 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist vs Specialist Time Series Foundation Models: Investigating Potential Emergent Behaviors in Assessing Human Health Using PPG Signals
Oct 16, 2025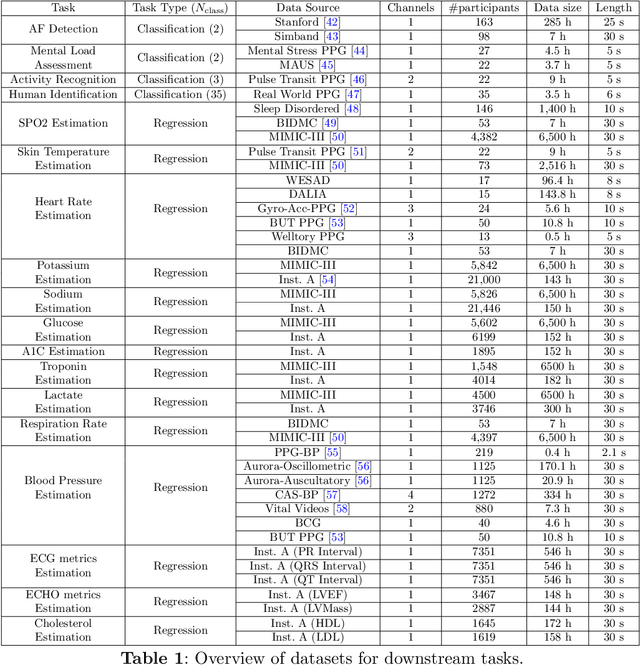
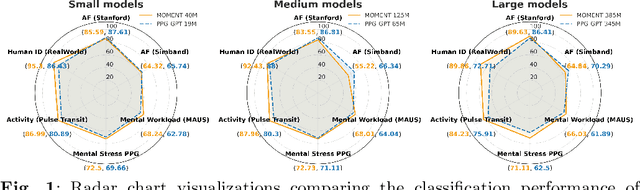
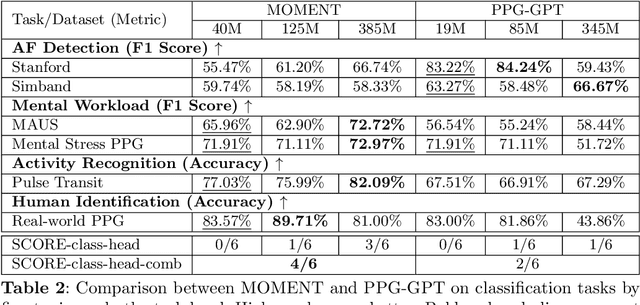
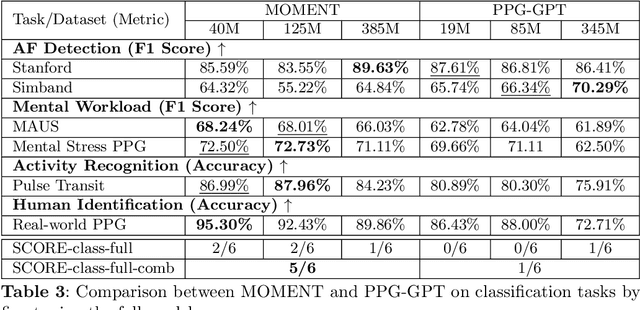
Foundation models are large-scale machine learning models that are pre-trained on massive amounts of data and can be adapted for various downstream tasks. They have been extensively applied to tasks in Natural Language Processing and Computer Vision with models such as GPT, BERT, and CLIP. They are now also increasingly gaining attention in time-series analysis, particularly for physiological sensing. However, most time series foundation models are specialist models - with data in pre-training and testing of the same type, such as Electrocardiogram, Electroencephalogram, and Photoplethysmogram (PPG). Recent works, such as MOMENT, train a generalist time series foundation model with data from multiple domains, such as weather, traffic, and electricity. This paper aims to conduct a comprehensive benchmarking study to compare the performance of generalist and specialist models, with a focus on PPG signals. Through an extensive suite of total 51 tasks covering cardiac state assessment, laboratory value estimation, and cross-modal inference, we comprehensively evaluate both models across seven dimensions, including win score, average performance, feature quality, tuning gain, performance variance, transferability, and scalability. These metrics jointly capture not only the models' capability but also their adaptability, robustness, and efficiency under different fine-tuning strategies, providing a holistic understanding of their strengths and limitations for diverse downstream scenarios. In a full-tuning scenario, we demonstrate that the specialist model achieves a 27% higher win score. Finally, we provide further analysis on generalization, fairness, attention visualizations, and the importance of training data choice.
