 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Rebalancing: Benchmarking Binary Classifiers Under Class Imbalance Without Rebalancing Techniques
Sep 09, 2025Class imbalance poses a significant challenge to supervised classification, particularly in critical domains like medical diagnostics and anomaly detection where minority class instances are rare. While numerous studies have explored rebalancing techniques to address this issue, less attention has been given to evaluating the performance of binary classifiers under imbalance when no such techniques are applied. Therefore, the goal of this study is to assess the performance of binary classifiers "as-is", without performing any explicit rebalancing. Specifically, we systematically evaluate the robustness of a diverse set of binary classifiers across both real-world and synthetic datasets, under progressively reduced minority class sizes, using one-shot and few-shot scenarios as baselines. Our approach also explores varying data complexities through synthetic decision boundary generation to simulate real-world conditions. In addition to standard classifiers, we include experiments using undersampling, oversampling strategies, and one-class classification (OCC) methods to examine their behavior under severe imbalance. The results confirm that classification becomes more difficult as data complexity increases and the minority class size decreases. While traditional classifiers deteriorate under extreme imbalance, advanced models like TabPFN and boosting-based ensembles retain relatively higher performance and better generalization compared to traditional classifiers. Visual interpretability and evaluation metrics further validate these findings. Our work offers valuable guidance on model selection for imbalanced learning, providing insights into classifier robustness without dependence on explicit rebalancing techniques.
AI/ML Algorithms and Applications in VLSI Design and Technology
Feb 21, 2022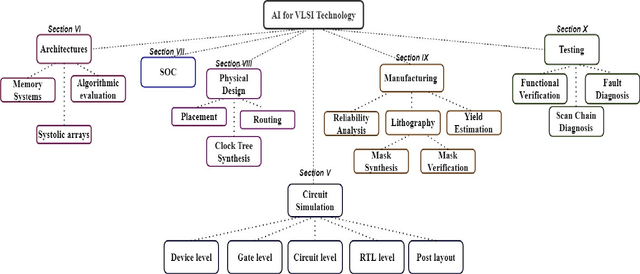
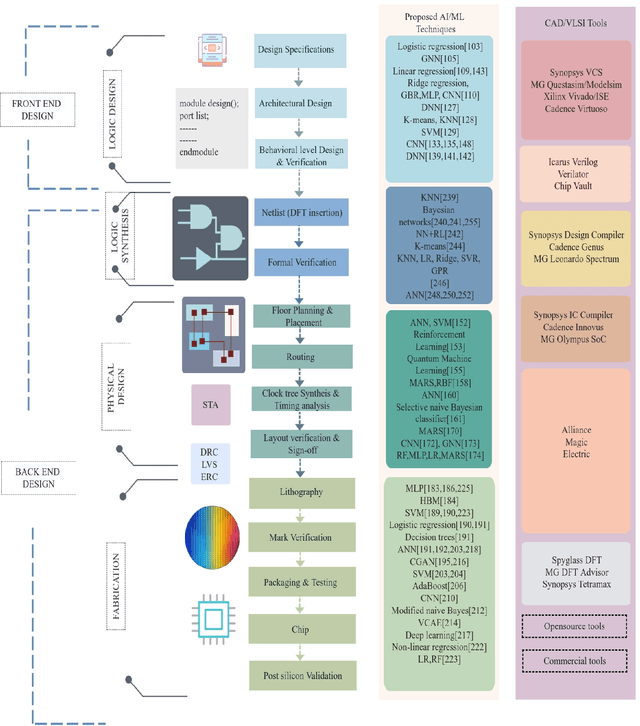
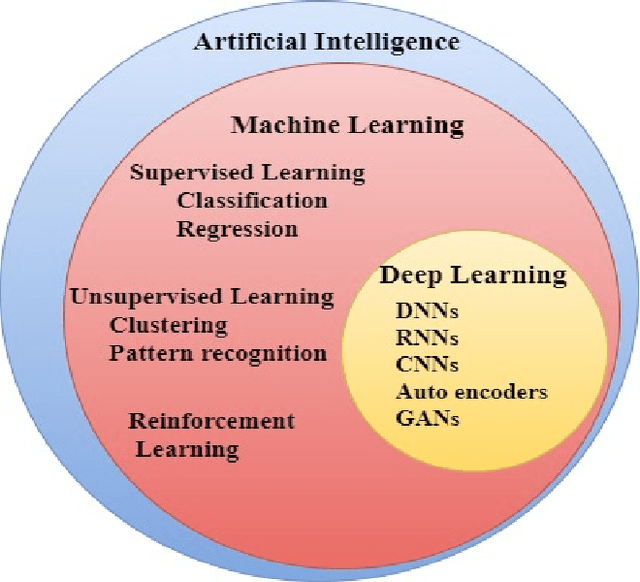
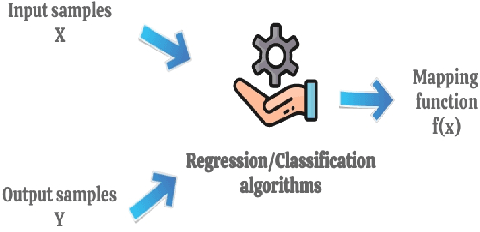
