 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Approaches to Reconfigurable Assembly Systems
Aug 27, 2020
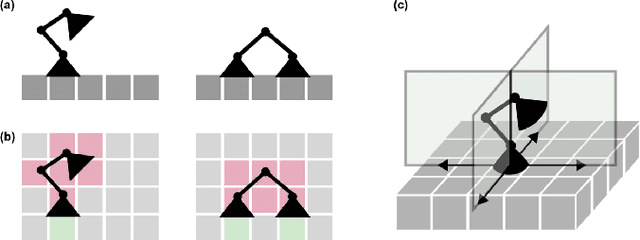
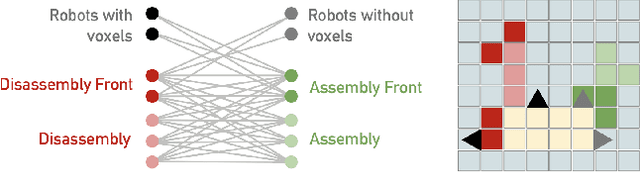
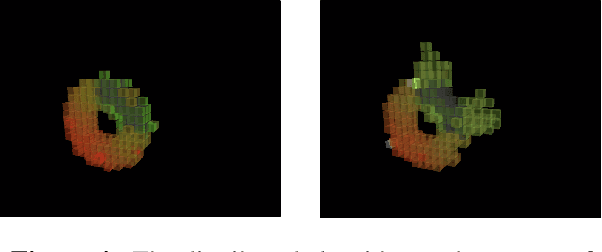
Assembly of large scale structural systems in space is understood as critical to serving applications that cannot be deployed from a single launch. Recent literature proposes the use of discrete modular structures for in-space assembly and relatively small scale robotics that are able to modify and traverse the structure. This paper addresses the algorithmic problems in scaling reconfigurable space structures built through robotic construction, where reconfiguration is defined as the problem of transforming an initial structure into a different goal configuration. We analyze different algorithmic paradigms and present corresponding abstractions and graph formulations, examining specialized algorithms that consider discretized space and time steps. We then discuss fundamental design trades for different computational architectures, such as centralized versus distributed, and present two representative algorithms as concrete examples for comparison. We analyze how those algorithms achieve different objective functions and goals, such as minimization of total distance traveled, maximization of fault-tolerance, or minimization of total time spent in assembly. This is meant to offer an impression of algorithmic constraints on scalability of corresponding structural and robotic design. From this study, a set of recommendations is developed on where and when to use each paradigm, as well as implications for physical robotic and structural system design.
Interpretable Neuroevolutionary Models for Learning Non-Differentiable Functions and Programs
Jul 16, 2020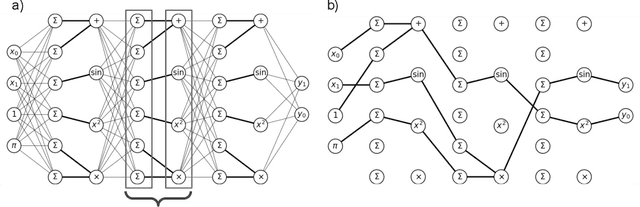
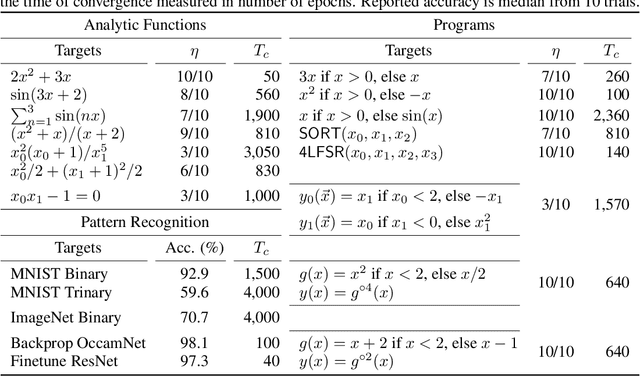
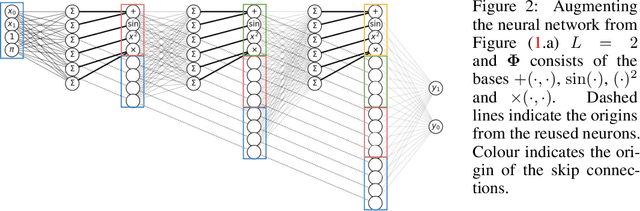
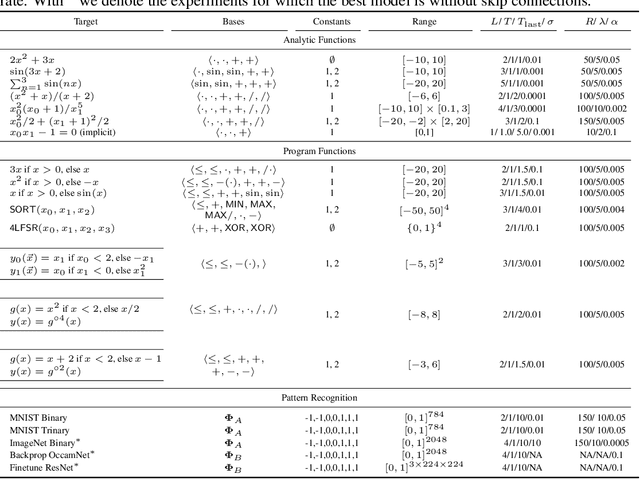
A key factor in the modern success of deep learning is the astonishing expressive power of neural networks. However, this comes at the cost of complex, black-boxed models that are unable to extrapolate beyond the domain of the training dataset, conflicting with goals of expressing physical laws or building human-readable programs. In this paper, we introduce OccamNet, a neural network model that can find interpretable, compact and sparse solutions for fitting data, \`{a} la Occam's razor. Our model defines a probability distribution over a non-differentiable function space, and we introduce an optimization method that samples functions and updates the weights based on cross-entropy matching in an evolutionary strategy: we train by biasing the probability mass towards better fitting solutions. We demonstrate that we can fit a variety of algorithms, ranging from simple analytic functions through recursive programs to even simple image classification. Our method takes minimal memory footprint, does not require AI accelerators for efficient training, fits complicated functions in minutes of training on a single CPU, and demonstrates significant performance gains when scaled on GPU. Our implementation, demonstrations and instructions for reproducing the experiments are available at https://github.com/AllanSCosta/occam-net.