 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generalize One Sample at a Time with Self-Supervision
Paper and Code
Oct 11, 2019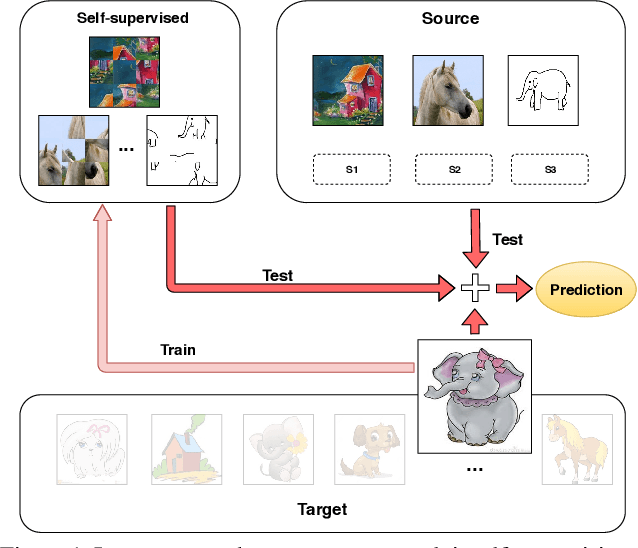
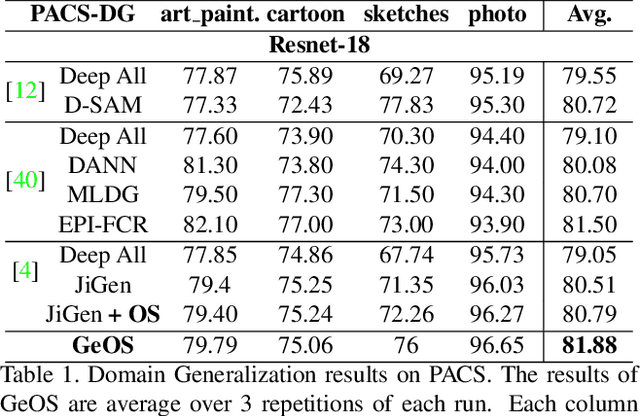
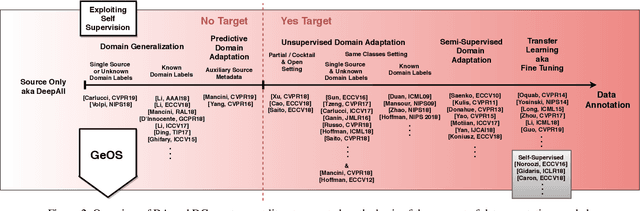
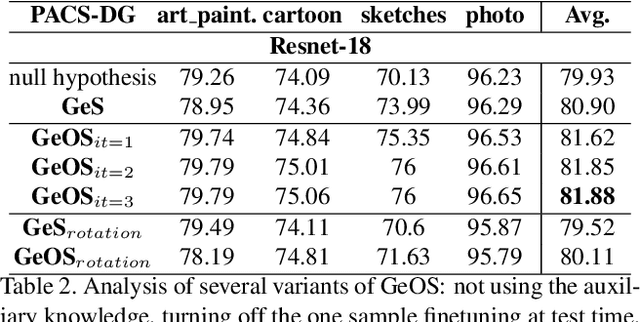
Although deep networks have significantly increased the performance of visual recognition methods, it is still challenging to achieve the robustness across visual domains that is necessary for real-world applications. To tackle this issue, research on domain adaptation and generalization has flourished over the last decade. An important aspect to consider when assessing the work done in the literature so far is the amount of data annotation necessary for training each approach, both at the source and target level. In this paper we argue that the data annotation overload should be minimal, as it is costly. Hence, we propose to use self-supervised learning to achieve domain generalization and adaptation. We consider learning regularities from non annotated data as an auxiliary task, and cast the problem within an Auxiliary Learning principled framework. Moreover, we suggest to further exploit the ability to learn about visual domains from non annotated images by learning from target data while testing, as data are presented to the algorithm one sample at a time. Results on three different scenarios confirm the value of our approach.