 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYes, IoU loss is submodular - as a function of the mispredictions
Sep 06, 2018This note is a response to [7] in which it is claimed that [13, Proposition 11] is false. We demonstrate here that this assertion in [7] is false, and is based on a misreading of the notion of set membership in [13, Proposition 11]. We maintain that [13, Proposition 11] is true. ([7] = arXiv:1809.00593, [13] = arXiv:1512.07797)
Function Norms and Regularization in Deep Networks
Jun 28, 2018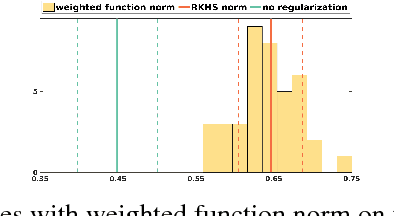
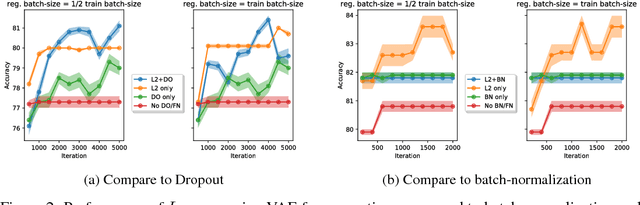
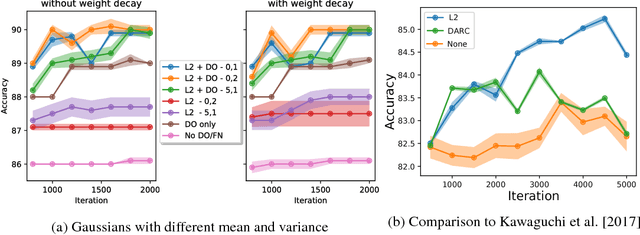
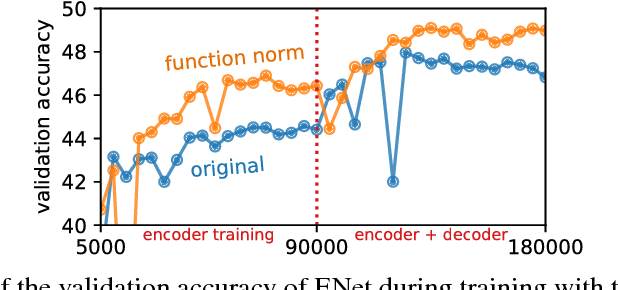
Deep neural networks (DNNs) have become increasingly important due to their excellent empirical performance on a wide range of problems. However, regularization is generally achieved by indirect means, largely due to the complex set of functions defined by a network and the difficulty in measuring function complexity. There exists no method in the literature for additive regularization based on a norm of the function, as is classically considered in statistical learning theory. In this work, we propose sampling-based approximations to weighted function norms as regularizers for deep neural networks. We provide, to the best of our knowledge, the first proof in the literature of the NP-hardness of computing function norms of DNNs, motivating the necessity of an approximate approach. We then derive a generalization bound for functions trained with weighted norms and prove that a natural stochastic optimization strategy minimizes the bound. Finally, we empirically validate the improved performance of the proposed regularization strategies for both convex function sets as well as DNNs on real-world classification and image segmentation tasks demonstrating improved performance over weight decay, dropout, and batch normalization. Source code will be released at the time of publication.
The Lovász-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks
Apr 09, 2018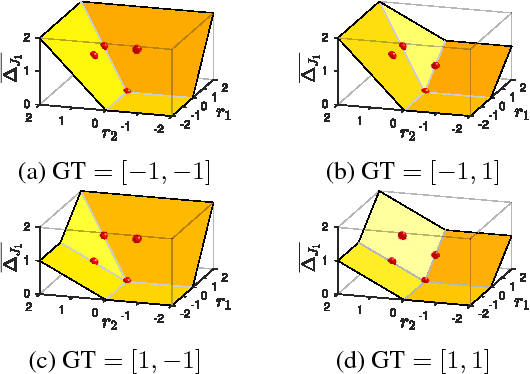

