 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Deep Learning Approach to Derive Cytokeratin Expression and Epithelium Segmentation from DAPI
Aug 16, 2022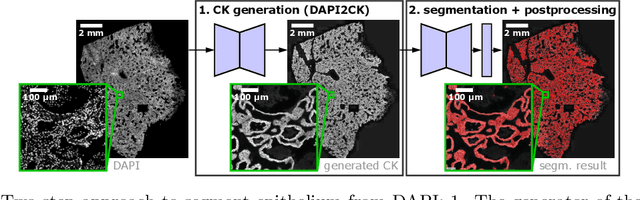

Generative Adversarial Networks (GANs) are state of the art for image synthesis. Here, we present dapi2ck, a novel GAN-based approach to synthesize cytokeratin (CK) staining from immunofluorescent (IF) DAPI staining of nuclei in non-small cell lung cancer (NSCLC) images. We use the synthetic CK to segment epithelial regions, which, compared to expert annotations, yield equally good results as segmentation on stained CK. Considering the limited number of markers in a multiplexed IF (mIF) panel, our approach allows to replace CK by another marker addressing the complexity of the tumor micro-environment (TME) to facilitate patient selection for immunotherapies. In contrast to stained CK, dapi2ck does not suffer from issues like unspecific CK staining or loss of tumoral CK expression.
Stain Isolation-based Guidance for Improved Stain Translation
Jun 28, 2022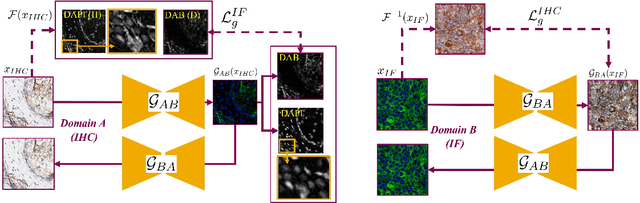
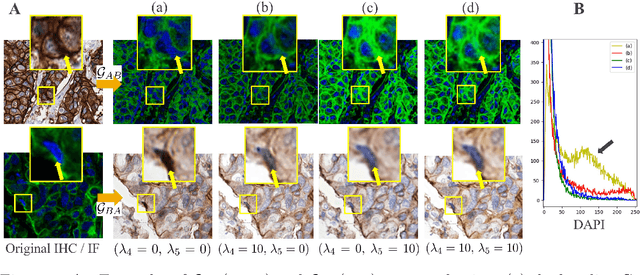
Unsupervised and unpaired domain translation using generative adversarial neural networks, and more precisely CycleGAN, is state of the art for the stain translation of histopathology images. It often, however, suffers from the presence of cycle-consistent but non structure-preserving errors. We propose an alternative approach to the set of methods which, relying on segmentation consistency, enable the preservation of pathology structures. Focusing on immunohistochemistry (IHC) and multiplexed immunofluorescence (mIF), we introduce a simple yet effective guidance scheme as a loss function that leverages the consistency of stain translation with stain isolation. Qualitative and quantitative experiments show the ability of the proposed approach to improve translation between the two domains.
Domain Adaptation-based Augmentation for Weakly Supervised Nuclei Detection
Jul 10, 2019
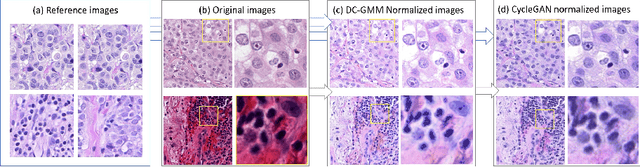
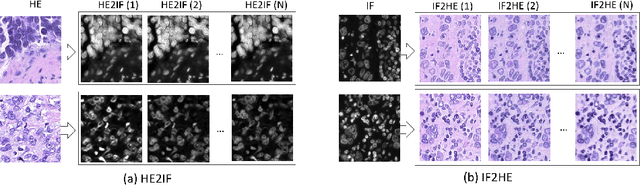
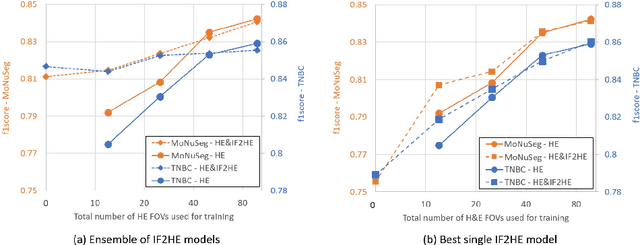
The detection of nuclei is one of the most fundamental components of computational pathology. Current state-of-the-art methods are based on deep learning, with the prerequisite that extensive labeled datasets are available. The increasing number of patient cohorts to be analyzed, the diversity of tissue stains and indications, as well as the cost of dataset labeling motivates the development of novel methods to reduce labeling effort across domains. We introduce in this work a weakly supervised 'inter-domain' approach that (i) performs stain normalization and unpaired image-to-image translation to transform labeled images on a source domain to synthetic labeled images on an unlabeled target domain and (ii) uses the resulting synthetic labeled images to train a detection network on the target domain. Extensive experiments show the superiority of the proposed approach against the state-of-the-art 'intra-domain' detection based on fully-supervised learning.
DASGAN -- Joint Domain Adaptation and Segmentation for the Analysis of Epithelial Regions in Histopathology PD-L1 Images
Jun 26, 2019



