 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Fidelity Interactive Video Segmentation Using Tensor Decomposition Boundary Loss Convolutional Tessellations and Context Aware Skip Connections
Nov 23, 2020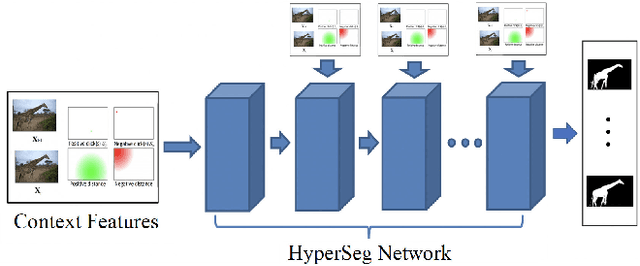


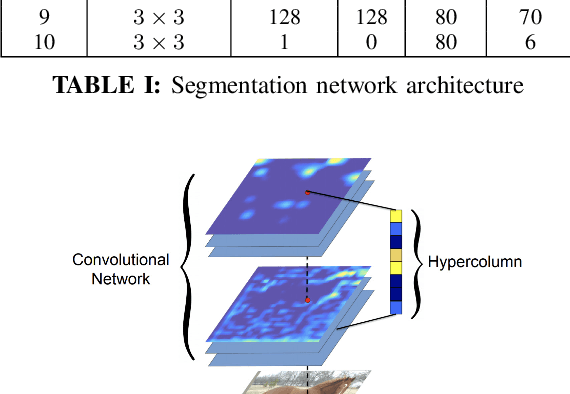
We provide a high fidelity deep learning algorithm (HyperSeg) for interactive video segmentation tasks using a convolutional network with context-aware skip connections, and compressed, hypercolumn image features combined with a convolutional tessellation procedure. In order to maintain high output fidelity, our model crucially processes and renders all image features in high resolution, without utilizing downsampling or pooling procedures. We maintain this consistent, high grade fidelity efficiently in our model chiefly through two means: (1) We use a statistically-principled tensor decomposition procedure to modulate the number of hypercolumn features and (2) We render these features in their native resolution using a convolutional tessellation technique. For improved pixel level segmentation results, we introduce a boundary loss function; for improved temporal coherence in video data, we include temporal image information in our model. Through experiments, we demonstrate the improved accuracy of our model against baseline models for interactive segmentation tasks using high resolution video data. We also introduce a benchmark video segmentation dataset, the VFX Segmentation Dataset, which contains over 27,046 high resolution video frames, including greenscreen and various composited scenes with corresponding, hand crafted, pixel level segmentations. Our work presents an extension to improvement to state of the art segmentation fidelity with high resolution data and can be used across a broad range of application domains, including VFX pipelines and medical imaging disciplines.
Regularized L21-Based Semi-NonNegative Matrix Factorization
May 10, 2020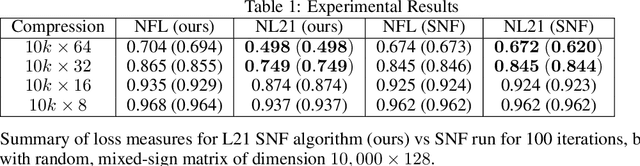
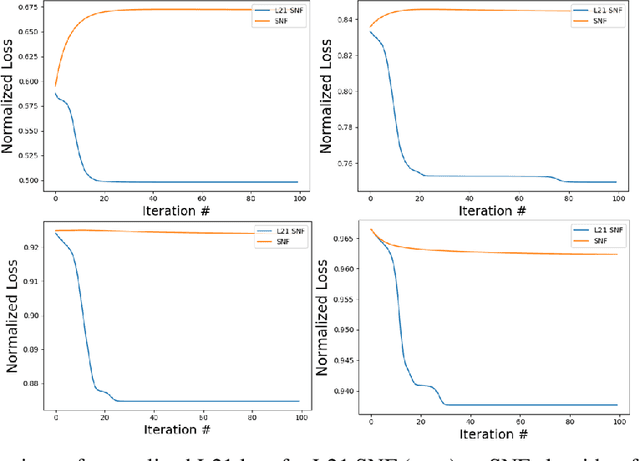

We present a general-purpose data compression algorithm, Regularized L21 Semi-NonNegative Matrix Factorization (L21 SNF). L21 SNF provides robust, parts-based compression applicable to mixed-sign data for which high fidelity, individualdata point reconstruction is paramount. We derive a rigorous proof of convergenceof our algorithm. Through experiments, we show the use-case advantages presentedby L21 SNF, including application to the compression of highly overdeterminedsystems encountered broadly across many general machine learning processes.
