 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Domain Generalization Baselines
Jan 27, 2021
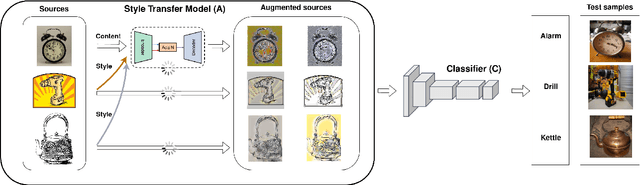
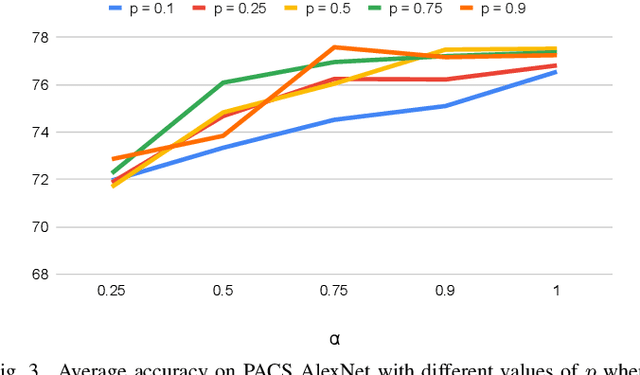

Despite being very powerful in standard learning settings, deep learning models can be extremely brittle when deployed in scenarios different from those on which they were trained. Domain generalization methods investigate this problem and data augmentation strategies have shown to be helpful tools to increase data variability, supporting model robustness across domains. In our work we focus on style transfer data augmentation and we present how it can be implemented with a simple and inexpensive strategy to improve generalization. Moreover, we analyze the behavior of current state of the art domain generalization methods when integrated with this augmentation solution: our thorough experimental evaluation shows that their original effect almost always disappears with respect to the augmented baseline. This issue open new scenarios for domain generalization research, highlighting the need of novel methods properly able to take advantage of the introduced data variability.
Self-Supervised Learning Across Domains
Jul 24, 2020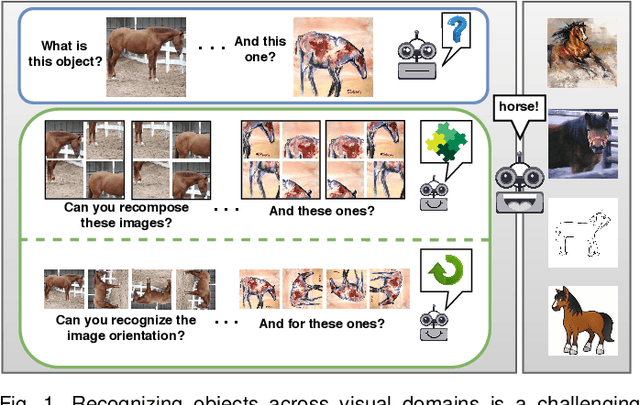
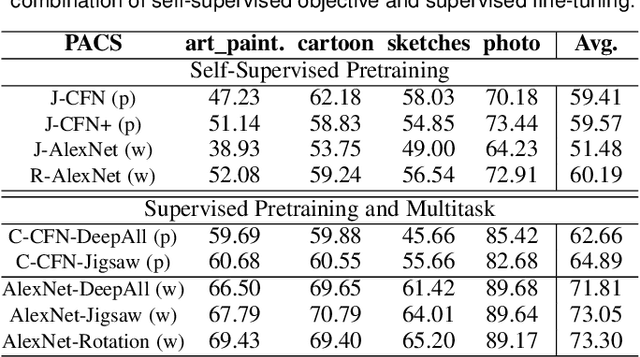
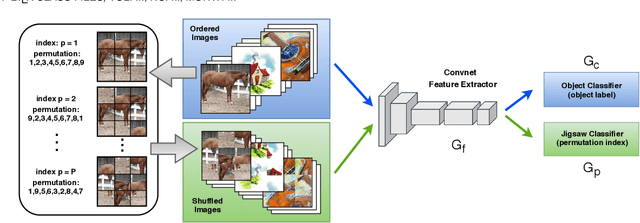
Human adaptability relies crucially on learning and merging knowledge from both supervised and unsupervised tasks: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the problem of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals on the same images. This secondary task helps the network to learn the concepts like spatial orientation and part correlation, while acting as a regularizer for the classification task. Extensive experiments confirm our intuition and show that our multi-task method combining supervised and self-supervised knowledge shows competitive results with respect to more complex domain generalization and adaptation solutions. It also proves its potential in the novel and challenging predictive and partial domain adaptation scenarios.