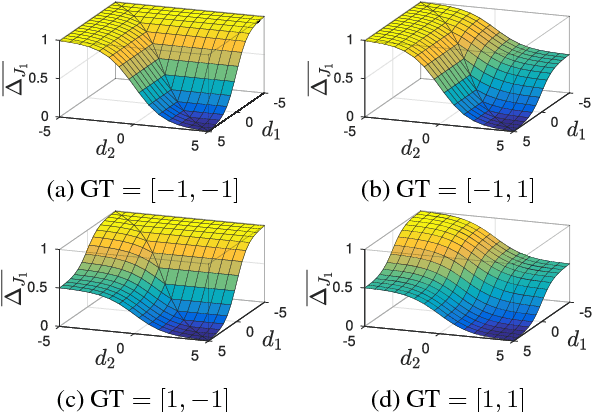
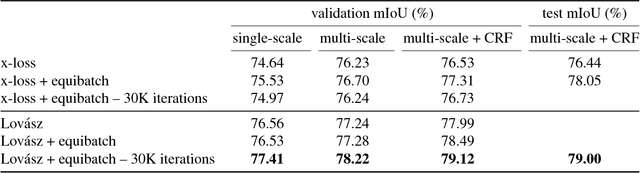
The Jaccard index, also referred to as the intersection-over-union score, is commonly employed in the evaluation of image segmentation results given its perceptual qualities, scale invariance - which lends appropriate relevance to small objects, and appropriate counting of false negatives, in comparison to per-pixel losses. We present a method for direct optimization of the mean intersection-over-union loss in neural networks, in the context of semantic image segmentation, based on the convex Lov\'asz extension of submodular losses. The loss is shown to perform better with respect to the Jaccard index measure than the traditionally used cross-entropy loss. We show quantitative and qualitative differences between optimizing the Jaccard index per image versus optimizing the Jaccard index taken over an entire dataset. We evaluate the impact of our method in a semantic segmentation pipeline and show substantially improved intersection-over-union segmentation scores on the Pascal VOC and Cityscapes datasets using state-of-the-art deep learning segmentation architectures.
Encoder Based Lifelong Learning
Apr 06, 2017

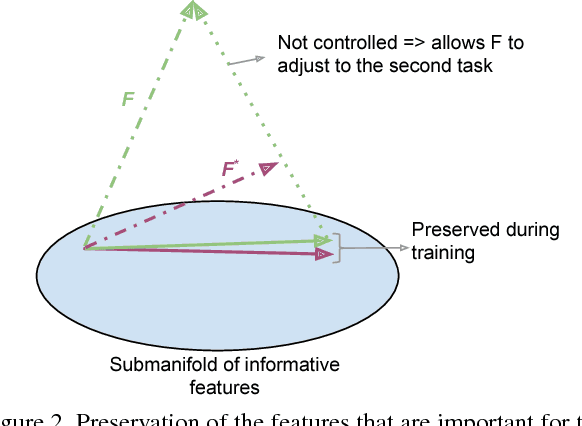

This paper introduces a new lifelong learning solution where a single model is trained for a sequence of tasks. The main challenge that vision systems face in this context is catastrophic forgetting: as they tend to adapt to the most recently seen task, they lose performance on the tasks that were learned previously. Our method aims at preserving the knowledge of the previous tasks while learning a new one by using autoencoders. For each task, an under-complete autoencoder is learned, capturing the features that are crucial for its achievement. When a new task is presented to the system, we prevent the reconstructions of the features with these autoencoders from changing, which has the effect of preserving the information on which the previous tasks are mainly relying. At the same time, the features are given space to adjust to the most recent environment as only their projection into a low dimension submanifold is controlled. The proposed system is evaluated on image classification tasks and shows a reduction of forgetting over the state-of-the-art
Intraoperative margin assessment of human breast tissue in optical coherence tomography images using deep neural networks
Mar 31, 2017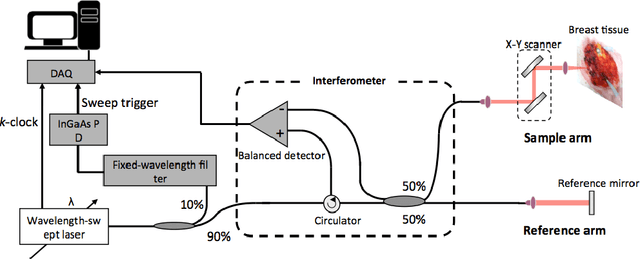


