 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Mixed Data Clustering Algorithms
Paper and Code
Nov 25, 2018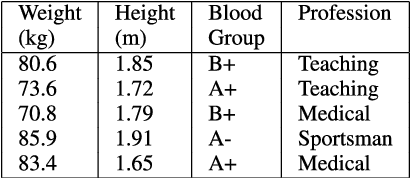
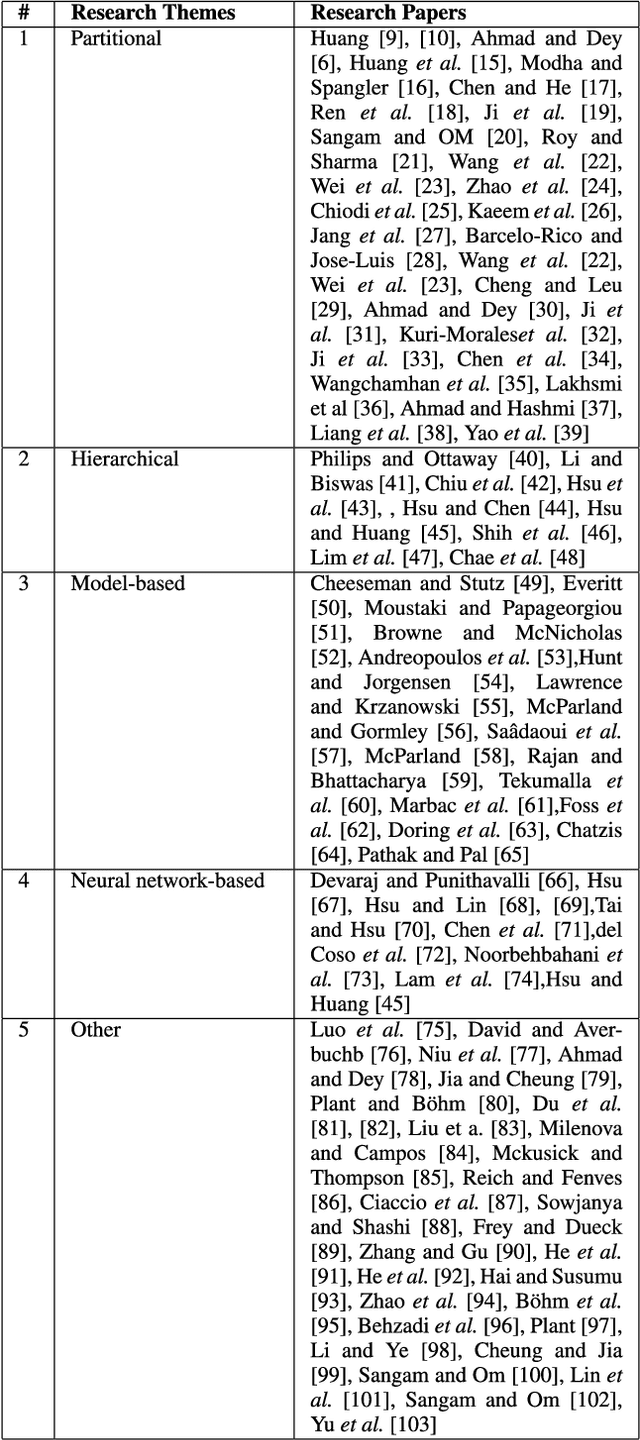


Most of the datasets normally contain either numeric or categorical features. Mixed data comprises of both numeric and categorical features, and they frequently occur in various domains, such as health, finance, marketing, etc. Clustering is often sought on mixed data to find structures and to group similar objects. However, clustering mixed data is challenging because it is difficult to directly apply mathematical operations, such as summation, average etc. on the feature values of these datasets. In this paper, we review various types of mixed data clustering techniques in detail. We present a taxonomy to identify ten types of different mixed data clustering techniques. We also compare the performance of several mixed data clustering methods on publicly available datasets. The paper further identifies challenges in developing different mixed data clustering algorithms and provides guidelines for future directions in this area.