One-Shot Unsupervised Cross-Domain Detection
May 23, 2020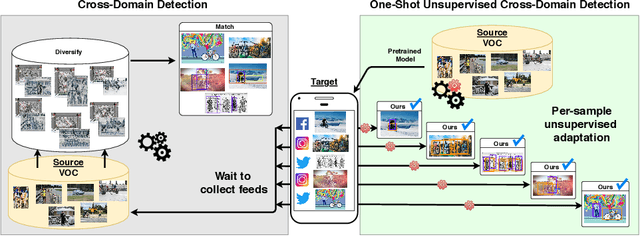
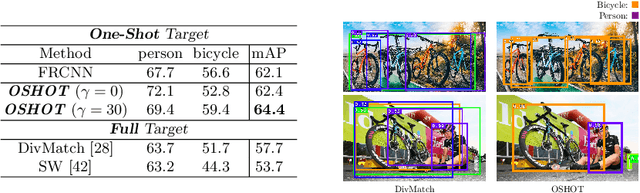
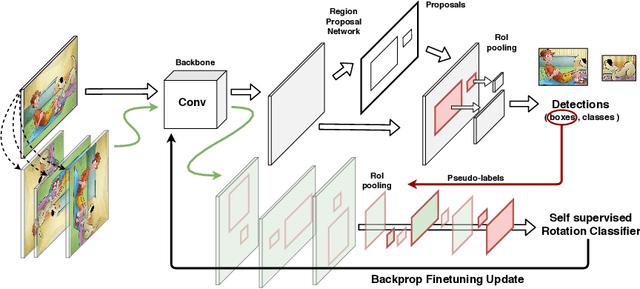

Despite impressive progress in object detection over the last years, it is still an open challenge to reliably detect objects across visual domains. Although the topic has attracted attention recently, current approaches all rely on the ability to access a sizable amount of target data for use at training time. This is a heavy assumption, as often it is not possible to anticipate the domain where a detector will be used, nor to access it in advance for data acquisition. Consider for instance the task of monitoring image feeds from social media: as every image is created and uploaded by a different user it belongs to a different target domain that is impossible to foresee during training. This paper addresses this setting, presenting an object detection algorithm able to perform unsupervised adaption across domains by using only one target sample, seen at test time. We achieve this by introducing a multi-task architecture that one-shot adapts to any incoming sample by iteratively solving a self-supervised task on it. We further enhance this auxiliary adaptation with cross-task pseudo-labeling. A thorough benchmark analysis against the most recent cross-domain detection methods and a detailed ablation study show the advantage of our method, which sets the state-of-the-art in the defined one-shot scenario.
