 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Database Guidance for Motion Planning
Apr 07, 2025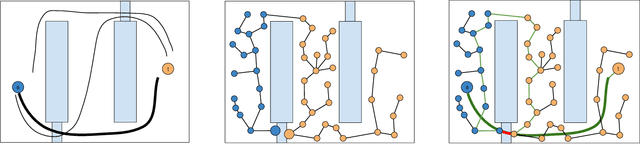

One approach to using prior experience in robot motion planning is to store solutions to previously seen problems in a database of paths. Methods that use such databases are characterized by how they query for a path and how they use queries given a new problem. In this work we present a new method, Path Database Guidance (PDG), which innovates on existing work in two ways. First, we use the database to compute a heuristic for determining which nodes of a search tree to expand, in contrast to prior work which generally pastes the (possibly transformed) queried path or uses it to bias a sampling distribution. We demonstrate that this makes our method more easily composable with other search methods by dynamically interleaving exploration according to a baseline algorithm with exploitation of the database guidance. Second, in contrast to other methods that treat the database as a single fixed prior, our database (and thus our queried heuristic) updates as we search the implicitly defined robot configuration space. We experimentally demonstrate the effectiveness of PDG in a variety of explicitly defined environment distributions in simulation.
A Framework for Guided Motion Planning
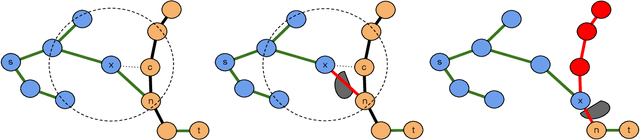
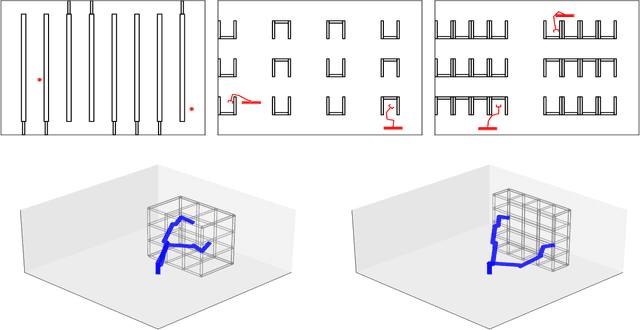
Apr 04, 2024Randomized sampling based algorithms are widely used in robot motion planning due to the problem's intractability, and are experimentally effective on a wide range of problem instances. Most variants bias their sampling using various heuristics related to the known underlying structure of the search space. In this work, we formalize the intuitive notion of guided search by defining the concept of a guiding space. This new language encapsulates many seemingly distinct prior methods under the same framework, and allows us to reason about guidance, a previously obscured core contribution of different algorithms. We suggest an information theoretic method to evaluate guidance, which experimentally matches intuition when tested on known algorithms in a variety of environments. The language and evaluation of guidance suggests improvements to existing methods, and allows for simple hybrid algorithms that combine guidance from multiple sources.
Evaluating Guiding Spaces for Motion Planning
Oct 16, 2022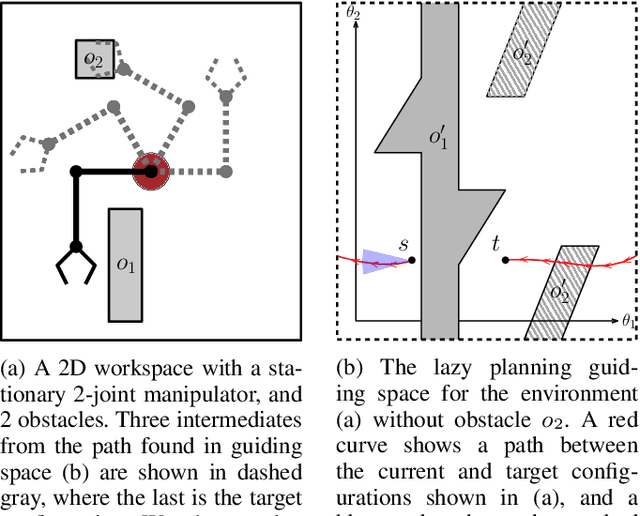
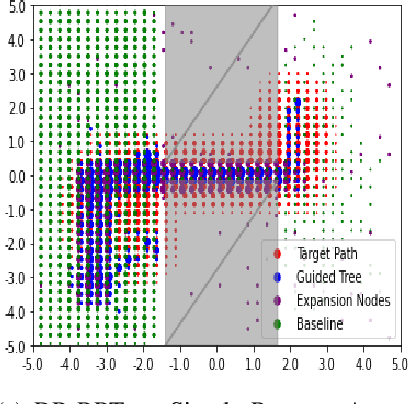
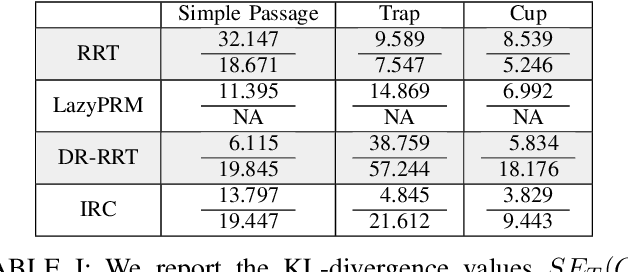
Randomized sampling based algorithms are widely used in robot motion planning due to the problem's intractability, and are experimentally effective on a wide range of problem instances. Most variants do not sample uniformly at random, and instead bias their sampling using various heuristics for determining which samples will provide more information, or are more likely to participate in the final solution. In this work, we define the \emph{motion planning guiding space}, which encapsulates many seemingly distinct prior works under the same framework. In addition, we suggest an information theoretic method to evaluate guided planning which places the focus on the quality of the resulting biased sampling. Finally, we analyze several motion planning algorithms in order to demonstrate the applicability of our definition and its evaluation.
