 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Visual Grounding
Apr 03, 2019


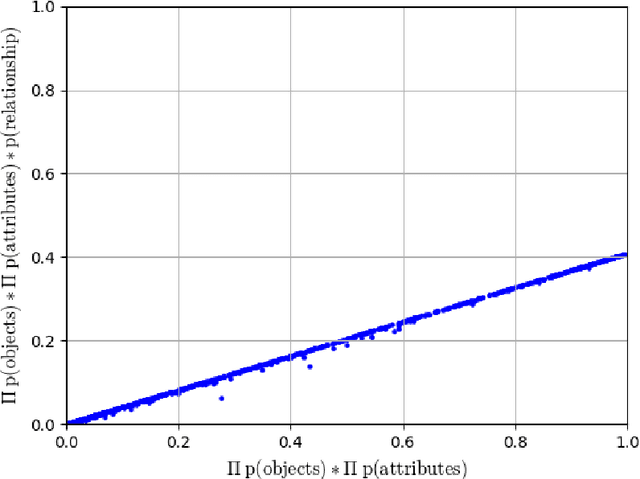
We revisit a particular visual grounding method: the "Image Retrieval Using Scene Graphs" (IRSG) system of Johnson et al. (2015). Our experiments indicate that the system does not effectively use its learned object-relationship models. We also look closely at the IRSG dataset, as well as the widely used Visual Relationship Dataset (VRD) that is adapted from it. We find that these datasets exhibit biases that allow methods that ignore relationships to perform relatively well. We also describe several other problems with the IRSG dataset, and report on experiments using a subset of the dataset in which the biases and other problems are removed. Our studies contribute to a more general effort: that of better understanding what machine learning methods that combine language and vision actually learn and what popular datasets actually test.
Semantic Image Retrieval via Active Grounding of Visual Situations
Oct 31, 2017

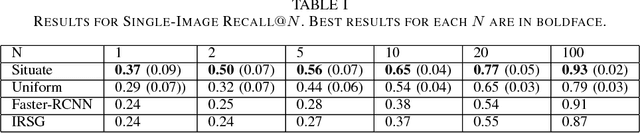
We describe a novel architecture for semantic image retrieval---in particular, retrieval of instances of visual situations. Visual situations are concepts such as "a boxing match," "walking the dog," "a crowd waiting for a bus," or "a game of ping-pong," whose instantiations in images are linked more by their common spatial and semantic structure than by low-level visual similarity. Given a query situation description, our architecture---called Situate---learns models capturing the visual features of expected objects as well the expected spatial configuration of relationships among objects. Given a new image, Situate uses these models in an attempt to ground (i.e., to create a bounding box locating) each expected component of the situation in the image via an active search procedure. Situate uses the resulting grounding to compute a score indicating the degree to which the new image is judged to contain an instance of the situation. Such scores can be used to rank images in a collection as part of a retrieval system. In the preliminary study described here, we demonstrate the promise of this system by comparing Situate's performance with that of two baseline methods, as well as with a related semantic image-retrieval system based on "scene graphs."