 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetting up experimental Bell test with reinforcement learning
May 04, 2020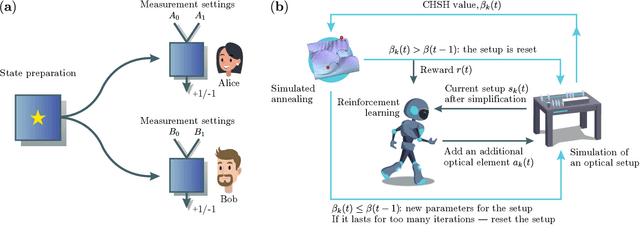
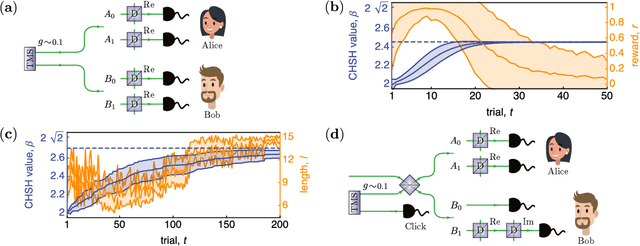
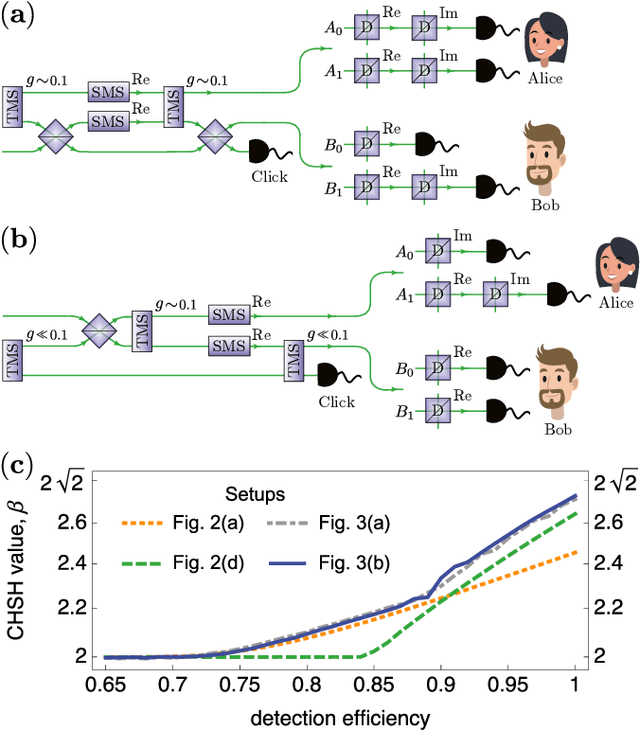
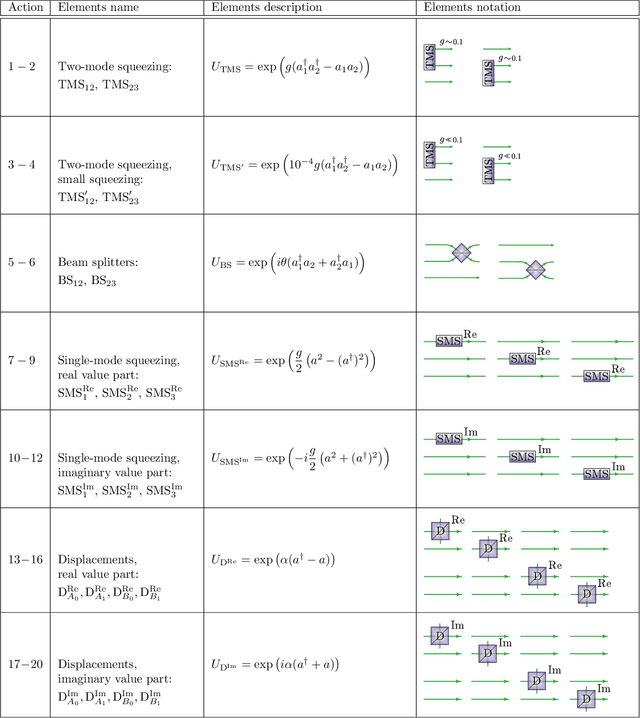
Finding optical setups producing measurement results with a targeted probability distribution is hard as a priori the number of possible experimental implementations grows exponentially with the number of modes and the number of devices. To tackle this complexity, we introduce a method combining reinforcement learning and simulated annealing enabling the automated design of optical experiments producing results with the desired probability distributions. We illustrate the relevance of our method by applying it to a probability distribution favouring high violations of the Bell-CHSH inequality. As a result, we propose new unintuitive experiments leading to higher Bell-CHSH inequality violations than the best currently known setups. Our method might positively impact the usefulness of photonic experiments for device-independent quantum information processing.
