 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping and Multiple Imputation Ensemble Approaches for Missing Data
Paper and Code
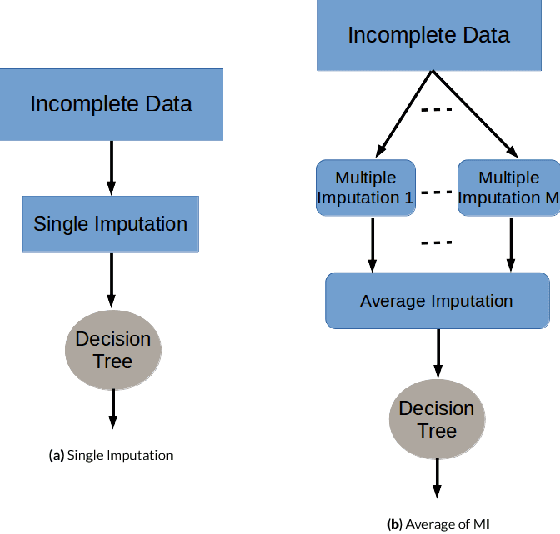



Presence of missing values in a dataset can adversely affect the performance of a classifier. Single and Multiple Imputation are normally performed to fill in the missing values. In this paper, we present several variants of combining single and multiple imputation with bootstrapping to create ensembles that can model uncertainty and diversity in the data, and that are robust to high missingness in the data. We present three ensemble strategies: bootstrapping on incomplete data followed by (i) single imputation and (ii) multiple imputation, and (iii) multiple imputation ensemble without bootstrapping. We perform an extensive evaluation of the performance of the these ensemble strategies on 8 datasets by varying the missingness ratio. Our results show that bootstrapping followed by multiple imputation using expectation maximization is the most robust method even at high missingness ratio (up to 30%). For small missingness ratio (up to 10%) most of the ensemble methods perform quivalently but better than single imputation. Kappa-error plots suggest that accurate classifiers with reasonable diversity is the reason for this behaviour. A consistent observation in all the datasets suggests that for small missingness (up to 10%), bootstrapping on incomplete data without any imputation produces equivalent results to other ensemble methods.