 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation-based Augmentation for Weakly Supervised Nuclei Detection
Jul 10, 2019
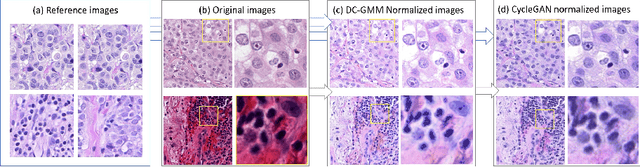
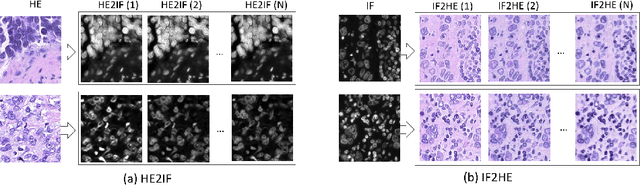
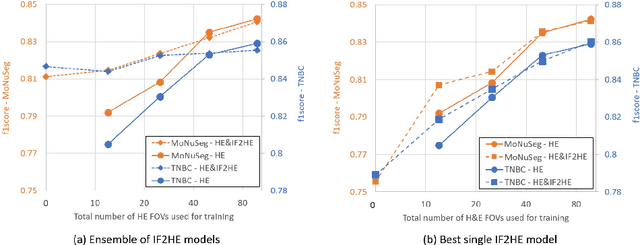
The detection of nuclei is one of the most fundamental components of computational pathology. Current state-of-the-art methods are based on deep learning, with the prerequisite that extensive labeled datasets are available. The increasing number of patient cohorts to be analyzed, the diversity of tissue stains and indications, as well as the cost of dataset labeling motivates the development of novel methods to reduce labeling effort across domains. We introduce in this work a weakly supervised 'inter-domain' approach that (i) performs stain normalization and unpaired image-to-image translation to transform labeled images on a source domain to synthetic labeled images on an unlabeled target domain and (ii) uses the resulting synthetic labeled images to train a detection network on the target domain. Extensive experiments show the superiority of the proposed approach against the state-of-the-art 'intra-domain' detection based on fully-supervised learning.
Deep Semi Supervised Generative Learning for Automated PD-L1 Tumor Cell Scoring on NSCLC Tissue Needle Biopsies
Jun 28, 2018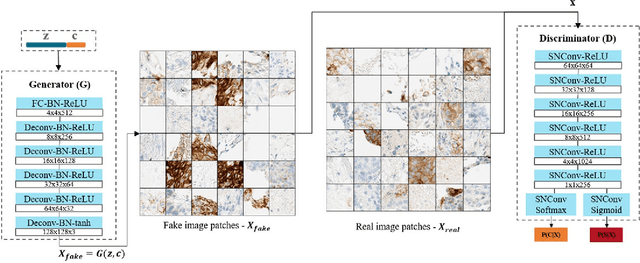
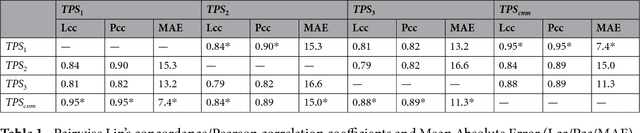

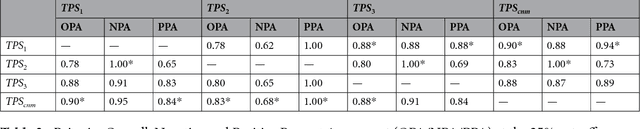
The level of PD-L1 expression in immunohistochemistry (IHC) assays is a key biomarker for the identification of Non-Small-Cell-Lung-Cancer (NSCLC) patients that may respond to anti PD-1/PD-L1 treatments. The quantification of PD-L1 expression currently includes the visual estimation of a Tumor Cell (TC) score by a pathologist and consists of evaluating the ratio of PD-L1 positive and PD-L1 negative tumor cells. Known challenges like differences in positivity estimation around clinically relevant cut-offs and sub-optimal quality of samples makes visual scoring tedious and subjective, yielding a scoring variability between pathologists. In this work, we propose a novel deep learning solution that enables the first automated and objective scoring of PD-L1 expression in late stage NSCLC needle biopsies. To account for the low amount of tissue available in biopsy images and to restrict the amount of manual annotations necessary for training, we explore the use of semi-supervised approaches against standard fully supervised methods. We consolidate the manual annotations used for training as well the visual TC scores used for quantitative evaluation with multiple pathologists. Concordance measures computed on a set of slides unseen during training provide evidence that our automatic scoring method matches visual scoring on the considered dataset while ensuring repeatability and objectivity.