Machine learning transfer efficiencies for noisy quantum walks
Feb 18, 2020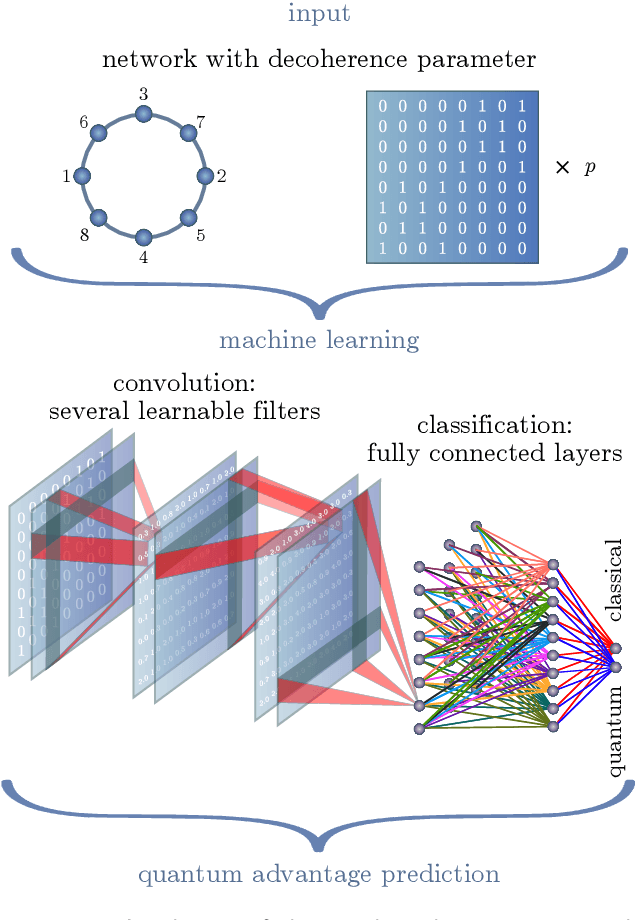
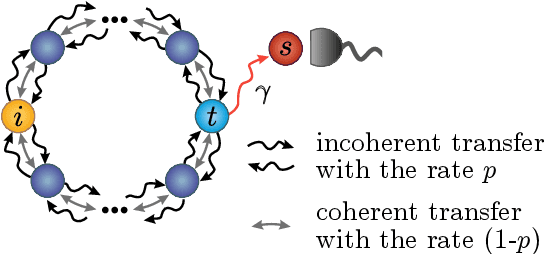
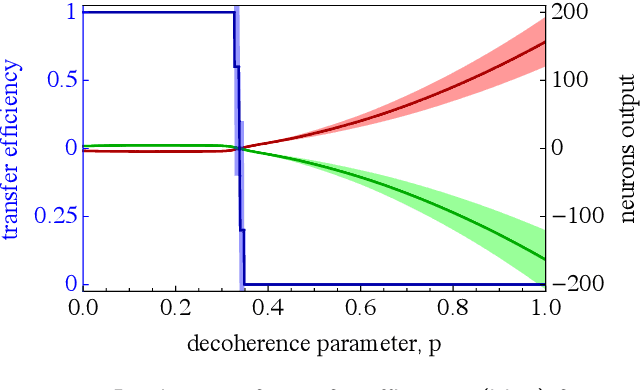
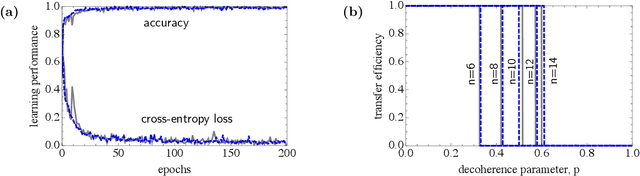
Quantum effects are known to provide an advantage in particle transfer across networks. In order to achieve this advantage, requirements on both a graph type and a quantum system coherence must be found. Here we show that the process of finding these requirements can be automated by learning from simulated examples. The automation is done by using a convolutional neural network of a particular type that learns to understand with which network and under which coherence requirements quantum advantage is possible. Our machine learning approach is applied to study noisy quantum walks on cycle graphs of different sizes. We found that it is possible to predict the existence of quantum advantage for the entire decoherence parameter range, even for graphs outside of the training set. Our results are of importance for demonstration of advantage in quantum experiments and pave the way towards automating scientific research and discoveries.