Evolving Order and Chaos: Comparing Particle Swarm Optimization and Genetic Algorithms for Global Coordination of Cellular Automata
Sep 08, 2019

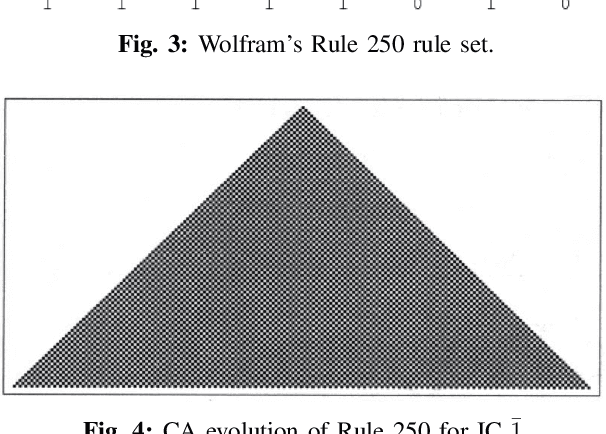
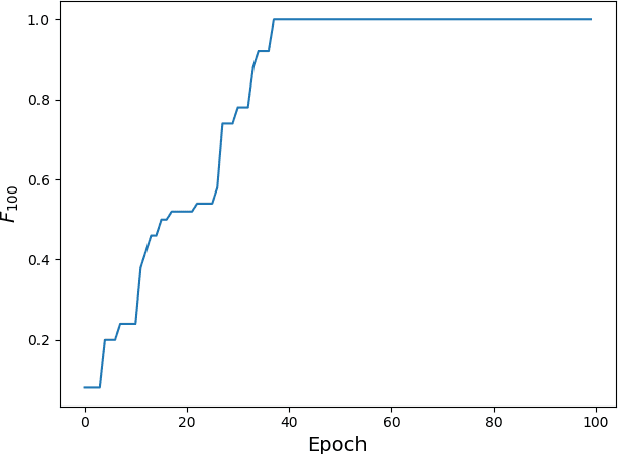
We apply two evolutionary search algorithms: Particle Swarm Optimization (PSO) and Genetic Algorithms (GAs) to the design of Cellular Automata (CA) that can perform computational tasks requiring global coordination. In particular, we compare search efficiency for PSO and GAs applied to both the density classification problem and to the novel generation of 'chaotic' CA. Our work furthermore introduces a new variant of PSO, the Binary Global-Local PSO (BGL-PSO).
