 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Whole-Slide Segmentation from Inexact and Incomplete Labels using Tissue Graphs
Mar 04, 2021Segmenting histology images into diagnostically relevant regions is imperative to support timely and reliable decisions by pathologists. To this end, computer-aided techniques have been proposed to delineate relevant regions in scanned histology slides. However, the techniques necessitate task-specific large datasets of annotated pixels, which is tedious, time-consuming, expensive, and infeasible to acquire for many histology tasks. Thus, weakly-supervised semantic segmentation techniques are proposed to utilize weak supervision that is cheaper and quicker to acquire. In this paper, we propose SegGini, a weakly supervised segmentation method using graphs, that can utilize weak multiplex annotations, i.e. inexact and incomplete annotations, to segment arbitrary and large images, scaling from tissue microarray (TMA) to whole slide image (WSI). Formally, SegGini constructs a tissue-graph representation for an input histology image, where the graph nodes depict tissue regions. Then, it performs weakly-supervised segmentation via node classification by using inexact image-level labels, incomplete scribbles, or both. We evaluated SegGini on two public prostate cancer datasets containing TMAs and WSIs. Our method achieved state-of-the-art segmentation performance on both datasets for various annotation settings while being comparable to a pathologist baseline.
Quantifying Explainers of Graph Neural Networks in Computational Pathology
Nov 25, 2020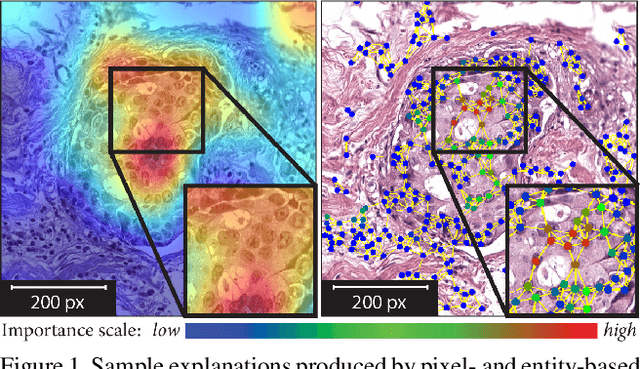
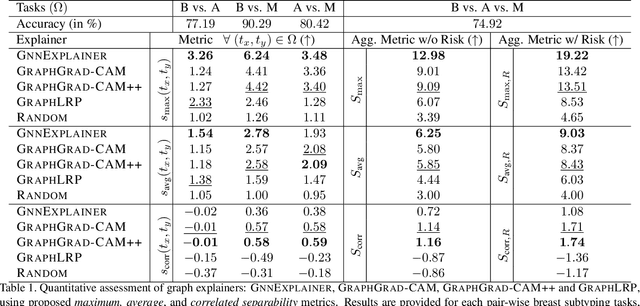
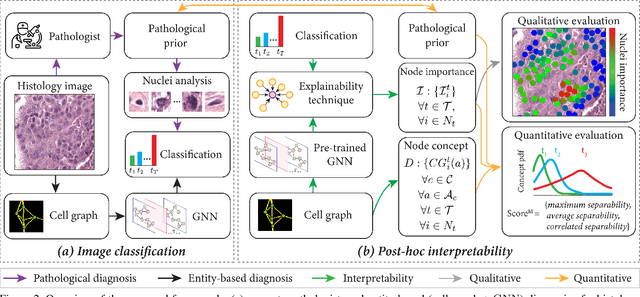
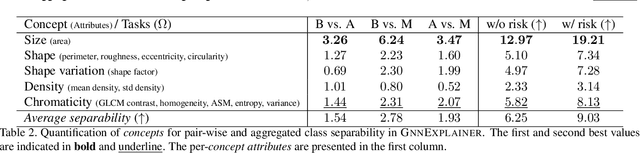
Explainability of deep learning methods is imperative to facilitate their clinical adoption in digital pathology. However, popular deep learning methods and explainability techniques (explainers) based on pixel-wise processing disregard biological entities' notion, thus complicating comprehension by pathologists. In this work, we address this by adopting biological entity-based graph processing and graph explainers enabling explanations accessible to pathologists. In this context, a major challenge becomes to discern meaningful explainers, particularly in a standardized and quantifiable fashion. To this end, we propose herein a set of novel quantitative metrics based on statistics of class separability using pathologically measurable concepts to characterize graph explainers. We employ the proposed metrics to evaluate three types of graph explainers, namely the layer-wise relevance propagation, gradient-based saliency, and graph pruning approaches, to explain Cell-Graph representations for Breast Cancer Subtyping. The proposed metrics are also applicable in other domains by using domain-specific intuitive concepts. We validate the qualitative and quantitative findings on the BRACS dataset, a large cohort of breast cancer RoIs, by expert pathologists.
