 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Driving from Natural Language Instructions
Oct 16, 2019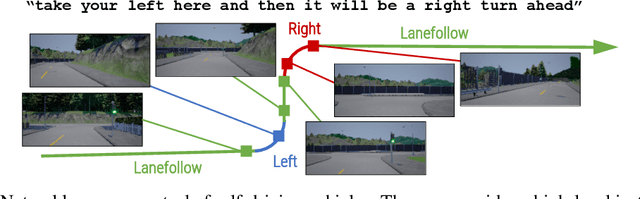
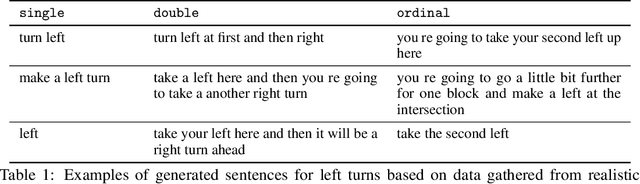
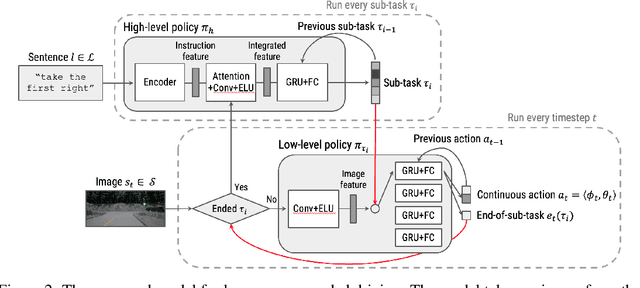
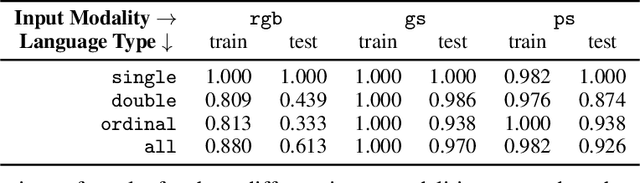
Widespread adoption of self-driving cars will depend not only on their safety but largely on their ability to interact with human users. Just like human drivers, self-driving cars will be expected to understand and safely follow natural-language directions that suddenly alter the pre-planned route according to user's preference or in presence of ambiguities, particularly in locations with poor or outdated map coverage. To this end, we propose a language-grounded driving agent implementing a hierarchical policy using recurrent layers and gated attention. The hierarchical approach enables us to reason both in terms of high-level language instructions describing long time horizons and low-level, complex, continuous state/action spaces required for real-time control of a self-driving car. We train our policy with conditional imitation learning from realistic language data collected from human drivers and navigators. Through quantitative and interactive experiments within the CARLA framework, we show that our model can successfully interpret language instructions and follow them safely, even when generalizing to previously unseen environments. Code and video are available at https://sites.google.com/view/language-grounded-driving.
From Pixels to Buildings: End-to-end Probabilistic Deep Networks for Large-scale Semantic Mapping
Mar 04, 2019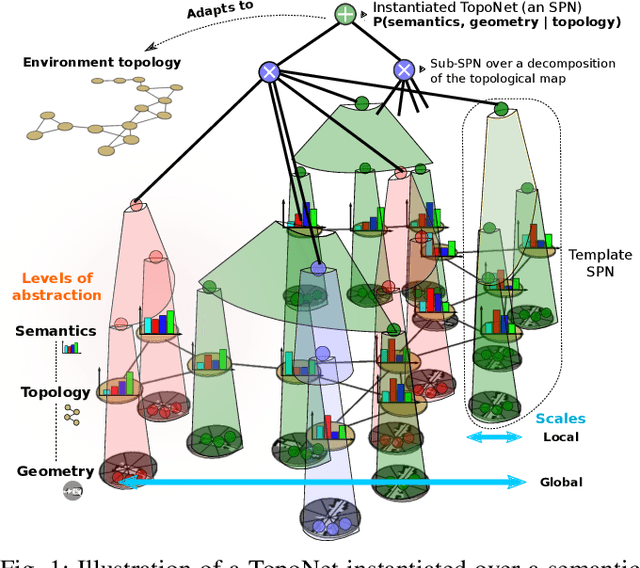

We introduce TopoNets, end-to-end probabilistic deep networks for modeling semantic maps with structure reflecting the topology of large-scale environments. TopoNets build a unified deep network spanning multiple levels of abstraction and spatial scales, from pixels representing geometry of local places to high-level descriptions of semantics of buildings. To this end, TopoNets leverage complex spatial relations expressed in terms of arbitrary, dynamic graphs. We demonstrate how TopoNets can be used to perform end-to-end semantic mapping from partial sensory observations and noisy topological relations discovered by a robot exploring large-scale office spaces. Thanks to their probabilistic nature and generative properties, TopoNets extend the problem of semantic mapping beyond classification. We show that TopoNets successfully perform uncertain reasoning about yet unexplored space and detect novel and incongruent environment configurations unknown to the robot. Our implementation of TopoNets achieves real-time tractable and exact inference, which makes this new class of deep models a promising practical solution to comprehensive spatial understanding for mobile robots.