Search Algorithms for Mastermind
Aug 16, 2019
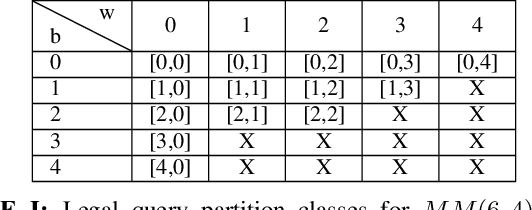
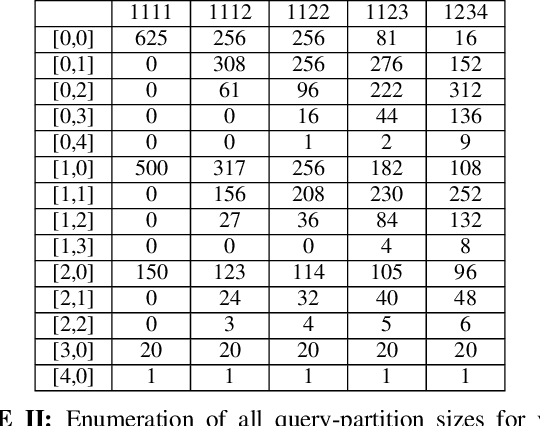
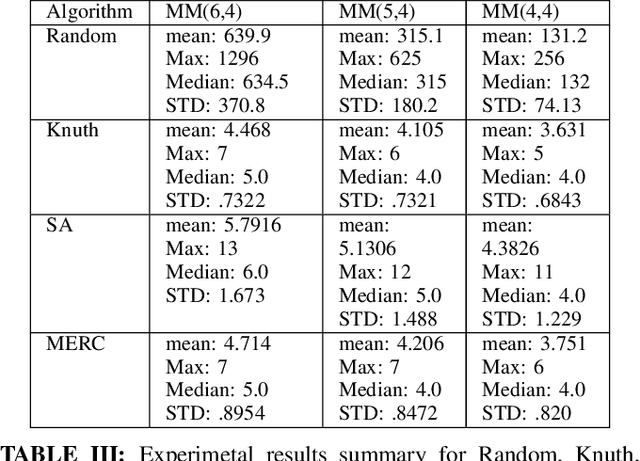
his paper presents two novel approaches to solving the classic board game mastermind, including a variant of simulated annealing (SA) and a technique we term maximum expected reduction in consistency (MERC). In addition, we compare search results for these algorithms to two baseline search methods: a random, uninformed search and the method of minimizing maximum query partition sets as originally developed by both Donald Knuth and Peter Norvig.
Deep Siamese Networks with Bayesian non-Parametrics for Video Object Tracking
Nov 18, 2018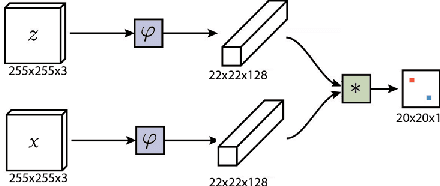

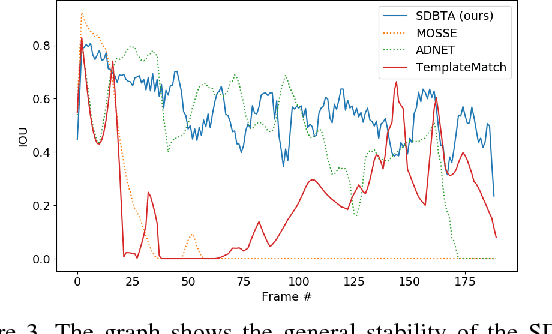
We present a novel algorithm utilizing a deep Siamese neural network as a general object similarity function in combination with a Bayesian optimization (BO) framework to encode spatio-temporal information for efficient object tracking in video. In particular, we treat the video tracking problem as a dynamic (i.e. temporally-evolving) optimization problem. Using Gaussian Process priors, we model a dynamic objective function representing the location of a tracked object in each frame. By exploiting temporal correlations, the proposed method queries the search space in a statistically principled and efficient way, offering several benefits over current state of the art video tracking methods.