Learning to Generalize One Sample at a Time with Self-Supervision
Oct 11, 2019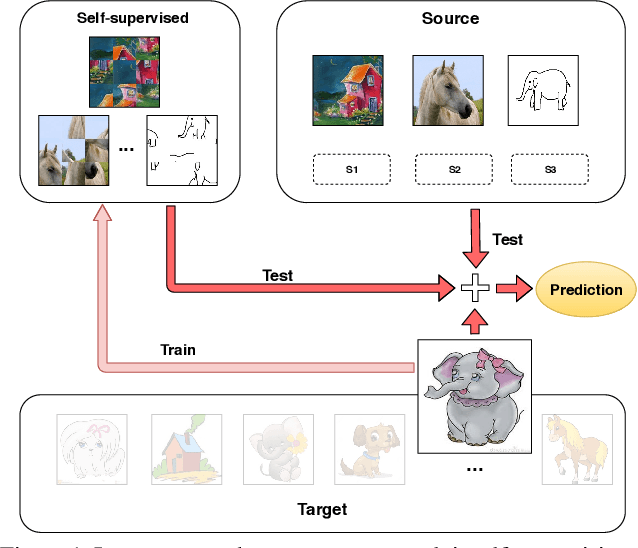
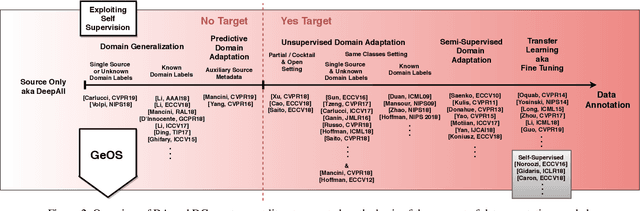
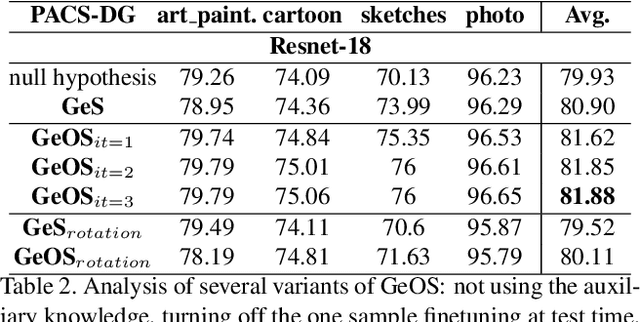
Although deep networks have significantly increased the performance of visual recognition methods, it is still challenging to achieve the robustness across visual domains that is necessary for real-world applications. To tackle this issue, research on domain adaptation and generalization has flourished over the last decade. An important aspect to consider when assessing the work done in the literature so far is the amount of data annotation necessary for training each approach, both at the source and target level. In this paper we argue that the data annotation overload should be minimal, as it is costly. Hence, we propose to use self-supervised learning to achieve domain generalization and adaptation. We consider learning regularities from non annotated data as an auxiliary task, and cast the problem within an Auxiliary Learning principled framework. Moreover, we suggest to further exploit the ability to learn about visual domains from non annotated images by learning from target data while testing, as data are presented to the algorithm one sample at a time. Results on three different scenarios confirm the value of our approach.