SiamAF: Learning Shared Information from ECG and PPG Signals for Robust Atrial Fibrillation Detection
Oct 13, 2023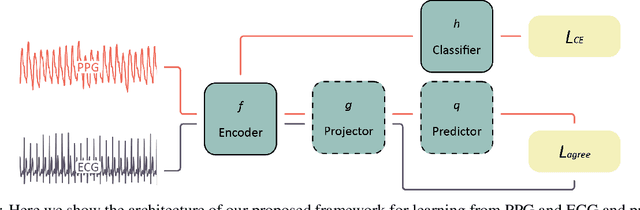
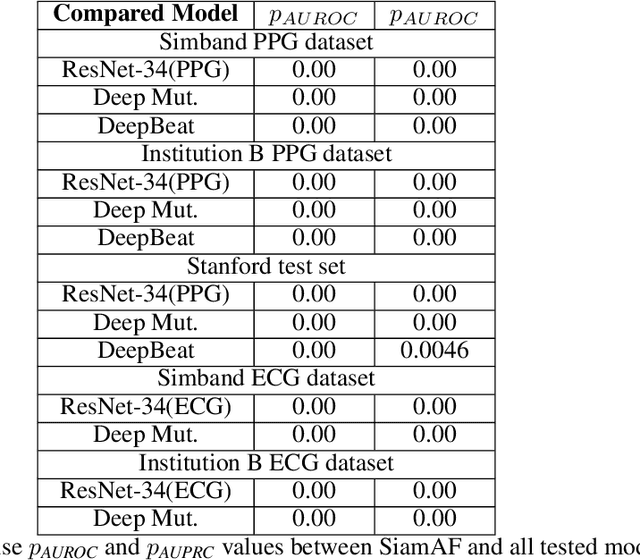
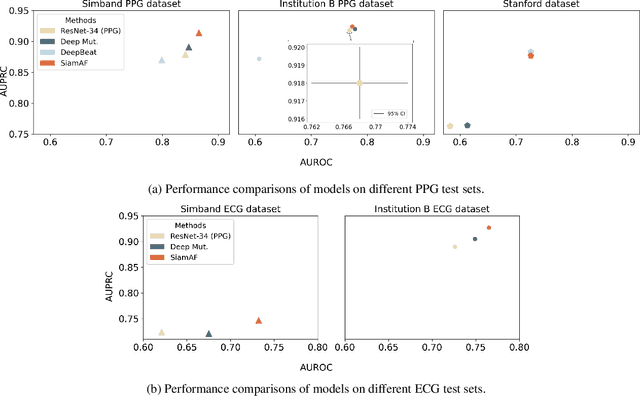
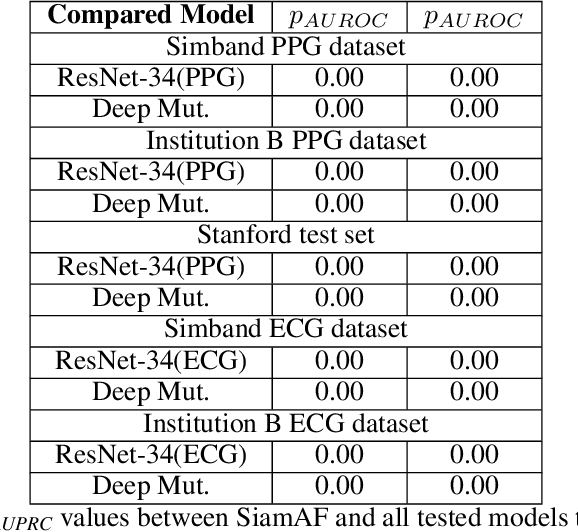
Atrial fibrillation (AF) is the most common type of cardiac arrhythmia. It is associated with an increased risk of stroke, heart failure, and other cardiovascular complications, but can be clinically silent. Passive AF monitoring with wearables may help reduce adverse clinical outcomes related to AF. Detecting AF in noisy wearable data poses a significant challenge, leading to the emergence of various deep learning techniques. Previous deep learning models learn from a single modality, either electrocardiogram (ECG) or photoplethysmography (PPG) signals. However, deep learning models often struggle to learn generalizable features and rely on features that are more susceptible to corruption from noise, leading to sub-optimal performances in certain scenarios, especially with low-quality signals. Given the increasing availability of ECG and PPG signal pairs from wearables and bedside monitors, we propose a new approach, SiamAF, leveraging a novel Siamese network architecture and joint learning loss function to learn shared information from both ECG and PPG signals. At inference time, the proposed model is able to predict AF from either PPG or ECG and outperforms baseline methods on three external test sets. It learns medically relevant features as a result of our novel architecture design. The proposed model also achieves comparable performance to traditional learning regimes while requiring much fewer training labels, providing a potential approach to reduce future reliance on manual labeling.