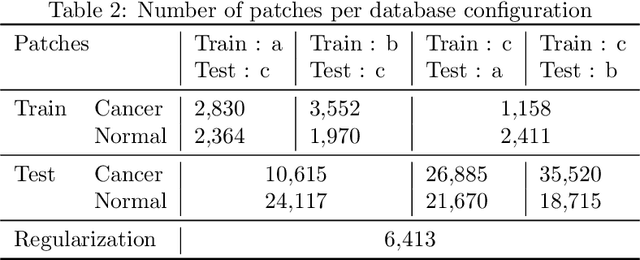
Objective: In this work, we perform margin assessment of human breast tissue from optical coherence tomography (OCT) images using deep neural networks (DNNs). This work simulates an intraoperative setting for breast cancer lumpectomy. Methods: To train the DNNs, we use both the state-of-the-art methods (Weight Decay and DropOut) and a newly introduced regularization method based on function norms. Commonly used methods can fail when only a small database is available. The use of a function norm introduces a direct control over the complexity of the function with the aim of diminishing the risk of overfitting. Results: As neither the code nor the data of previous results are publicly available, the obtained results are compared with reported results in the literature for a conservative comparison. Moreover, our method is applied to locally collected data on several data configurations. The reported results are the average over the different trials. Conclusion: The experimental results show that the use of DNNs yields significantly better results than other techniques when evaluated in terms of sensitivity, specificity, F1 score, G-mean and Matthews correlation coefficient. Function norm regularization yielded higher and more robust results than competing methods. Significance: We have demonstrated a system that shows high promise for (partially) automated margin assessment of human breast tissue, Equal error rate (EER) is reduced from approximately 12\% (the lowest reported in the literature) to 5\%\,--\,a 58\% reduction. The method is computationally feasible for intraoperative application (less than 2 seconds per image).
Stochastic Function Norm Regularization of Deep Networks
Dec 07, 2016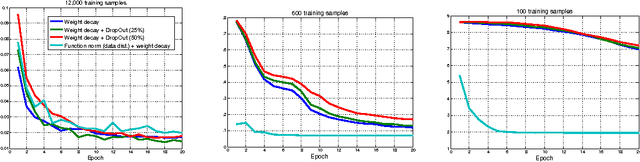


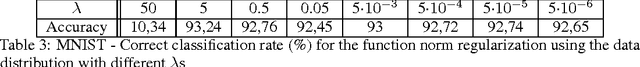
Deep neural networks have had an enormous impact on image analysis. State-of-the-art training methods, based on weight decay and DropOut, result in impressive performance when a very large training set is available. However, they tend to have large problems overfitting to small data sets. Indeed, the available regularization methods deal with the complexity of the network function only indirectly. In this paper, we study the feasibility of directly using the $L_2$ function norm for regularization. Two methods to integrate this new regularization in the stochastic backpropagation are proposed. Moreover, the convergence of these new algorithms is studied. We finally show that they outperform the state-of-the-art methods in the low sample regime on benchmark datasets (MNIST and CIFAR10). The obtained results demonstrate very clear improvement, especially in the context of small sample regimes with data laying in a low dimensional manifold. Source code of the method can be found at \url{https://github.com/AmalRT/DNN_Reg}.