An evident challenge ahead for the integrated circuit (IC) industry in the nanometer regime is the investigation and development of methods that can reduce the design complexity ensuing from growing process variations and curtail the turnaround time of chip manufacturing. Conventional methodologies employed for such tasks are largely manual; thus, time-consuming and resource-intensive. In contrast, the unique learning strategies of artificial intelligence (AI) provide numerous exciting automated approaches for handling complex and data-intensive tasks in very-large-scale integration (VLSI) design and testing. Employing AI and machine learning (ML) algorithms in VLSI design and manufacturing reduces the time and effort for understanding and processing the data within and across different abstraction levels via automated learning algorithms. It, in turn, improves the IC yield and reduces the manufacturing turnaround time. This paper thoroughly reviews the AI/ML automated approaches introduced in the past towards VLSI design and manufacturing. Moreover, we discuss the scope of AI/ML applications in the future at various abstraction levels to revolutionize the field of VLSI design, aiming for high-speed, highly intelligent, and efficient implementations.
OCCER- One-Class Classification by Ensembles of Regression models
Jan 15, 2020
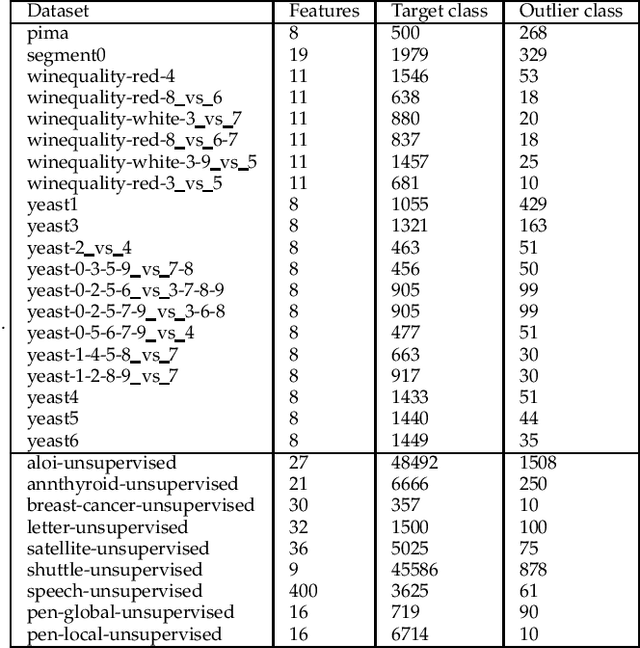
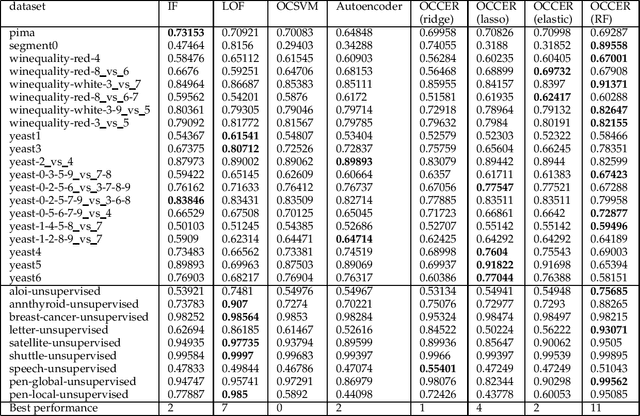
One-class classification (OCC) deals with the classification problem in which the training data has data points belonging to target class only. In this paper, we present a one-class classification algorithm; One-Class Classification by Ensembles of Regression models (OCCER) that uses regression methods to address OCC problems. The OCCEM algorithm coverts a OCC problem into many regression problems in the original feature space such that each feature of the original feature space is used as the target variable in one of the regression problems. Other features are used as the variables on which the dependent variable is depend upon. The errors of regression of a data point by all the regression models are used to compute the outlier score of the data point. An extensive comparison of the OCCER to the state-of-the-art OCC algorithms on several datasets was carried out to show the effectiveness of the proposed approach. We also show that OCCER algorithm can work well with the latent feature space created by autoencoders for image datasets. The implementation of OCCER is available at https://github.com/srikanthBezawada/OCCER.