Cluster consistency: Simple yet effect robust learning algorithm on large-scale photoplethysmography for atrial fibrillation detection in the presence of real-world label noise
Nov 07, 2022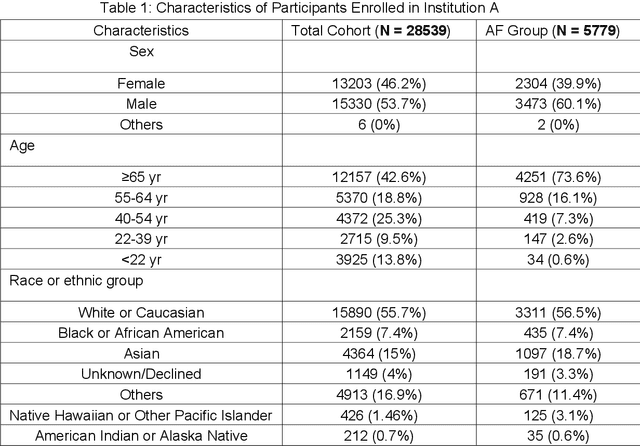
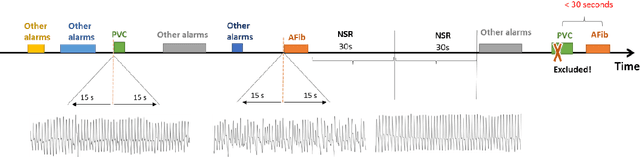

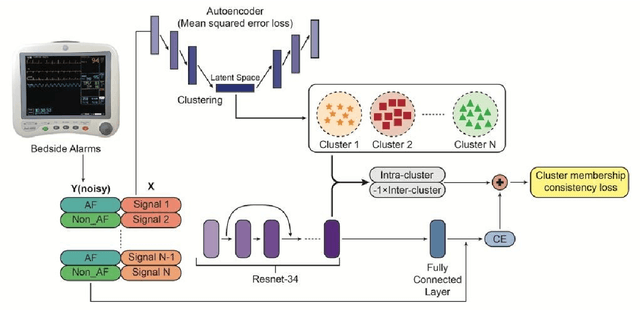
Obtaining large-scale well-annotated is always a daunting challenge, especially in the medical research domain because of the shortage of domain expert. Instead of human annotation, in this work, we use the alarm information generated from bed-side monitor to get the pseudo label for the co-current photoplethysmography (PPG) signal. Based on this strategy, we end up with over 8 million 30-second PPG segment. To solve the label noise caused by false alarms, we propose the cluster consistency, which use an unsupervised auto-encoder (hence not subject to label noise) approach to cluster training samples into a finite number of clusters. Then the learned cluster membership is used in the subsequent supervised learning phase to force the distance in the latent space of samples in the same cluster to be small while that of samples in different clusters to be big. In the experiment, we compare with the state-of-the-art algorithms and test on external datasets. The results show the superiority of our method in both classification performance and efficiency.