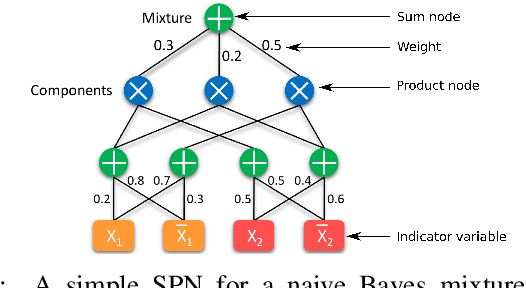
Deep Convolutional Sum-Product Networks for Probabilistic Image Representations
Feb 16, 2019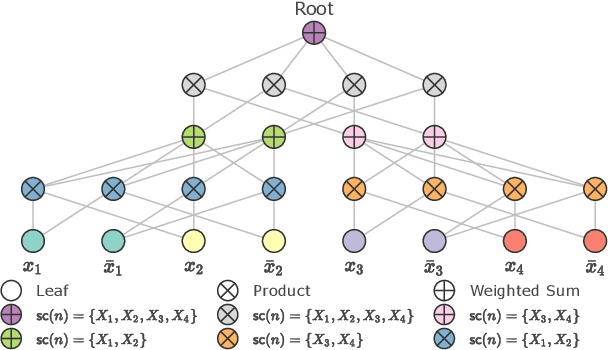
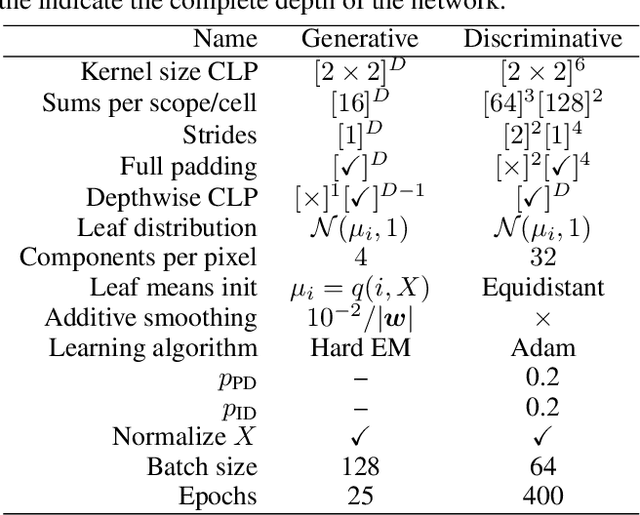
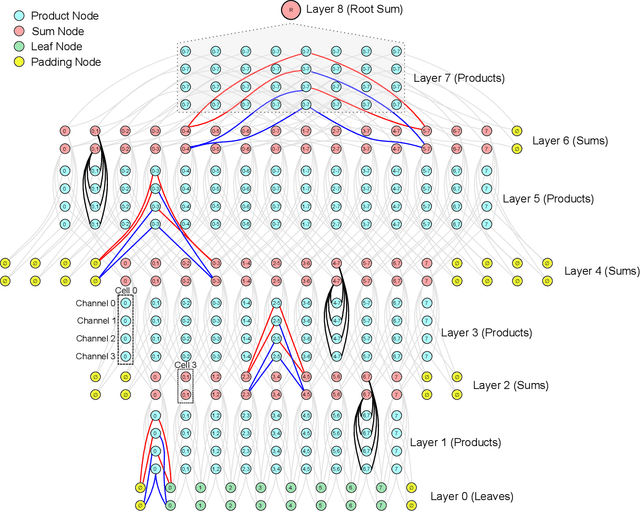
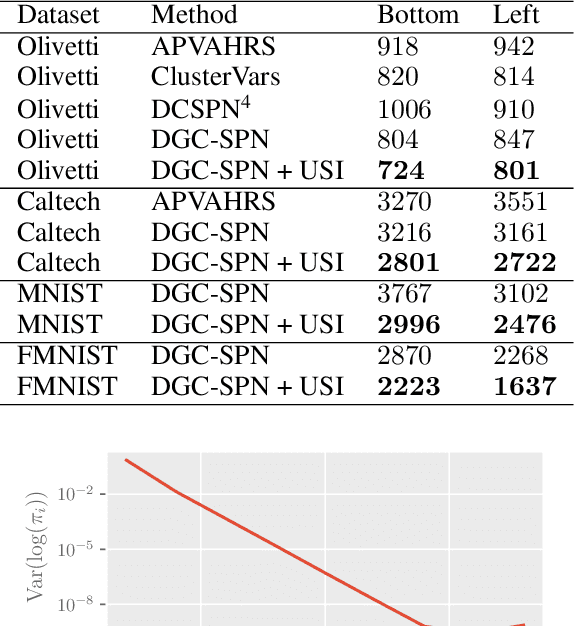
Sum-Product Networks (SPNs) are hierarchical probabilistic graphical models capable of fast and exact inference. Applications of SPNs to real-world data such as large image datasets has been fairly limited in previous literature. We introduce Convolutional Sum-Product Networks (ConvSPNs) which exploit the inherent structure of images in a way similar to deep convolutional neural networks, optionally with weight sharing. ConvSPNs encode spatial relationships through local products and local sum operations. ConvSPNs obtain state-of-the-art results compared to other SPN-based approaches on several visual datasets, including color images, for both generative as well as discriminative tasks. ConvSPNs are the first pure-SPN models applied to color images that do not depend on additional techniques for feature extraction. In addition, we introduce two novel methods for regularizing SPNs trained with hard EM. Both regularization methods have been motivated by observing an exponentially decreasing variance of log probabilities with respect to the depth of randomly structured SPNs. We show that our regularization provides substantial further improvements in generative visual tasks.
