 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelationship between Variants of One-Class Nearest Neighbours and Creating their Accurate Ensembles
Paper and Code
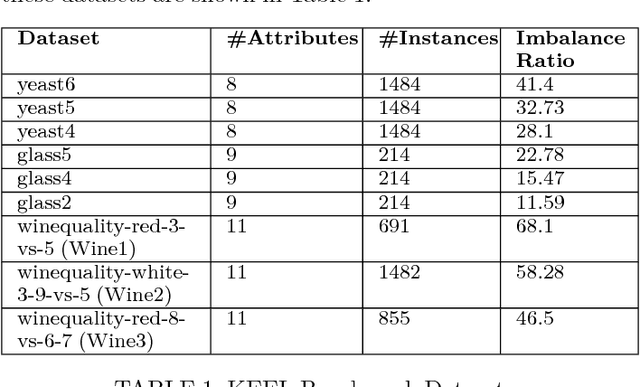
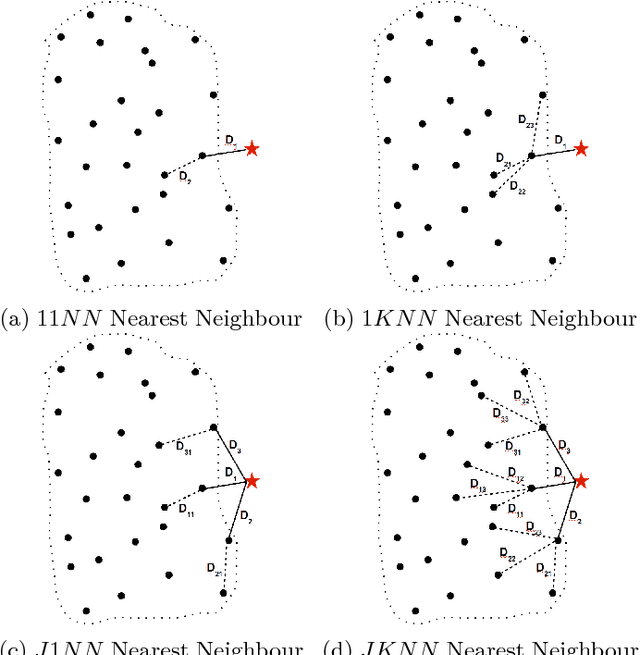
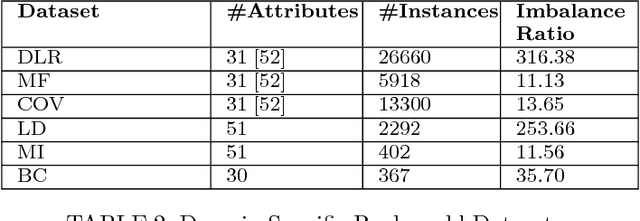
In one-class classification problems, only the data for the target class is available, whereas the data for the non-target class may be completely absent. In this paper, we study one-class nearest neighbour (OCNN) classifiers and their different variants. We present a theoretical analysis to show the relationships among different variants of OCNN that may use different neighbours or thresholds to identify unseen examples of the non-target class. We also present a method based on inter-quartile range for optimising parameters used in OCNN in the absence of non-target data during training. Then, we propose two ensemble approaches based on random subspace and random projection methods to create accurate OCNN ensembles. We tested the proposed methods on 15 benchmark and real world domain-specific datasets and show that random-projection ensembles of OCNN perform best.