NINEPINS: Nuclei Instance Segmentation with Point Annotations
Jun 24, 2020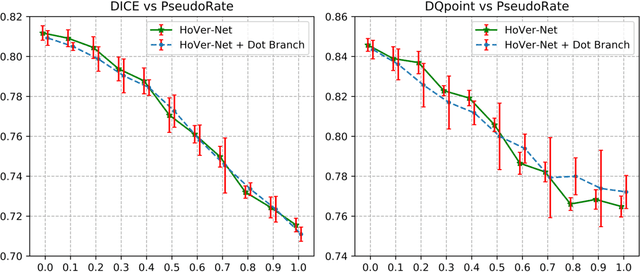
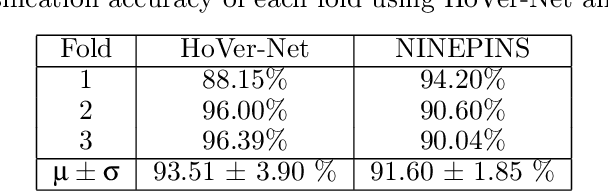
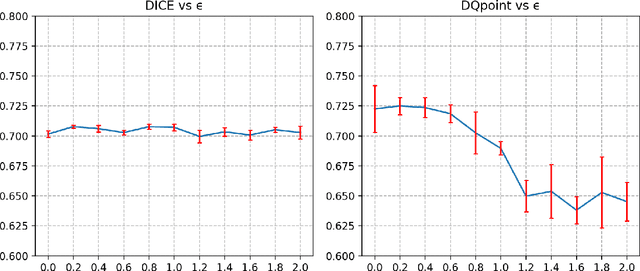
Deep learning-based methods are gaining traction in digital pathology, with an increasing number of publications and challenges that aim at easing the work of systematically and exhaustively analyzing tissue slides. These methods often achieve very high accuracies, at the cost of requiring large annotated datasets to train. This requirement is especially difficult to fulfill in the medical field, where expert knowledge is essential. In this paper we focus on nuclei segmentation, which generally requires experienced pathologists to annotate the nuclear areas in gigapixel histological images. We propose an algorithm for instance segmentation that uses pseudo-label segmentations generated automatically from point annotations, as a method to reduce the burden for pathologists. With the generated segmentation masks, the proposed method trains a modified version of HoVer-Net model to achieve instance segmentation. Experimental results show that the proposed method is robust to inaccuracies in point annotations and comparison with Hover-Net trained with fully annotated instance masks shows that a degradation in segmentation performance does not always imply a degradation in higher order tasks such as tissue classification.
From visual words to a visual grammar: using language modelling for image classification
Mar 16, 2017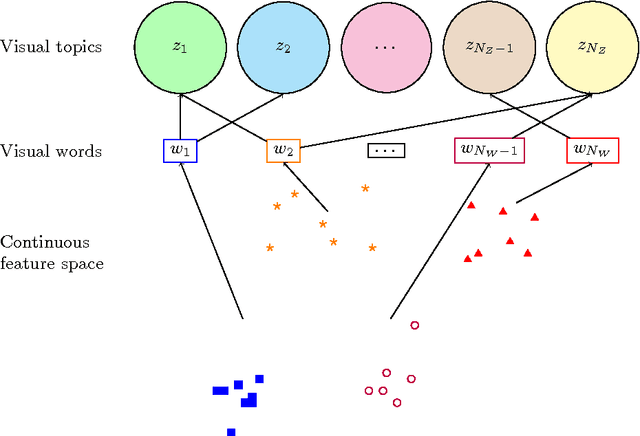
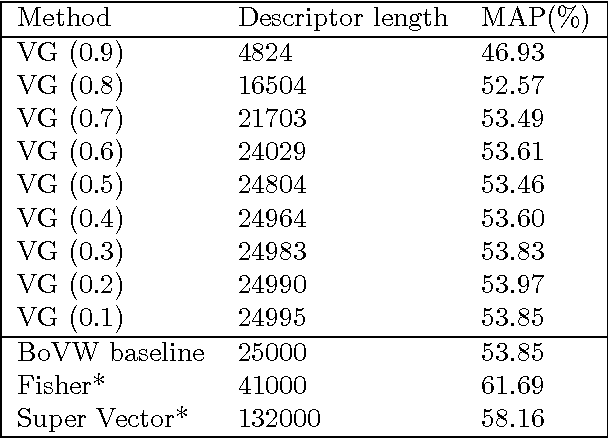
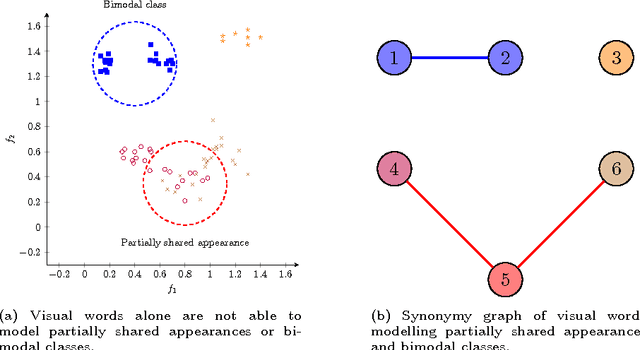
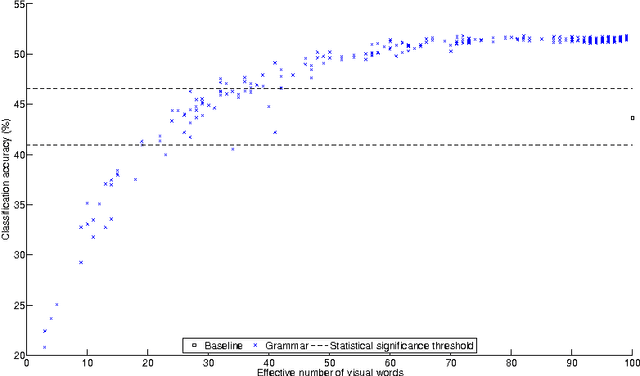
The Bag--of--Visual--Words (BoVW) is a visual description technique that aims at shortening the semantic gap by partitioning a low--level feature space into regions of the feature space that potentially correspond to visual concepts and by giving more value to this space. In this paper we present a conceptual analysis of three major properties of language grammar and how they can be adapted to the computer vision and image understanding domain based on the bag of visual words paradigm. Evaluation of the visual grammar shows that a positive impact on classification accuracy and/or descriptor size is obtained when the technique are applied when the proposed techniques are applied.