Learning Deep Generative Spatial Models for Mobile Robots
Dec 28, 2017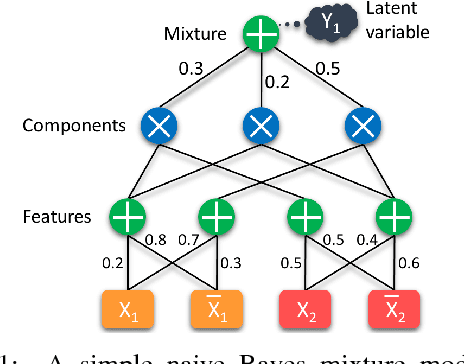



We propose a new probabilistic framework that allows mobile robots to autonomously learn deep, generative models of their environments that span multiple levels of abstraction. Unlike traditional approaches that combine engineered models for low-level features, geometry, and semantics, our approach leverages recent advances in Sum-Product Networks (SPNs) and deep learning to learn a single, universal model of the robot's spatial environment. Our model is fully probabilistic and generative, and represents a joint distribution over spatial information ranging from low-level geometry to semantic interpretations. Once learned, it is capable of solving a wide range of tasks: from semantic classification of places, uncertainty estimation, and novelty detection, to generation of place appearances based on semantic information and prediction of missing data in partial observations. Experiments on laser-range data from a mobile robot show that the proposed universal model obtains performance superior to state-of-the-art models fine-tuned to one specific task, such as Generative Adversarial Networks (GANs) or SVMs.