A Novel Initial Clusters Generation Method for K-means-based Clustering Algorithms for Mixed Datasets
Apr 14, 2019
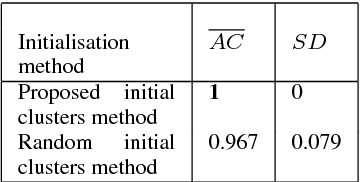

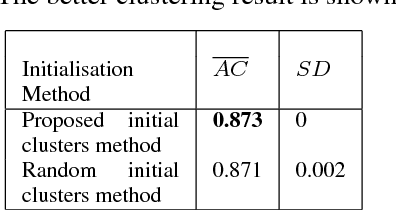
Mixed datasets consist of both numeric and categorical attributes. Various K-means-based clustering algorithms have been developed to cluster these datasets. Generally, these algorithms use random partition as a starting point, which tend to produce different clustering results in different runs. This inconsistency of clustering results may lead to unreliable inferences from the data. A few initialization algorithms have been developed to compute initial partition for mixed datasets; however, they are either computationally expensive or they do not produce consistent clustering results in different runs. In this paper, we propose, initKmix, a novel approach to find initial partition for K-means-based clustering algorithms for mixed datasets. The initKmix is based on the experimental observations that (i) some data points in a dataset remain in the same clusters created by k-means-based clustering algorithm irrespective of the choice of initial clusters, and (ii) individual attribute information can be used to create initial clusters. In initKmix method, a k-means-based clustering algorithm is run many times, in each run one of the attribute is used to produce initial partition. The clustering results of various runs are combined to produce initial partition. This initial partition is then be used as a seed to a k-means-based clustering algorithm to cluster mixed data. The initial partitions produced by initKmix are always fixed, do not change over different runs or by changing the order of the data objects. Experiments with various categorical and mixed datasets showed that initKmix produced accurate and consistent results, and outperformed random initialization and other state-of-the-art initialization methods. Experiments also showed that K-means-based clustering for mixed datasets with initKmix outperformed many state-of-the-art clustering algorithms.
A Survey of Mixed Data Clustering Algorithms
Nov 25, 2018


Most of the datasets normally contain either numeric or categorical features. Mixed data comprises of both numeric and categorical features, and they frequently occur in various domains, such as health, finance, marketing, etc. Clustering is often sought on mixed data to find structures and to group similar objects. However, clustering mixed data is challenging because it is difficult to directly apply mathematical operations, such as summation, average etc. on the feature values of these datasets. In this paper, we review various types of mixed data clustering techniques in detail. We present a taxonomy to identify ten types of different mixed data clustering techniques. We also compare the performance of several mixed data clustering methods on publicly available datasets. The paper further identifies challenges in developing different mixed data clustering algorithms and provides guidelines for future directions in this area.