Tackling Partial Domain Adaptation with Self-Supervision
Jun 12, 2019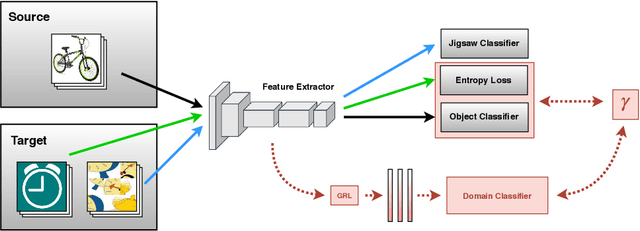
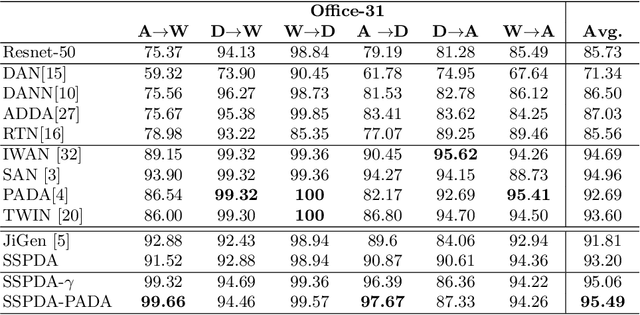
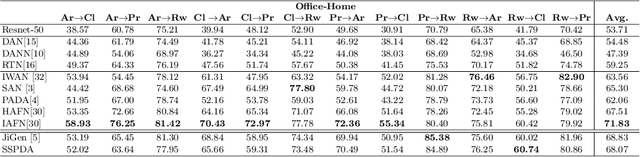
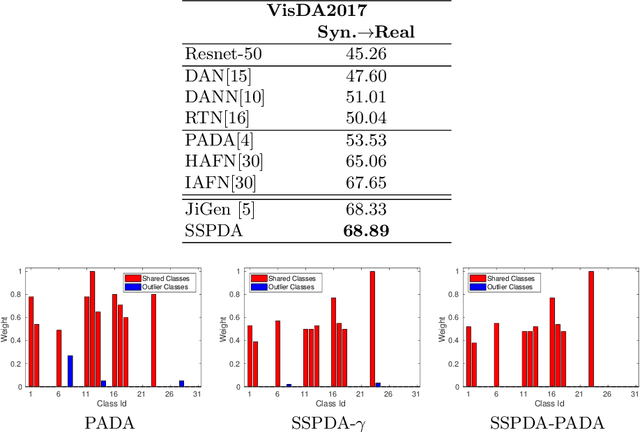
Domain adaptation approaches have shown promising results in reducing the marginal distribution difference among visual domains. They allow to train reliable models that work over datasets of different nature (photos, paintings etc), but they still struggle when the domains do not share an identical label space. In the partial domain adaptation setting, where the target covers only a subset of the source classes, it is challenging to reduce the domain gap without incurring in negative transfer. Many solutions just keep the standard domain adaptation techniques by adding heuristic sample weighting strategies. In this work we show how the self-supervisory signal obtained from the spatial co-location of patches can be used to define a side task that supports adaptation regardless of the exact label sharing condition across domains. We build over a recent work that introduced a jigsaw puzzle task for domain