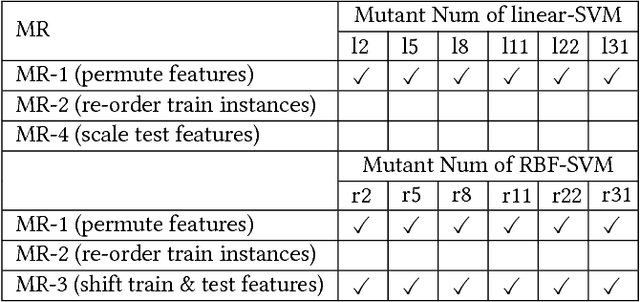
We have recently witnessed tremendous success of Machine Learning (ML) in practical applications. Computer vision, speech recognition and language translation have all seen a near human level performance. We expect, in the near future, most business applications will have some form of ML. However, testing such applications is extremely challenging and would be very expensive if we follow today's methodologies. In this work, we present an articulation of the challenges in testing ML based applications. We then present our solution approach, based on the concept of Metamorphic Testing, which aims to identify implementation bugs in ML based image classifiers. We have developed metamorphic relations for an application based on Support Vector Machine and a Deep Learning based application. Empirical validation showed that our approach was able to catch 71% of the implementation bugs in the ML applications.