 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Learning of the Optimal Mini-Batch Size of SGD
Paper and Code
May 03, 2020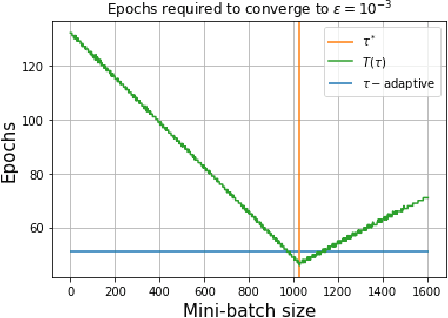
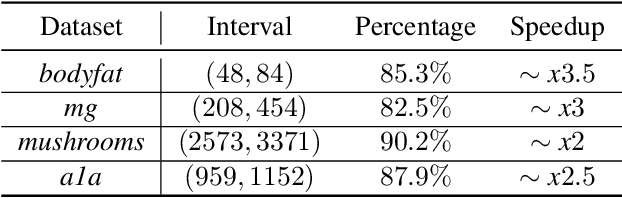
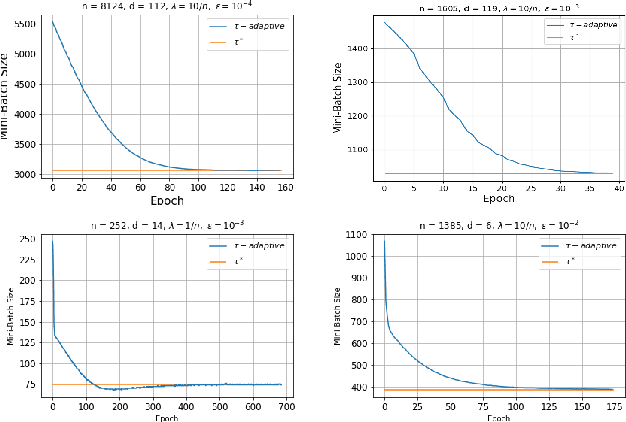
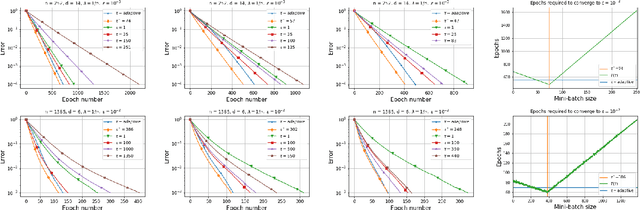
Recent advances in the theoretical understandingof SGD (Qian et al., 2019) led to a formula for the optimal mini-batch size minimizing the number of effective data passes, i.e., the number of iterations times the mini-batch size. However, this formula is of no practical value as it depends on the knowledge of the variance of the stochastic gradients evaluated at the optimum. In this paper we design a practical SGD method capable of learning the optimal mini-batch size adaptively throughout its iterations. Our method does this provably, and in our experiments with synthetic and real data robustly exhibits nearly optimal behaviour; that is, it works as if the optimal mini-batch size was known a-priori. Further, we generalize our method to several new mini-batch strategies not considered in the literature before, including a sampling suitable for distributed implementations.