generalization: we describe how to reformulate this approach for partial domain adaptation and we show how it boosts existing adaptive solutions when combined with them. The obtained experimental results on three datasets supports the effectiveness of our approach.
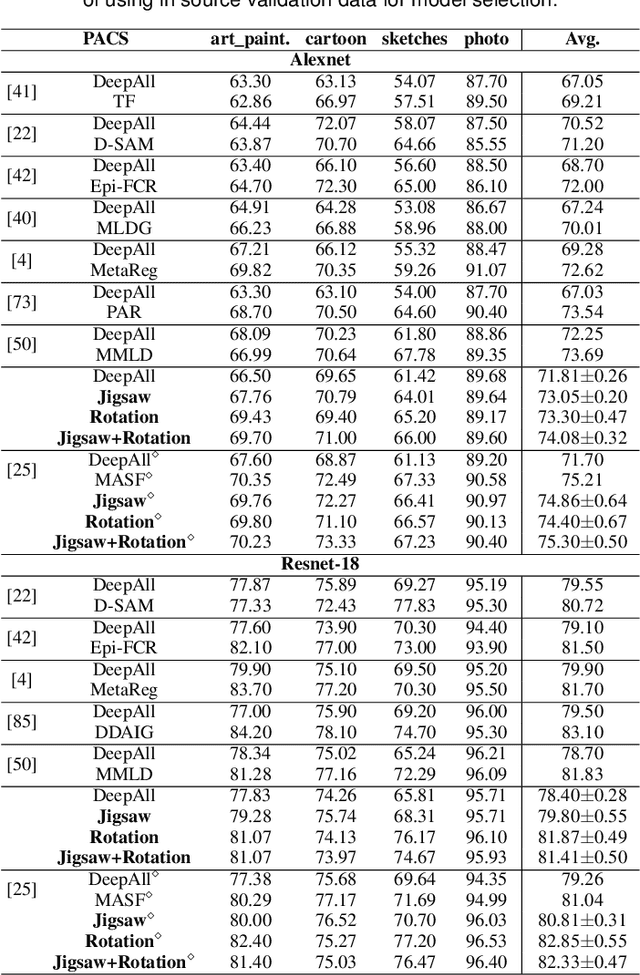
Domain Generalization by Solving Jigsaw Puzzles
Apr 14, 2019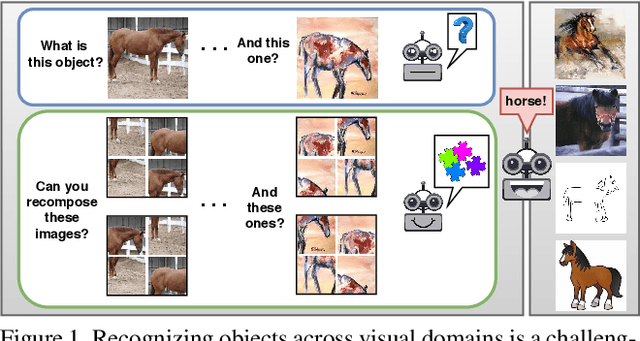
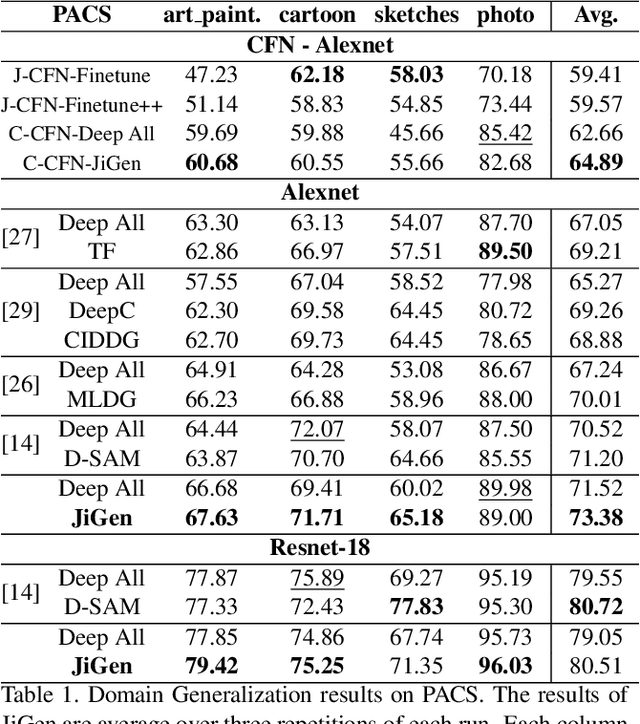
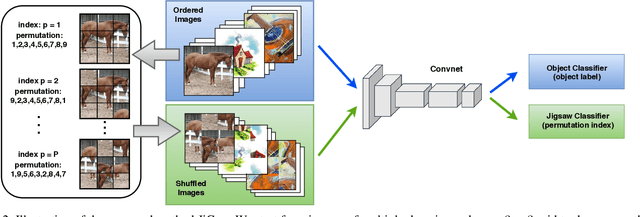
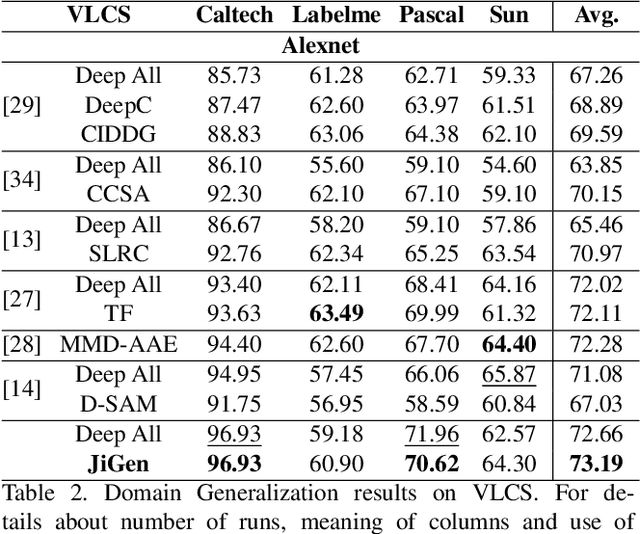
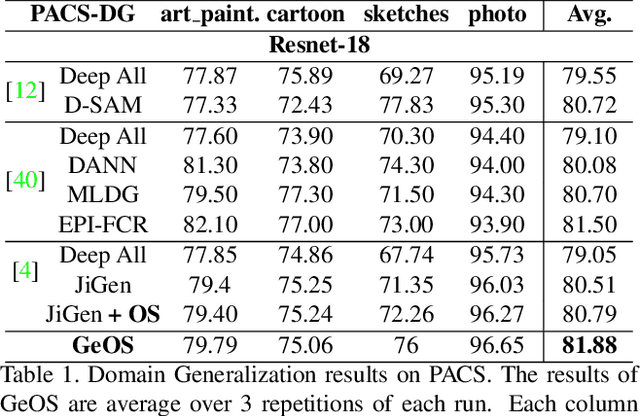
Human adaptability relies crucially on the ability to learn and merge knowledge both from supervised and unsupervised learning: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the task of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals how to solve a jigsaw puzzle on the same images. This secondary task helps the network to learn the concepts of spatial correlation while acting as a regularizer for the classification task. Multiple experiments on the PACS, VLCS, Office-Home and digits datasets confirm our intuition and show that this simple method outperforms previous domain generalization and adaptation solutions. An ablation study further illustrates the inner workings of our approach.
