 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSICNav-Diffusion: Safe and Interactive Crowd Navigation with Diffusion Trajectory Predictions
Mar 11, 2025To navigate crowds without collisions, robots must interact with humans by forecasting their future motion and reacting accordingly. While learning-based prediction models have shown success in generating likely human trajectory predictions, integrating these stochastic models into a robot controller presents several challenges. The controller needs to account for interactive coupling between planned robot motion and human predictions while ensuring both predictions and robot actions are safe (i.e. collision-free). To address these challenges, we present a receding horizon crowd navigation method for single-robot multi-human environments. We first propose a diffusion model to generate joint trajectory predictions for all humans in the scene. We then incorporate these multi-modal predictions into a SICNav Bilevel MPC problem that simultaneously solves for a robot plan (upper-level) and acts as a safety filter to refine the predictions for non-collision (lower-level). Combining planning and prediction refinement into one bilevel problem ensures that the robot plan and human predictions are coupled. We validate the open-loop trajectory prediction performance of our diffusion model on the commonly used ETH/UCY benchmark and evaluate the closed-loop performance of our robot navigation method in simulation and extensive real-robot experiments demonstrating safe, efficient, and reactive robot motion.
Explaining Convolutional Neural Networks through Attribution-Based Input Sampling and Block-Wise Feature Aggregation
Oct 01, 2020
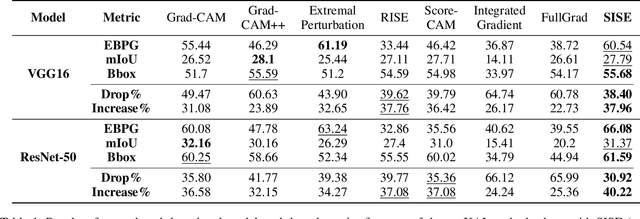
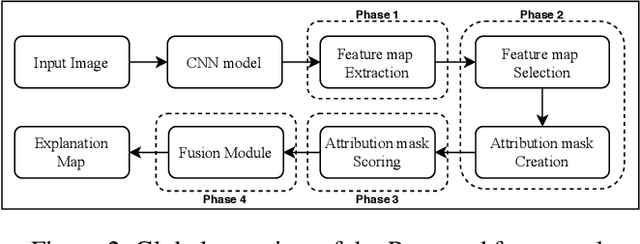
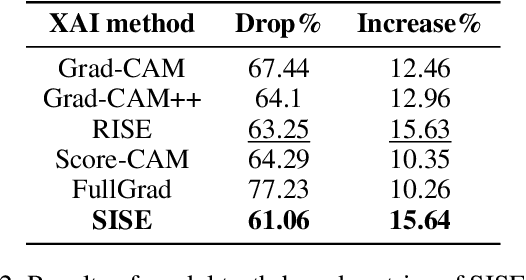
As an emerging field in Machine Learning, Explainable AI (XAI) has been offering remarkable performance in interpreting the decisions made by Convolutional Neural Networks (CNNs). To achieve visual explanations for CNNs, methods based on class activation mapping and randomized input sampling have gained great popularity. However, the attribution methods based on these techniques provide lower resolution and blurry explanation maps that limit their explanation power. To circumvent this issue, visualization based on various layers is sought. In this work, we collect visualization maps from multiple layers of the model based on an attribution-based input sampling technique and aggregate them to reach a fine-grained and complete explanation. We also propose a layer selection strategy that applies to the whole family of CNN-based models, based on which our extraction framework is applied to visualize the last layers of each convolutional block of the model. Moreover, we perform an empirical analysis of the efficacy of derived lower-level information to enhance the represented attributions. Comprehensive experiments conducted on shallow and deep models trained on natural and industrial datasets, using both ground-truth and model-truth based evaluation metrics validate our proposed algorithm by meeting or outperforming the state-of-the-art methods in terms of explanation ability and visual quality, demonstrating that our method shows stability regardless of the size of objects or instances to be explained.