The analysis of the tumor environment on digital histopathology slides is becoming key for the understanding of the immune response against cancer, supporting the development of novel immuno-therapies. We introduce here a novel deep learning solution to the related problem of tumor epithelium segmentation. While most existing deep learning segmentation approaches are trained on time-consuming and costly manual annotation on single stain domain (PD-L1), we leverage here semi-automatically labeled images from a second stain domain (Cytokeratin-CK). We introduce an end-to-end trainable network that jointly segment tumor epithelium on PD-L1 while leveraging unpaired image-to-image translation between CK and PD-L1, therefore completely bypassing the need for serial sections or re-staining of slides. Extending the method to differentiate between PD-L1 positive and negative tumor epithelium regions enables the automated estimation of the PD-L1 Tumor Cell (TC) score. Quantitative experimental results demonstrate the accuracy of our approach against state-of-the-art segmentation methods.
Deep Semi Supervised Generative Learning for Automated PD-L1 Tumor Cell Scoring on NSCLC Tissue Needle Biopsies
Jun 28, 2018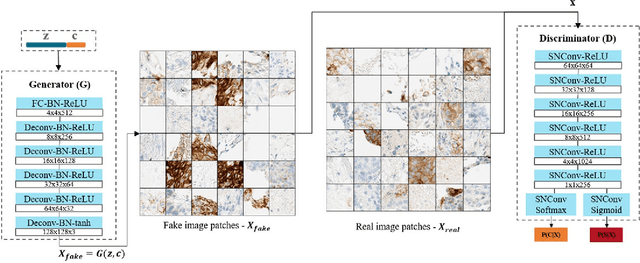
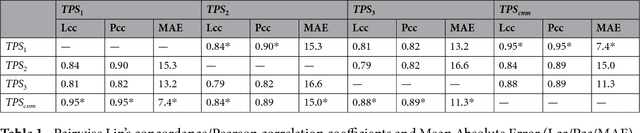

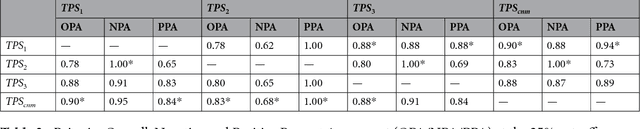
The level of PD-L1 expression in immunohistochemistry (IHC) assays is a key biomarker for the identification of Non-Small-Cell-Lung-Cancer (NSCLC) patients that may respond to anti PD-1/PD-L1 treatments. The quantification of PD-L1 expression currently includes the visual estimation of a Tumor Cell (TC) score by a pathologist and consists of evaluating the ratio of PD-L1 positive and PD-L1 negative tumor cells. Known challenges like differences in positivity estimation around clinically relevant cut-offs and sub-optimal quality of samples makes visual scoring tedious and subjective, yielding a scoring variability between pathologists. In this work, we propose a novel deep learning solution that enables the first automated and objective scoring of PD-L1 expression in late stage NSCLC needle biopsies. To account for the low amount of tissue available in biopsy images and to restrict the amount of manual annotations necessary for training, we explore the use of semi-supervised approaches against standard fully supervised methods. We consolidate the manual annotations used for training as well the visual TC scores used for quantitative evaluation with multiple pathologists. Concordance measures computed on a set of slides unseen during training provide evidence that our automatic scoring method matches visual scoring on the considered dataset while ensuring repeatability and objectivity.
Learning without Prejudice: Avoiding Bias in Webly-Supervised Action Recognition
Jun 14, 2017
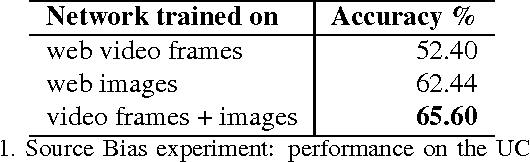
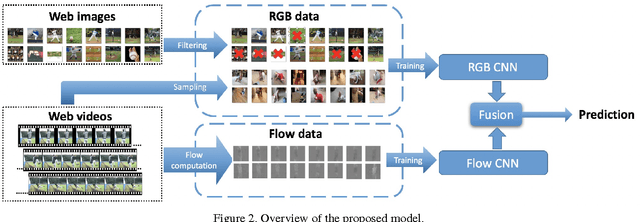

Webly-supervised learning has recently emerged as an alternative paradigm to traditional supervised learning based on large-scale datasets with manual annotations. The key idea is that models such as CNNs can be learned from the noisy visual data available on the web. In this work we aim to exploit web data for video understanding tasks such as action recognition and detection. One of the main problems in webly-supervised learning is cleaning the noisy labeled data from the web. The state-of-the-art paradigm relies on training a first classifier on noisy data that is then used to clean the remaining dataset. Our key insight is that this procedure biases the second classifier towards samples that the first one understands. Here we train two independent CNNs, a RGB network on web images and video frames and a second network using temporal information from optical flow. We show that training the networks independently is vastly superior to selecting the frames for the flow classifier by using our RGB network. Moreover, we show benefits in enriching the training set with different data sources from heterogeneous public web databases. We demonstrate that our framework outperforms all other webly-supervised methods on two public benchmarks, UCF-101 and Thumos'14.