* 6 pages, 4 figures
Machine learning for long-distance quantum communication
Apr 24, 2019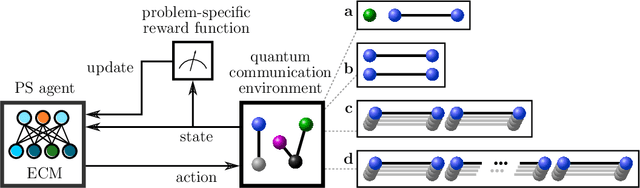
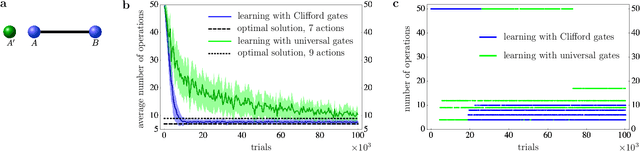
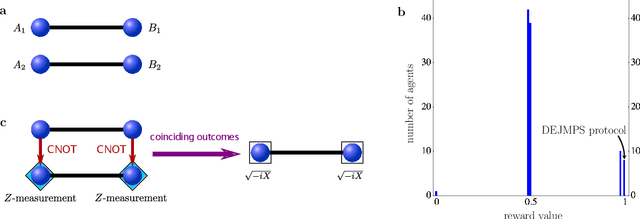
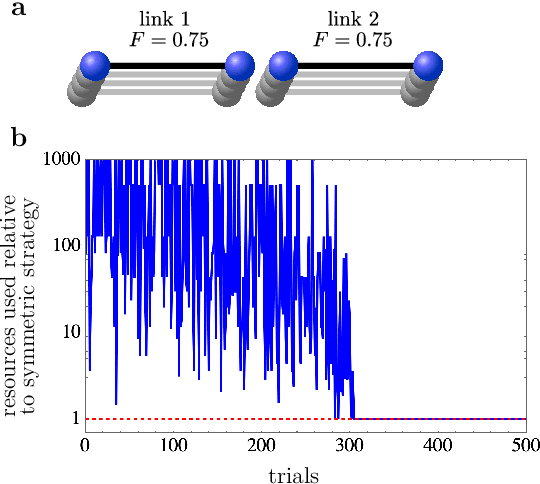
Machine learning can help us in solving problems in the context big data analysis and classification, as well as in playing complex games such as Go. But can it also be used to find novel protocols and algorithms for applications such as large-scale quantum communication? Here we show that machine learning can be used to identify central quantum protocols, including teleportation, entanglement purification and the quantum repeater. These schemes are of importance in long-distance quantum communication, and their discovery has shaped the field of quantum information processing. However, the usefulness of learning agents goes beyond the mere re-production of known protocols; the same approach allows one to find improved solutions to long-distance communication problems, in particular when dealing with asymmetric situations where channel noise and segment distance are non-uniform. Our findings are based on the use of projective simulation, a model of a learning agent that combines reinforcement learning and decision making in a physically motivated framework. The learning agent is provided with a universal gate set, and the desired task is specified via a reward scheme. From a technical perspective, the learning agent has to deal with stochastic environments and reactions. We utilize an idea reminiscent of hierarchical skill acquisition, where solutions to sub-problems are learned and re-used in the overall scheme. This is of particular importance in the development of long-distance communication schemes, and opens the way for using machine learning in the design and implementation of quantum networks.
