 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Fidelity Interactive Video Segmentation Using Tensor Decomposition Boundary Loss Convolutional Tessellations and Context Aware Skip Connections
Paper and Code
Nov 23, 2020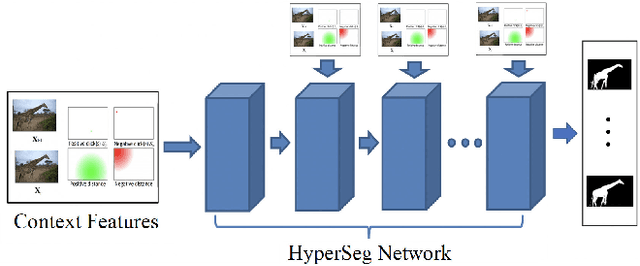


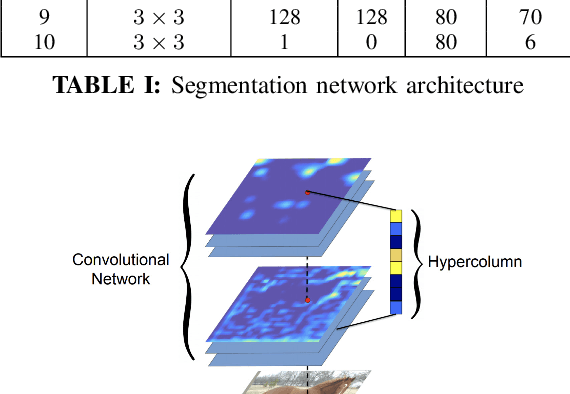
We provide a high fidelity deep learning algorithm (HyperSeg) for interactive video segmentation tasks using a convolutional network with context-aware skip connections, and compressed, hypercolumn image features combined with a convolutional tessellation procedure. In order to maintain high output fidelity, our model crucially processes and renders all image features in high resolution, without utilizing downsampling or pooling procedures. We maintain this consistent, high grade fidelity efficiently in our model chiefly through two means: (1) We use a statistically-principled tensor decomposition procedure to modulate the number of hypercolumn features and (2) We render these features in their native resolution using a convolutional tessellation technique. For improved pixel level segmentation results, we introduce a boundary loss function; for improved temporal coherence in video data, we include temporal image information in our model. Through experiments, we demonstrate the improved accuracy of our model against baseline models for interactive segmentation tasks using high resolution video data. We also introduce a benchmark video segmentation dataset, the VFX Segmentation Dataset, which contains over 27,046 high resolution video frames, including greenscreen and various composited scenes with corresponding, hand crafted, pixel level segmentations. Our work presents an extension to improvement to state of the art segmentation fidelity with high resolution data and can be used across a broad range of application domains, including VFX pipelines and medical imaging disciplines.