Domain Generalization with Domain-Specific Aggregation Modules
Sep 28, 2018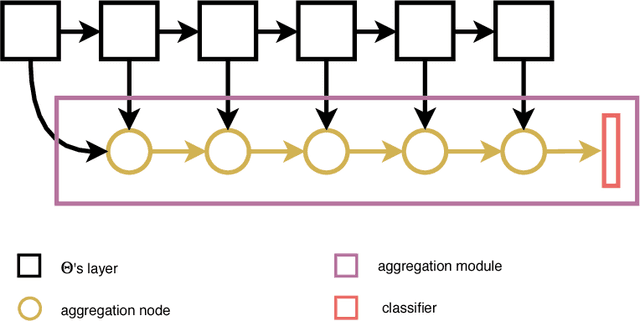
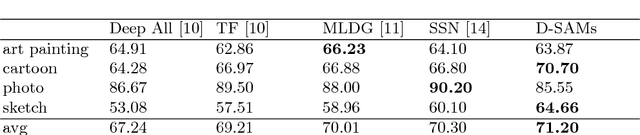
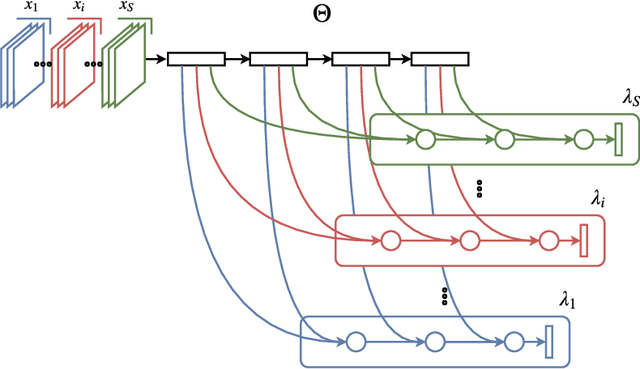
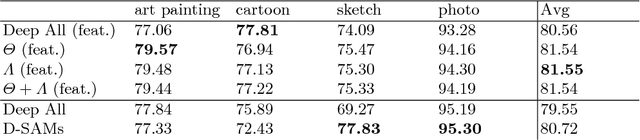
Visual recognition systems are meant to work in the real world. For this to happen, they must work robustly in any visual domain, and not only on the data used during training. Within this context, a very realistic scenario deals with domain generalization, i.e. the ability to build visual recognition algorithms able to work robustly in several visual domains, without having access to any information about target data statistic. This paper contributes to this research thread, proposing a deep architecture that maintains separated the information about the available source domains data while at the same time leveraging over generic perceptual information. We achieve this by introducing domain-specific aggregation modules that through an aggregation layer strategy are able to merge generic and specific information in an effective manner. Experiments on two different benchmark databases show the power of our approach, reaching the new state of the art in domain generalization.