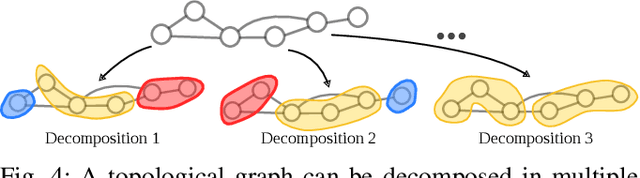
Learning Graph-Structured Sum-Product Networks for Probabilistic Semantic Maps
Nov 22, 2017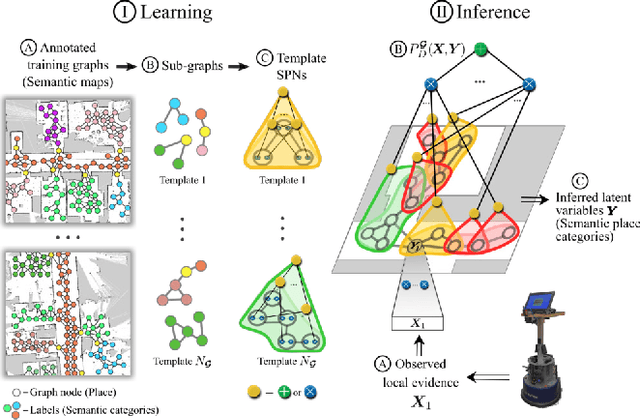
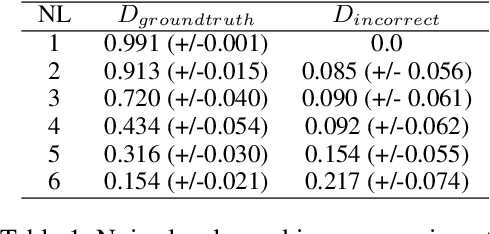
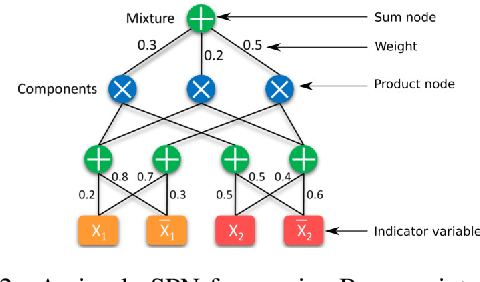
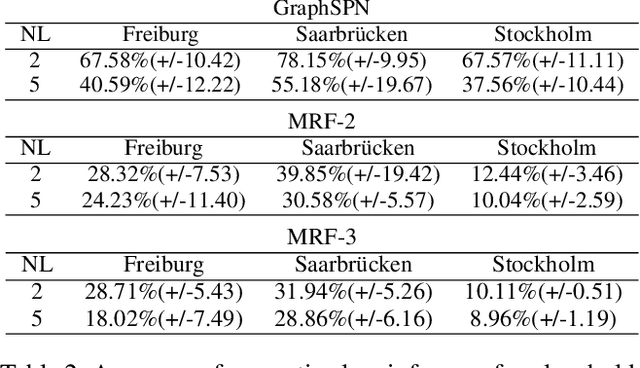
We introduce Graph-Structured Sum-Product Networks (GraphSPNs), a probabilistic approach to structured prediction for problems where dependencies between latent variables are expressed in terms of arbitrary, dynamic graphs. While many approaches to structured prediction place strict constraints on the interactions between inferred variables, many real-world problems can be only characterized using complex graph structures of varying size, often contaminated with noise when obtained from real data. Here, we focus on one such problem in the domain of robotics. We demonstrate how GraphSPNs can be used to bolster inference about semantic, conceptual place descriptions using noisy topological relations discovered by a robot exploring large-scale office spaces. Through experiments, we show that GraphSPNs consistently outperform the traditional approach based on undirected graphical models, successfully disambiguating information in global semantic maps built from uncertain, noisy local evidence. We further exploit the probabilistic nature of the model to infer marginal distributions over semantic descriptions of as yet unexplored places and detect spatial environment configurations that are novel and incongruent with the known evidence.