 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Image Retrieval via Active Grounding of Visual Situations
Oct 31, 2017

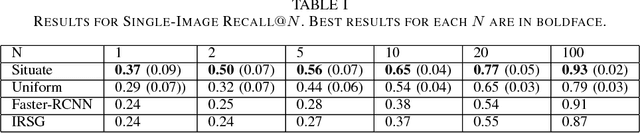
We describe a novel architecture for semantic image retrieval---in particular, retrieval of instances of visual situations. Visual situations are concepts such as "a boxing match," "walking the dog," "a crowd waiting for a bus," or "a game of ping-pong," whose instantiations in images are linked more by their common spatial and semantic structure than by low-level visual similarity. Given a query situation description, our architecture---called Situate---learns models capturing the visual features of expected objects as well the expected spatial configuration of relationships among objects. Given a new image, Situate uses these models in an attempt to ground (i.e., to create a bounding box locating) each expected component of the situation in the image via an active search procedure. Situate uses the resulting grounding to compute a score indicating the degree to which the new image is judged to contain an instance of the situation. Such scores can be used to rank images in a collection as part of a retrieval system. In the preliminary study described here, we demonstrate the promise of this system by comparing Situate's performance with that of two baseline methods, as well as with a related semantic image-retrieval system based on "scene graphs."
Fast On-Line Kernel Density Estimation for Active Object Localization
Nov 16, 2016
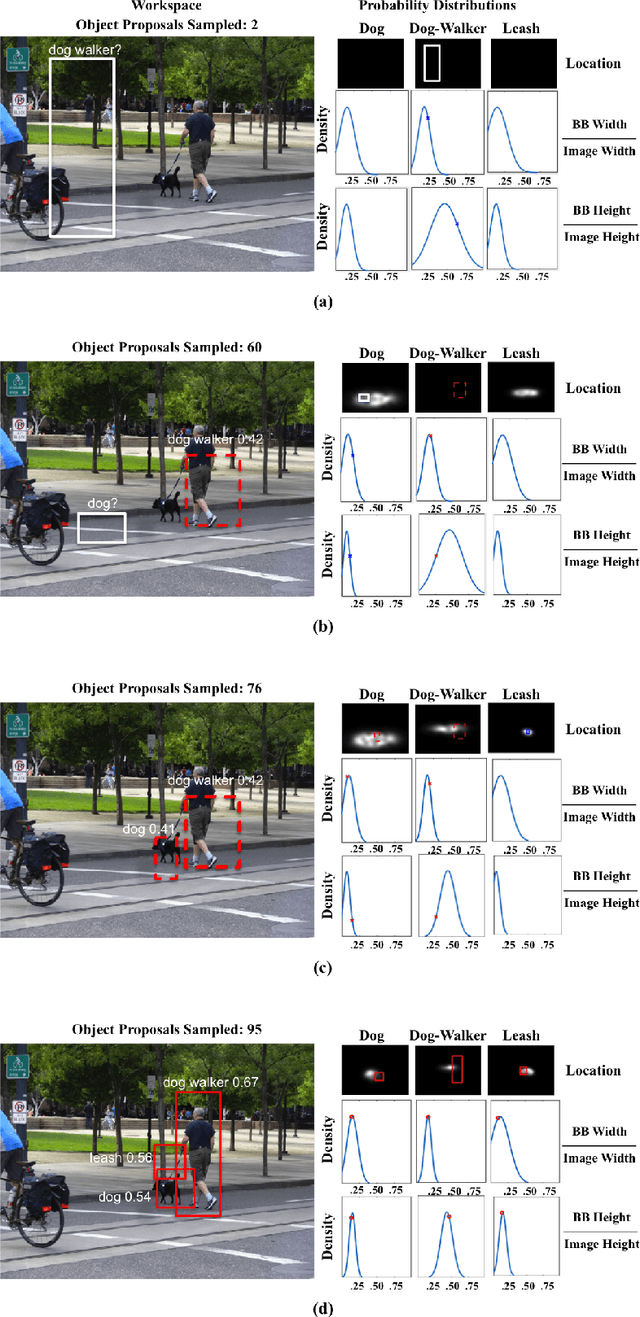


A major goal of computer vision is to enable computers to interpret visual situations---abstract concepts (e.g., "a person walking a dog," "a crowd waiting for a bus," "a picnic") whose image instantiations are linked more by their common spatial and semantic structure than by low-level visual similarity. In this paper, we propose a novel method for prior learning and active object localization for this kind of knowledge-driven search in static images. In our system, prior situation knowledge is captured by a set of flexible, kernel-based density estimations---a situation model---that represent the expected spatial structure of the given situation. These estimations are efficiently updated by information gained as the system searches for relevant objects, allowing the system to use context as it is discovered to narrow the search. More specifically, at any given time in a run on a test image, our system uses image features plus contextual information it has discovered to identify a small subset of training images---an importance cluster---that is deemed most similar to the given test image, given the context. This subset is used to generate an updated situation model in an on-line fashion, using an efficient multipole expansion technique. As a proof of concept, we apply our algorithm to a highly varied and challenging dataset consisting of instances of a "dog-walking" situation. Our results support the hypothesis that dynamically-rendered, context-based probability models can support efficient object localization in visual situations. Moreover, our approach is general enough to be applied to diverse machine learning paradigms requiring interpretable, probabilistic representations generated from partially observed data.
Active Object Localization in Visual Situations
Jul 02, 2016
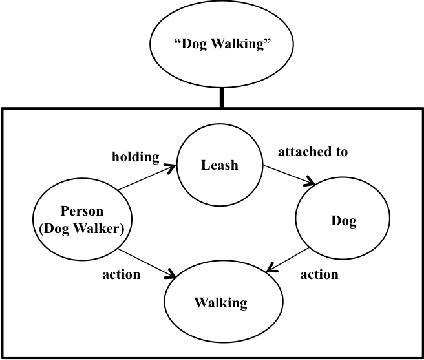

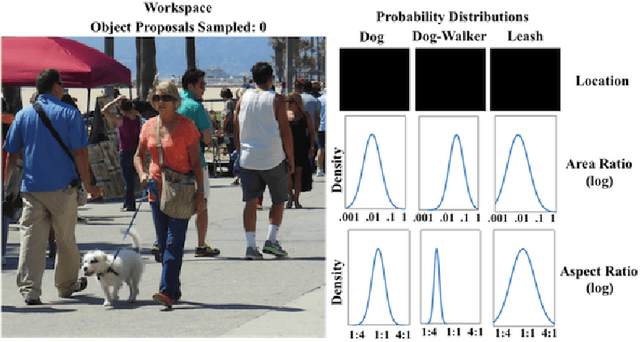
We describe a method for performing active localization of objects in instances of visual situations. A visual situation is an abstract concept---e.g., "a boxing match", "a birthday party", "walking the dog", "waiting for a bus"---whose image instantiations are linked more by their common spatial and semantic structure than by low-level visual similarity. Our system combines given and learned knowledge of the structure of a particular situation, and adapts that knowledge to a new situation instance as it actively searches for objects. More specifically, the system learns a set of probability distributions describing spatial and other relationships among relevant objects. The system uses those distributions to iteratively sample object proposals on a test image, but also continually uses information from those object proposals to adaptively modify the distributions based on what the system has detected. We test our approach's ability to efficiently localize objects, using a situation-specific image dataset created by our group. We compare the results with several baselines and variations on our method, and demonstrate the strong benefit of using situation knowledge and active context-driven localization. Finally, we contrast our method with several other approaches that use context as well as active search for object localization in images.