 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoder Based Lifelong Learning
Paper and Code
Apr 06, 2017

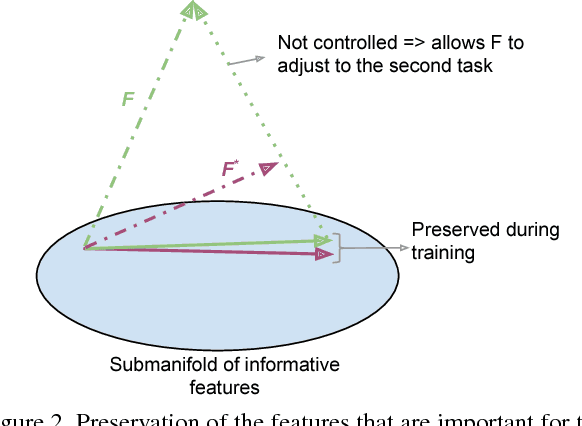

This paper introduces a new lifelong learning solution where a single model is trained for a sequence of tasks. The main challenge that vision systems face in this context is catastrophic forgetting: as they tend to adapt to the most recently seen task, they lose performance on the tasks that were learned previously. Our method aims at preserving the knowledge of the previous tasks while learning a new one by using autoencoders. For each task, an under-complete autoencoder is learned, capturing the features that are crucial for its achievement. When a new task is presented to the system, we prevent the reconstructions of the features with these autoencoders from changing, which has the effect of preserving the information on which the previous tasks are mainly relying. At the same time, the features are given space to adjust to the most recent environment as only their projection into a low dimension submanifold is controlled. The proposed system is evaluated on image classification tasks and shows a reduction of forgetting over the state-of-the-art