 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction Norms and Regularization in Deep Networks
Paper and Code
Jun 28, 2018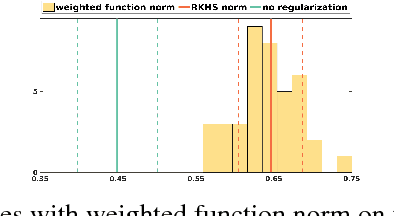
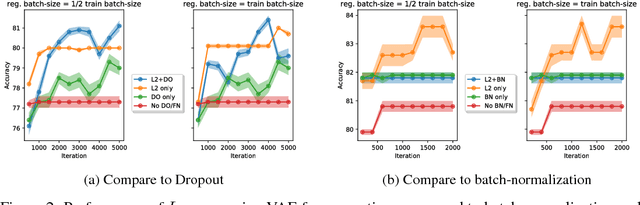
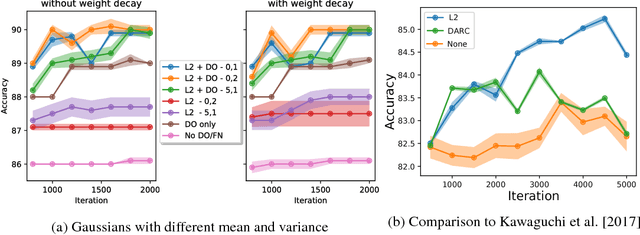
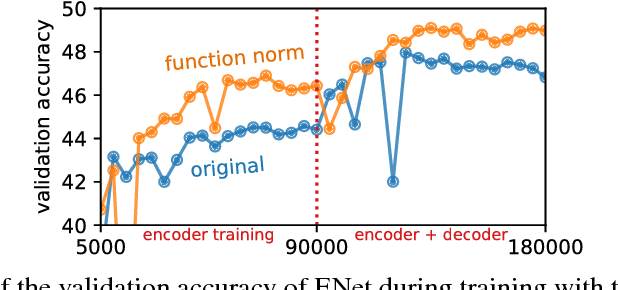
Deep neural networks (DNNs) have become increasingly important due to their excellent empirical performance on a wide range of problems. However, regularization is generally achieved by indirect means, largely due to the complex set of functions defined by a network and the difficulty in measuring function complexity. There exists no method in the literature for additive regularization based on a norm of the function, as is classically considered in statistical learning theory. In this work, we propose sampling-based approximations to weighted function norms as regularizers for deep neural networks. We provide, to the best of our knowledge, the first proof in the literature of the NP-hardness of computing function norms of DNNs, motivating the necessity of an approximate approach. We then derive a generalization bound for functions trained with weighted norms and prove that a natural stochastic optimization strategy minimizes the bound. Finally, we empirically validate the improved performance of the proposed regularization strategies for both convex function sets as well as DNNs on real-world classification and image segmentation tasks demonstrating improved performance over weight decay, dropout, and batch normalization. Source code will be released at the time of publication.