Gaussian Processes with Context-Supported Priors for Active Object Localization
Sep 20, 2017
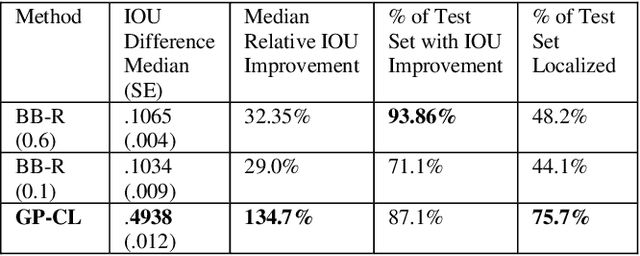
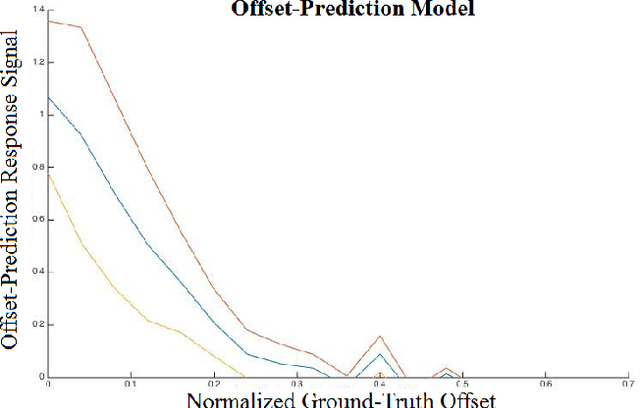
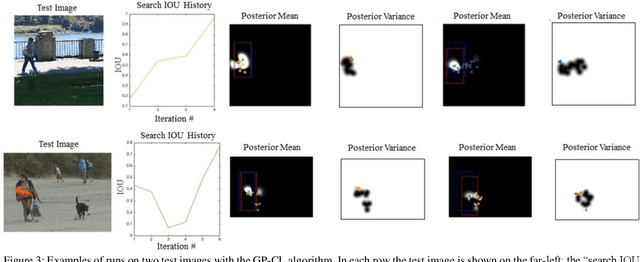
We devise an algorithm using a Bayesian optimization framework in conjunction with contextual visual data for the efficient localization of objects in still images. Recent research has demonstrated substantial progress in object localization and related tasks for computer vision. However, many current state-of-the-art object localization procedures still suffer from inaccuracy and inefficiency, in addition to failing to provide a principled and interpretable system amenable to high-level vision tasks. We address these issues with the current research. Our method encompasses an active search procedure that uses contextual data to generate initial bounding-box proposals for a target object. We train a convolutional neural network to approximate an offset distance from the target object. Next, we use a Gaussian Process to model this offset response signal over the search space of the target. We then employ a Bayesian active search for accurate localization of the target. In experiments, we compare our approach to a state-of-theart bounding-box regression method for a challenging pedestrian localization task. Our method exhibits a substantial improvement over this baseline regression method.
Fast On-Line Kernel Density Estimation for Active Object Localization
Nov 16, 2016
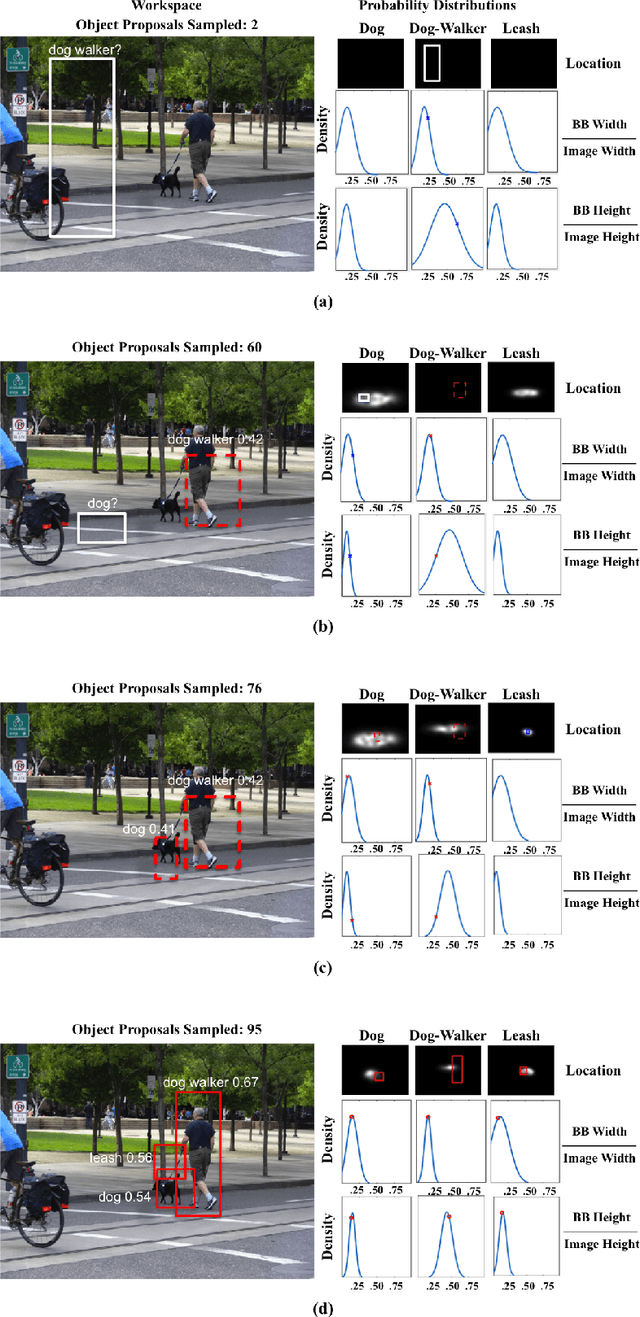


A major goal of computer vision is to enable computers to interpret visual situations---abstract concepts (e.g., "a person walking a dog," "a crowd waiting for a bus," "a picnic") whose image instantiations are linked more by their common spatial and semantic structure than by low-level visual similarity. In this paper, we propose a novel method for prior learning and active object localization for this kind of knowledge-driven search in static images. In our system, prior situation knowledge is captured by a set of flexible, kernel-based density estimations---a situation model---that represent the expected spatial structure of the given situation. These estimations are efficiently updated by information gained as the system searches for relevant objects, allowing the system to use context as it is discovered to narrow the search. More