 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ontoverse: Democratising Access to Knowledge Graph-based Data Through a Cartographic Interface
Jul 22, 2024As the number of scientific publications and preprints is growing exponentially, several attempts have been made to navigate this complex and increasingly detailed landscape. These have almost exclusively taken unsupervised approaches that fail to incorporate domain knowledge and lack the structural organisation required for intuitive interactive human exploration and discovery. Especially in highly interdisciplinary fields, a deep understanding of the connectedness of research works across topics is essential for generating insights. We have developed a unique approach to data navigation that leans on geographical visualisation and uses hierarchically structured domain knowledge to enable end-users to explore knowledge spaces grounded in their desired domains of interest. This can take advantage of existing ontologies, proprietary intelligence schemata, or be directly derived from the underlying data through hierarchical topic modelling. Our approach uses natural language processing techniques to extract named entities from the underlying data and normalise them against relevant domain references and navigational structures. The knowledge is integrated by first calculating similarities between entities based on their shared extracted feature space and then by alignment to the navigational structures. The result is a knowledge graph that allows for full text and semantic graph query and structured topic driven navigation. This allows end-users to identify entities relevant to their needs and access extensive graph analytics. The user interface facilitates graphical interaction with the underlying knowledge graph and mimics a cartographic map to maximise ease of use and widen adoption. We demonstrate an exemplar project using our generalisable and scalable infrastructure for an academic biomedical literature corpus that is grounded against hundreds of different named domain entities.
Auxiliary CycleGAN-guidance for Task-Aware Domain Translation from Duplex to Monoplex IHC Images
Mar 12, 2024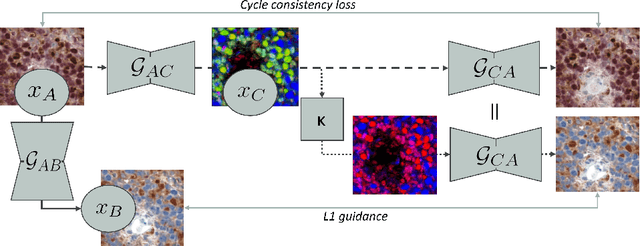

Generative models enable the translation from a source image domain where readily trained models are available to a target domain unseen during training. While Cycle Generative Adversarial Networks (GANs) are well established, the associated cycle consistency constrain relies on that an invertible mapping exists between the two domains. This is, however, not the case for the translation between images stained with chromogenic monoplex and duplex immunohistochemistry (IHC) assays. Focusing on the translation from the latter to the first, we propose - through the introduction of a novel training design, an alternative constrain leveraging a set of immunofluorescence (IF) images as an auxiliary unpaired image domain. Quantitative and qualitative results on a downstream segmentation task show the benefit of the proposed method in comparison to baseline approaches.
Novel Deep Learning Approach to Derive Cytokeratin Expression and Epithelium Segmentation from DAPI
Aug 16, 2022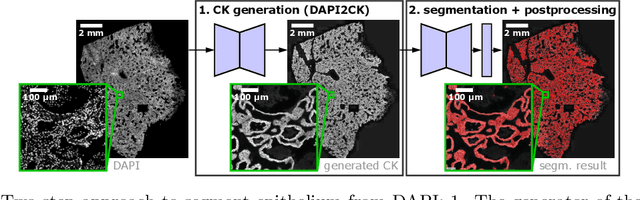