Bridging between Computer and Robot Vision through Data Augmentation: a Case Study on Object Recognition
May 05, 2017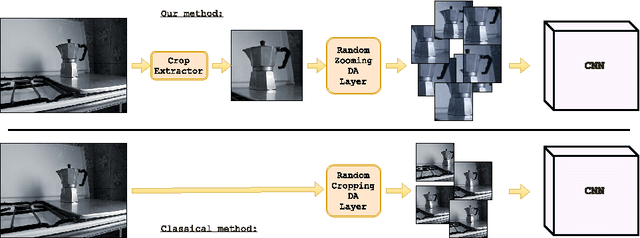
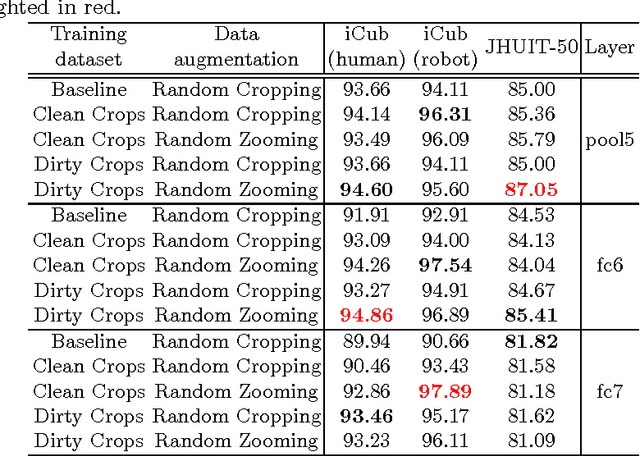

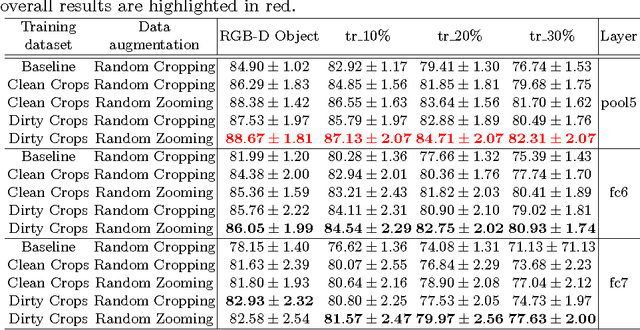
Despite the impressive progress brought by deep network in visual object recognition, robot vision is still far from being a solved problem. The most successful convolutional architectures are developed starting from ImageNet, a large scale collection of images of object categories downloaded from the Web. This kind of images is very different from the situated and embodied visual experience of robots deployed in unconstrained settings. To reduce the gap between these two visual experiences, this paper proposes a simple yet effective data augmentation layer that zooms on the object of interest and simulates the object detection outcome of a robot vision system. The layer, that can be used with any convolutional deep architecture, brings to an increase in object recognition performance of up to 7\%, in experiments performed over three different benchmark databases. Upon acceptance of the paper, our robot data augmentation layer will be made publicly available.