specifically, at any given time in a run on a test image, our system uses image features plus contextual information it has discovered to identify a small subset of training images---an importance cluster---that is deemed most similar to the given test image, given the context. This subset is used to generate an updated situation model in an on-line fashion, using an efficient multipole expansion technique. As a proof of concept, we apply our algorithm to a highly varied and challenging dataset consisting of instances of a "dog-walking" situation. Our results support the hypothesis that dynamically-rendered, context-based probability models can support efficient object localization in visual situations. Moreover, our approach is general enough to be applied to diverse machine learning paradigms requiring interpretable, probabilistic representations generated from partially observed data.
Active Object Localization in Visual Situations
Jul 02, 2016
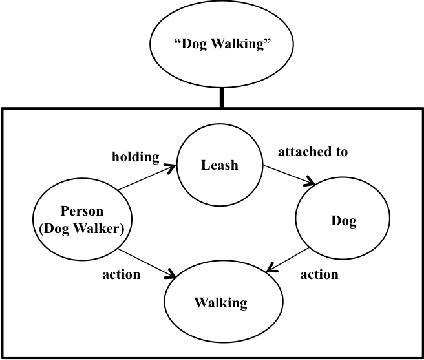

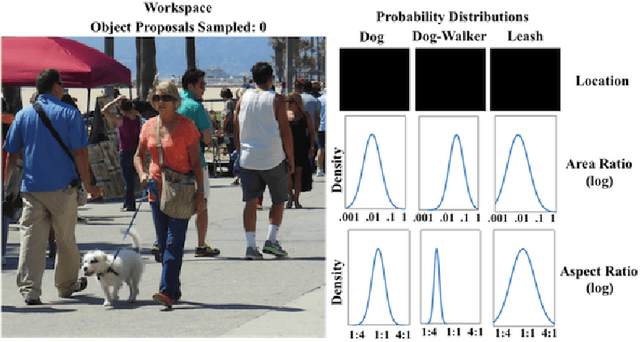
We describe a method for performing active localization of objects in instances of visual situations. A visual situation is an abstract concept---e.g., "a boxing match", "a birthday party", "walking the dog", "waiting for a bus"---whose image instantiations are linked more by their common spatial and semantic structure than by low-level visual similarity. Our system combines given and learned knowledge of the structure of a particular situation, and adapts that knowledge to a new situation instance as it actively searches for objects. More specifically, the system learns a set of probability distributions describing spatial and other relationships among relevant objects. The system uses those distributions to iteratively sample object proposals on a test image, but also continually uses information from those object proposals to adaptively modify the distributions based on what the system has detected. We test our approach's ability to efficiently localize objects, using a situation-specific image dataset created by our group. We compare the results with several baselines and variations on our method, and demonstrate the strong benefit of using situation knowledge and active context-driven localization. Finally, we contrast our method with several other approaches that use context as well as active search for object localization in images.