Resource allocation using metaheuristic search
May 06, 2016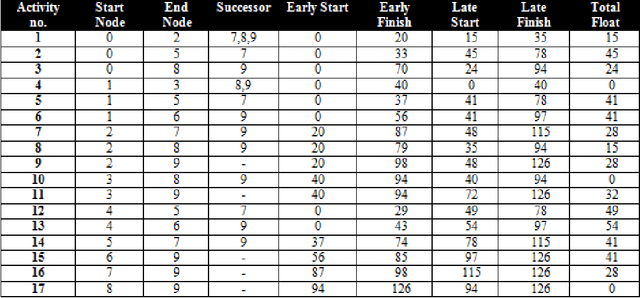
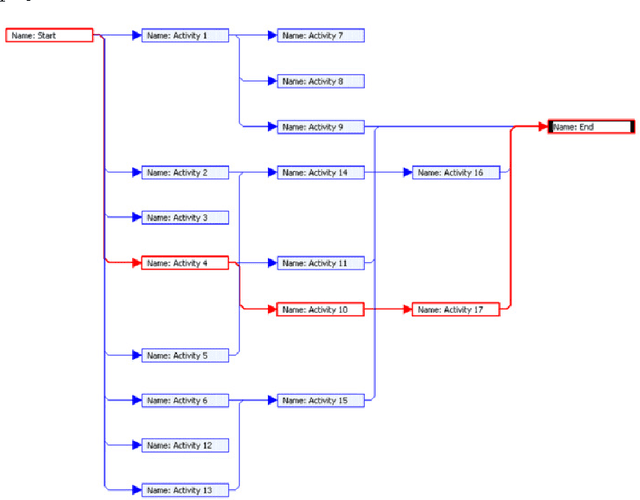
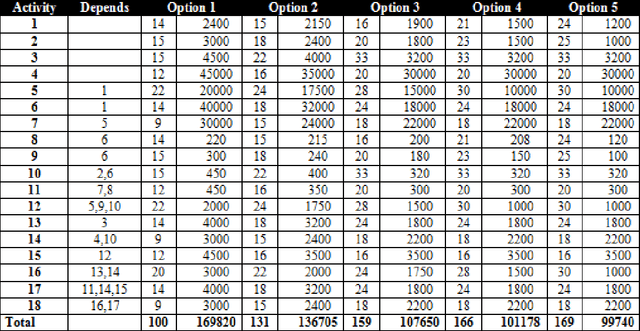
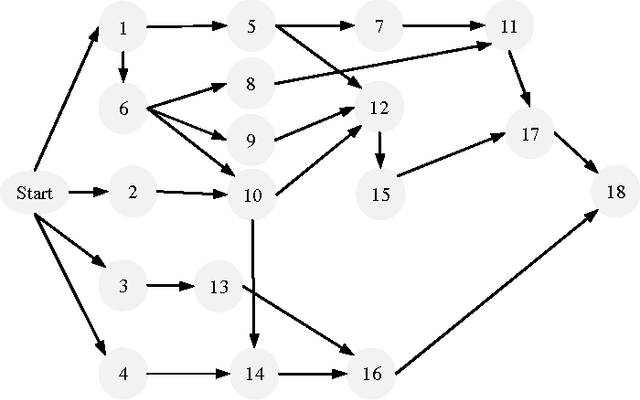
This research is focused on solving problems in the area of software project management using metaheuristic search algorithms and as such is research in the field of search based software engineering. The main aim of this research is to evaluate the performance of different metaheuristic search techniques in resource allocation and scheduling problems that would be typical of software development projects. This paper reports a set of experiments which evaluate the performance of three algorithms, namely simulated annealing, tabu search and genetic algorithms. The experimental results indicate that all of the metaheuristics search techniques can be used to solve problems in resource allocation and scheduling within a software project. Finally, a comparative analysis suggests that overall the genetic algorithm had performed better than simulated annealing and tabu search.