Generative Adversarial Networks (GANs) are state of the art for image synthesis. Here, we present dapi2ck, a novel GAN-based approach to synthesize cytokeratin (CK) staining from immunofluorescent (IF) DAPI staining of nuclei in non-small cell lung cancer (NSCLC) images. We use the synthetic CK to segment epithelial regions, which, compared to expert annotations, yield equally good results as segmentation on stained CK. Considering the limited number of markers in a multiplexed IF (mIF) panel, our approach allows to replace CK by another marker addressing the complexity of the tumor micro-environment (TME) to facilitate patient selection for immunotherapies. In contrast to stained CK, dapi2ck does not suffer from issues like unspecific CK staining or loss of tumoral CK expression.
Domain Adaptation-based Augmentation for Weakly Supervised Nuclei Detection
Jul 10, 2019
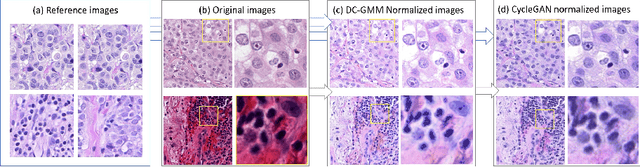
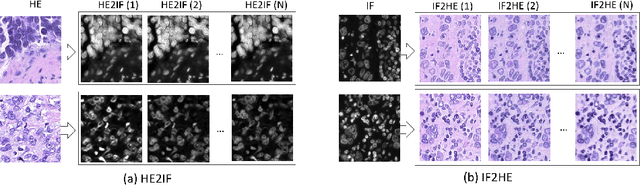
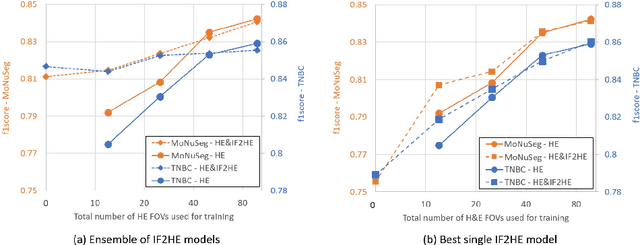
The detection of nuclei is one of the most fundamental components of computational pathology. Current state-of-the-art methods are based on deep learning, with the prerequisite that extensive labeled datasets are available. The increasing number of patient cohorts to be analyzed, the diversity of tissue stains and indications, as well as the cost of dataset labeling motivates the development of novel methods to reduce labeling effort across domains. We introduce in this work a weakly supervised 'inter-domain' approach that (i) performs stain normalization and unpaired image-to-image translation to transform labeled images on a source domain to synthetic labeled images on an unlabeled target domain and (ii) uses the resulting synthetic labeled images to train a detection network on the target domain. Extensive experiments show the superiority of the proposed approach against the state-of-the-art 'intra-domain' detection based on fully-supervised learning.
Deep Semi Supervised Generative Learning for Automated PD-L1 Tumor Cell Scoring on NSCLC Tissue Needle Biopsies
Jun 28, 2018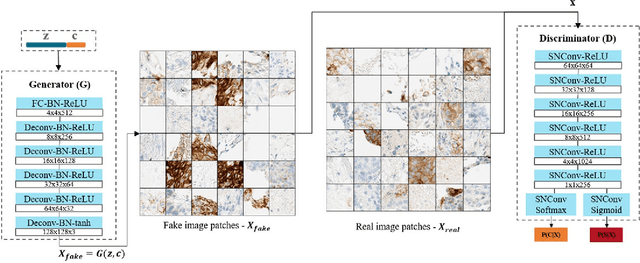
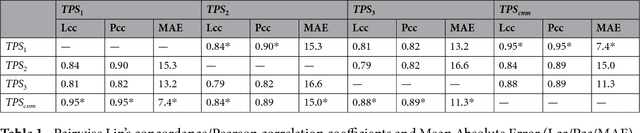

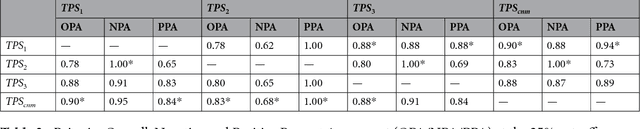
The level of PD-L1 expression in immunohistochemistry (IHC) assays is a key biomarker for the identification of Non-Small-Cell-Lung-Cancer (NSCLC) patients that may respond to anti PD-1/PD-L1 treatments. The quantification of PD-L1 expression currently includes the visual estimation of a Tumor Cell (TC) score by a pathologist and consists of evaluating the ratio of PD-L1 positive and PD-L1 negative tumor cells. Known challenges like differences in positivity estimation around clinically relevant cut-offs and sub-optimal quality of samples makes visual scoring tedious and subjective, yielding a scoring variability between pathologists. In this work, we propose a novel deep learning solution that enables the first automated and objective scoring of PD-L1 expression in late stage NSCLC needle biopsies. To account for the low amount of tissue available in biopsy images and to restrict the amount of manual annotations necessary for training, we explore the use of semi-supervised approaches against standard fully supervised methods. We consolidate the manual annotations used for training as well the visual TC scores used for quantitative evaluation with multiple pathologists. Concordance measures computed on a set of slides unseen during training provide evidence that our automatic scoring method matches visual scoring on the considered dataset while ensuring repeatability and objectivity.