 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Gradient Compression for Distributed and Federated Learning
Oct 07, 2020
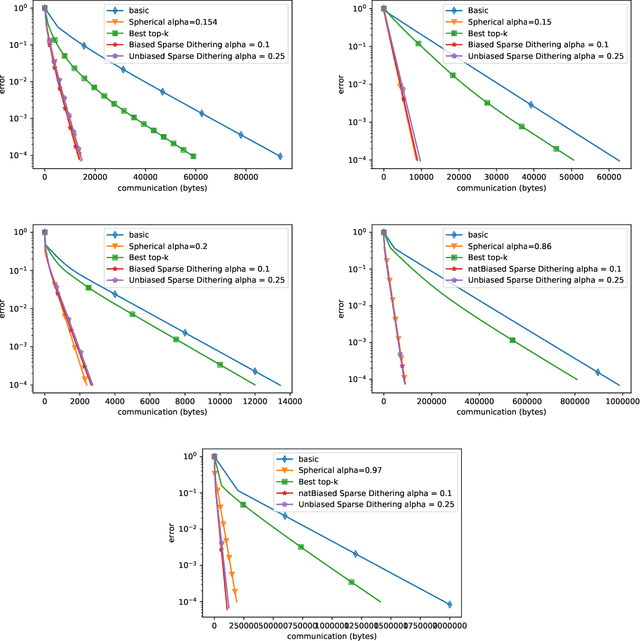
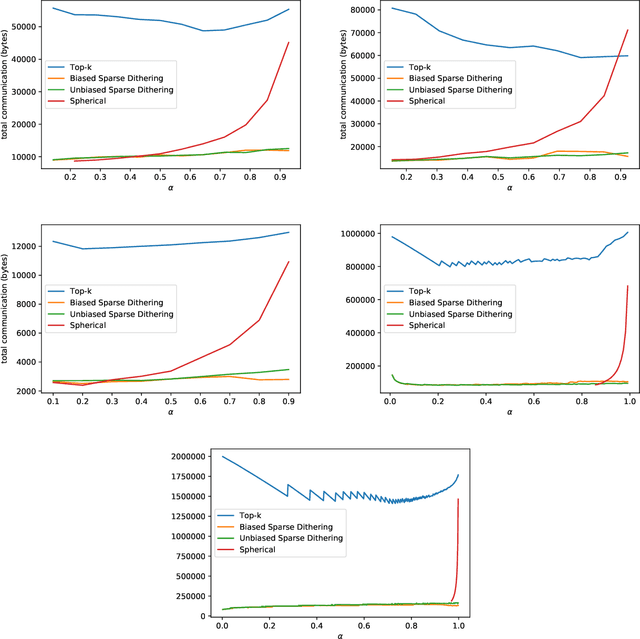

Communicating information, like gradient vectors, between computing nodes in distributed and federated learning is typically an unavoidable burden, resulting in scalability issues. Indeed, communication might be slow and costly. Recent advances in communication-efficient training algorithms have reduced this bottleneck by using compression techniques, in the form of sparsification, quantization, or low-rank approximation. Since compression is a lossy, or inexact, process, the iteration complexity is typically worsened; but the total communication complexity can improve significantly, possibly leading to large computation time savings. In this paper, we investigate the fundamental trade-off between the number of bits needed to encode compressed vectors and the compression error. We perform both worst-case and average-case analysis, providing tight lower bounds. In the worst-case analysis, we introduce an efficient compression operator, Sparse Dithering, which is very close to the lower bound. In the average-case analysis, we design a simple compression operator, Spherical Compression, which naturally achieves the lower bound. Thus, our new compression schemes significantly outperform the state of the art. We conduct numerical experiments to illustrate this improvement.
Adaptive Learning of the Optimal Mini-Batch Size of SGD
May 03, 2020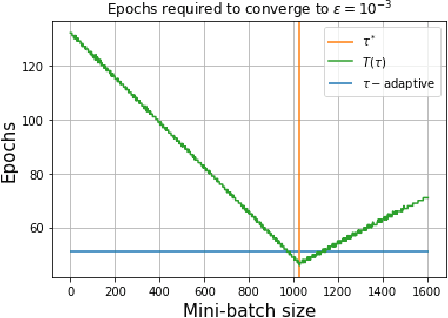
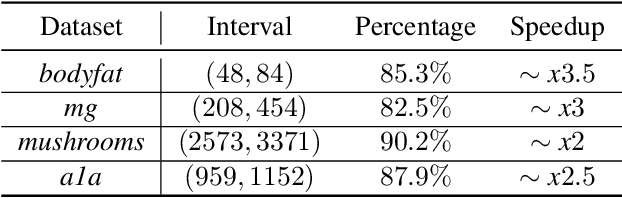
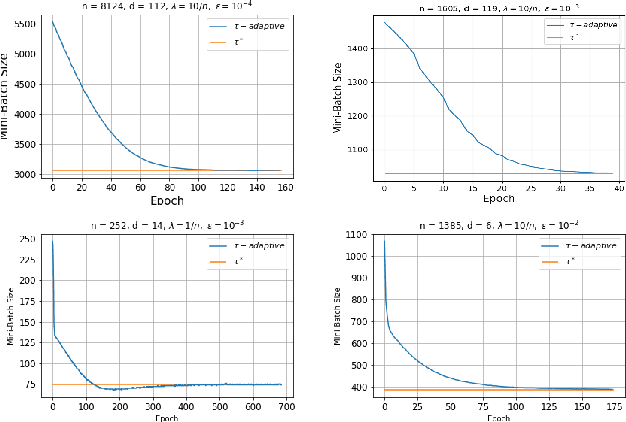
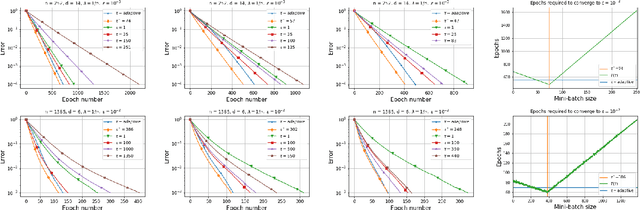
Recent advances in the theoretical understandingof SGD (Qian et al., 2019) led to a formula for the optimal mini-batch size minimizing the number of effective data passes, i.e., the number of iterations times the mini-batch size. However, this formula is of no practical value as it depends on the knowledge of the variance of the stochastic gradients evaluated at the optimum. In this paper we design a practical SGD method capable of learning the optimal mini-batch size adaptively throughout its iterations. Our method does this provably, and in our experiments with synthetic and real data robustly exhibits nearly optimal behaviour; that is, it works as if the optimal mini-batch size was known a-priori. Further, we generalize our method to several new mini-batch strategies not considered in the literature before, including a sampling suitable for distributed implementations.