Bootstrapping and Multiple Imputation Ensemble Approaches for Missing Data
Feb 06, 2018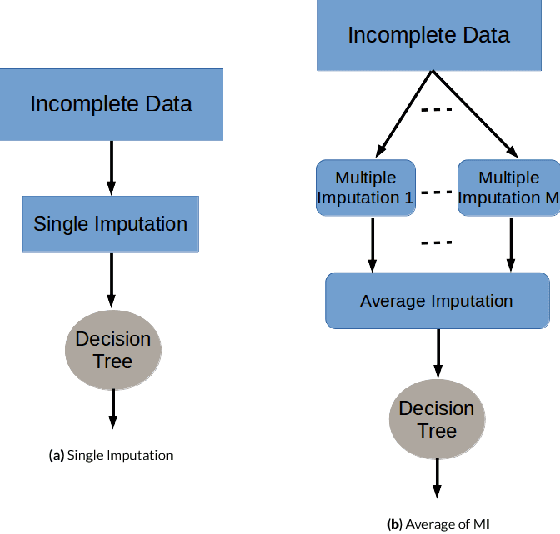



Presence of missing values in a dataset can adversely affect the performance of a classifier. Single and Multiple Imputation are normally performed to fill in the missing values. In this paper, we present several variants of combining single and multiple imputation with bootstrapping to create ensembles that can model uncertainty and diversity in the data, and that are robust to high missingness in the data. We present three ensemble strategies: bootstrapping on incomplete data followed by (i) single imputation and (ii) multiple imputation, and (iii) multiple imputation ensemble without bootstrapping. We perform an extensive evaluation of the performance of the these ensemble strategies on 8 datasets by varying the missingness ratio. Our results show that bootstrapping followed by multiple imputation using expectation maximization is the most robust method even at high missingness ratio (up to 30%). For small missingness ratio (up to 10%) most of the ensemble methods perform quivalently but better than single imputation. Kappa-error plots suggest that accurate classifiers with reasonable diversity is the reason for this behaviour. A consistent observation in all the datasets suggests that for small missingness (up to 10%), bootstrapping on incomplete data without any imputation produces equivalent results to other ensemble methods.
Relationship between Variants of One-Class Nearest Neighbours and Creating their Accurate Ensembles
Dec 28, 2017
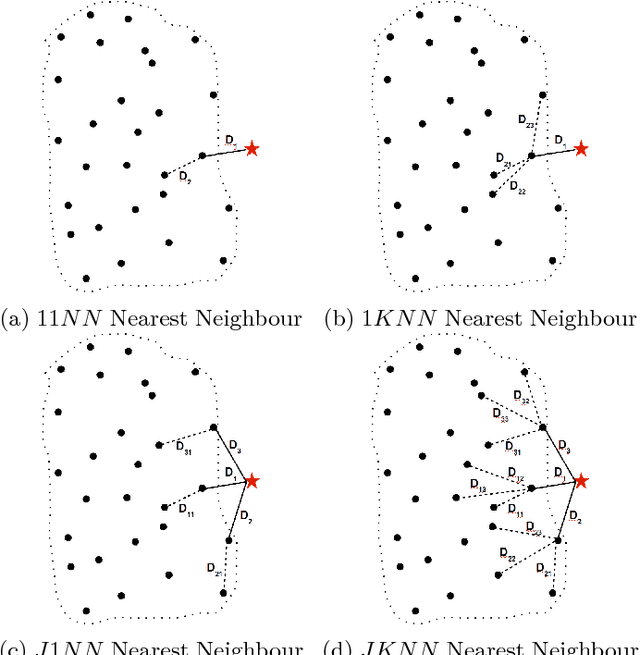
In one-class classification problems, only the data for the target class is available, whereas the data for the non-target class may be completely absent. In this paper, we study one-class nearest neighbour (OCNN) classifiers and their different variants. We present a theoretical analysis to show the relationships among different variants of OCNN that may use different neighbours or thresholds to identify unseen examples of the non-target class. We also present a method based on inter-quartile range for optimising parameters used in OCNN in the absence of non-target data during training. Then, we propose two ensemble approaches based on random subspace and random projection methods to create accurate OCNN ensembles. We tested the proposed methods on 15 benchmark and real world domain-specific datasets and show that random-projection ensembles of OCNN perform best.