Discrete State-Action Abstraction via the Successor Representation
Jun 07, 2022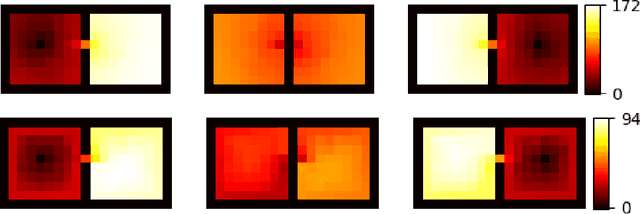
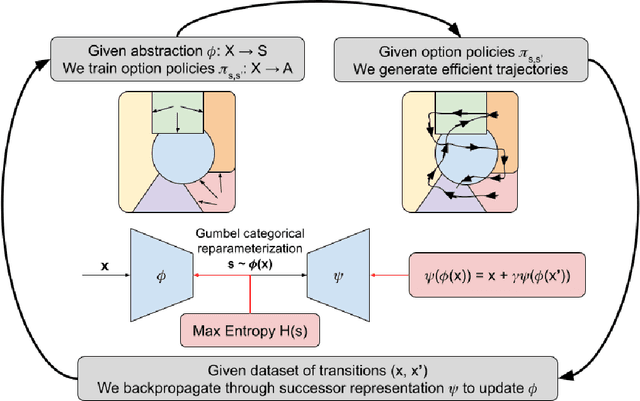
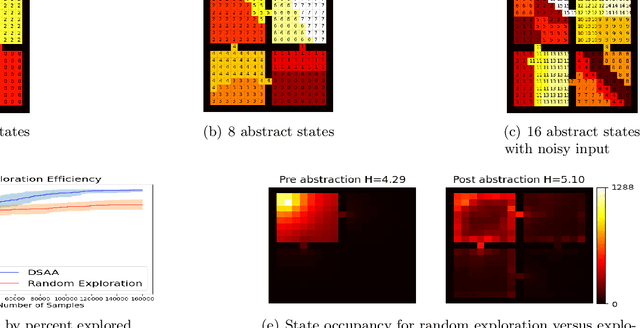
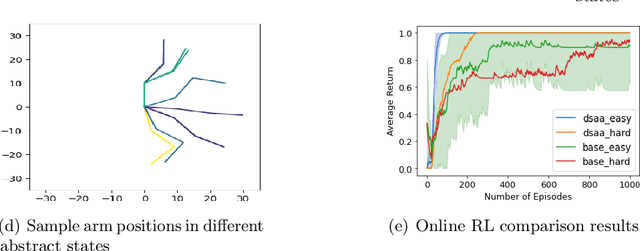
When reinforcement learning is applied with sparse rewards, agents must spend a prohibitively long time exploring the unknown environment without any learning signal. Abstraction is one approach that provides the agent with an intrinsic reward for transitioning in a latent space. Prior work focuses on dense continuous latent spaces, or requires the user to manually provide the representation. Our approach is the first for automatically learning a discrete abstraction of the underlying environment. Moreover, our method works on arbitrary input spaces, using an end-to-end trainable regularized successor representation model. For transitions between abstract states, we train a set of temporally extended actions in the form of options, i.e., an action abstraction. Our proposed algorithm, Discrete State-Action Abstraction (DSAA), iteratively swaps between training these options and using them to efficiently explore more of the environment to improve the state abstraction. As a result, our model is not only useful for transfer learning but also in the online learning setting. We empirically show that our agent is able to explore the environment and solve provided tasks more efficiently than baseline reinforcement learning algorithms. Our code is publicly available at \url{https://github.com/amnonattali/dsaa}.