 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Noisy Segmentation based fragmented burn scars identification in Amazon Rainforest
Sep 10, 2020

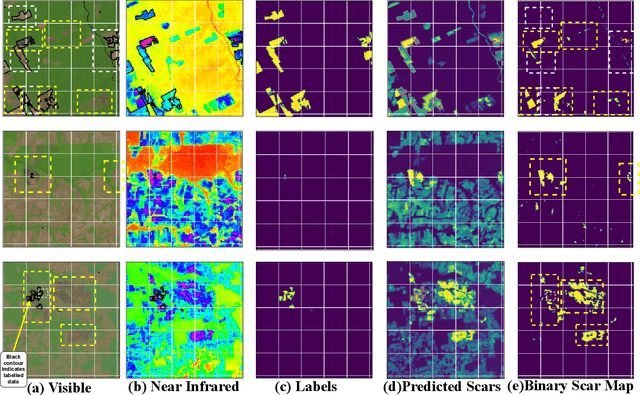
Detection of burn marks due to wildfires in inaccessible rain forests is important for various disaster management and ecological studies. The fragmented nature of arable landscapes and diverse cropping patterns often thwart the precise mapping of burn scars. Recent advances in remote-sensing and availability of multimodal data offer a viable solution to this mapping problem. However, the task to segment burn marks is difficult because of its indistinguishably with similar looking land patterns, severe fragmented nature of burn marks and partially labelled noisy datasets. In this work we present AmazonNET -- a convolutional based network that allows extracting of burn patters from multimodal remote sensing images. The network consists of UNet: a well-known encoder decoder type of architecture with skip connections commonly used in biomedical segmentation. The proposed framework utilises stacked RGB-NIR channels to segment burn scars from the pastures by training on a new weakly labelled noisy dataset from Amazonia. Our model illustrates superior performance by correctly identifying partially labelled burn scars and rejecting incorrectly labelled samples, demonstrating our approach as one of the first to effectively utilise deep learning based segmentation models in multimodal burn scar identification.
The Amazing Mysteries of the Gutter: Drawing Inferences Between Panels in Comic Book Narratives
May 07, 2017


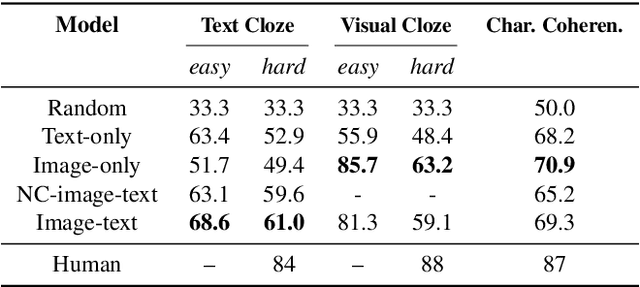
Visual narrative is often a combination of explicit information and judicious omissions, relying on the viewer to supply missing details. In comics, most movements in time and space are hidden in the "gutters" between panels. To follow the story, readers logically connect panels together by inferring unseen actions through a process called "closure". While computers can now describe what is explicitly depicted in natural images, in this paper we examine whether they can understand the closure-driven narratives conveyed by stylized artwork and dialogue in comic book panels. We construct a dataset, COMICS, that consists of over 1.2 million panels (120 GB) paired with automatic textbox transcriptions. An in-depth analysis of COMICS demonstrates that neither text nor image alone can tell a comic book story, so a computer must understand both modalities to keep up with the plot. We introduce three cloze-style tasks that ask models to predict narrative and character-centric aspects of a panel given n preceding panels as context. Various deep neural architectures underperform human baselines on these tasks, suggesting that COMICS contains fundamental challenges for both vision and language.