Detecting quantum speedup by quantum walk with convolutional neural networks
Jan 30, 2019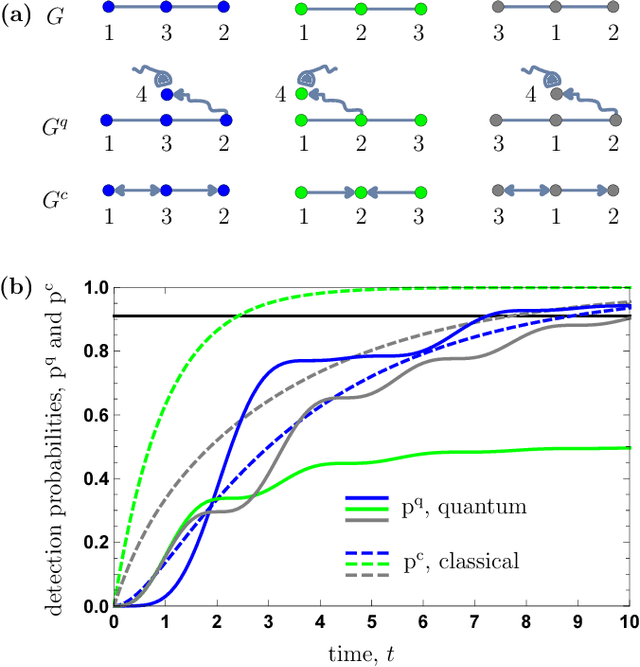
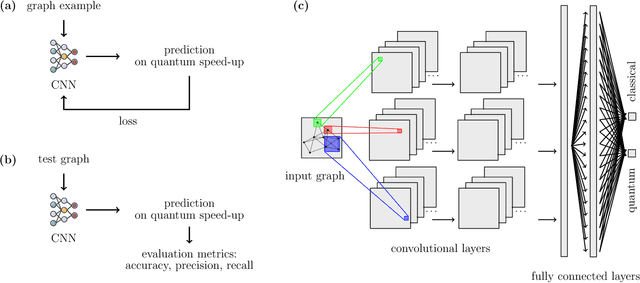
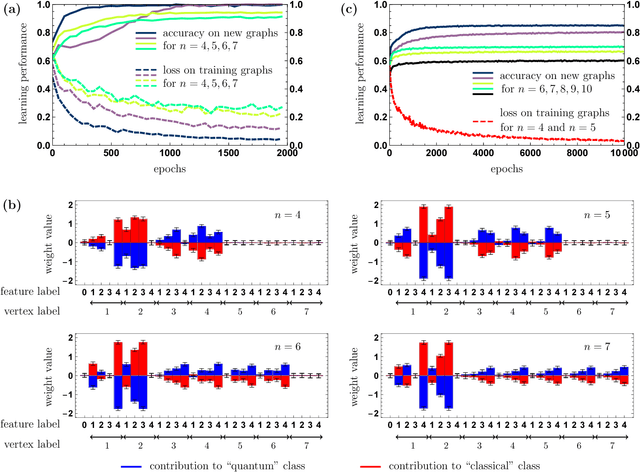

Quantum walks are at the heart of modern quantum technologies. They allow to deal with quantum transport phenomena and are an advanced tool for constructing novel quantum algorithms. Quantum walks on graphs are fundamentally different from classical random walks analogs, in particular, they walk faster than classical ones on certain graphs, enabling in these cases quantum algorithmic applications and quantum-enhanced energy transfer. However, little is known about the possible speedups on arbitrary graphs not having explicit symmetries. For these graphs one would need to perform simulations of classical and quantum walk dynamics to check if the speedup occurs, which could take a long computational time. Here we present a new approach for the solution of the quantum speedup problem, which is based on a machine learning algorithm that detects the quantum advantage by just looking at a graph. The convolutional neural network, which we designed specifically to learn from graphs, observes simulated examples and learns complex features of graphs that lead to a quantum speedup, allowing to identify graphs that exhibit quantum speedup without performing any quantum walk or random walk simulations. Our findings pave the way to an automated elaboration of novel large-scale quantum circuits utilizing quantum walk based algorithms, and to simulating high-efficiency energy transfer in biophotonics and material science.
Benchmarking projective simulation in navigation problems
Apr 23, 2018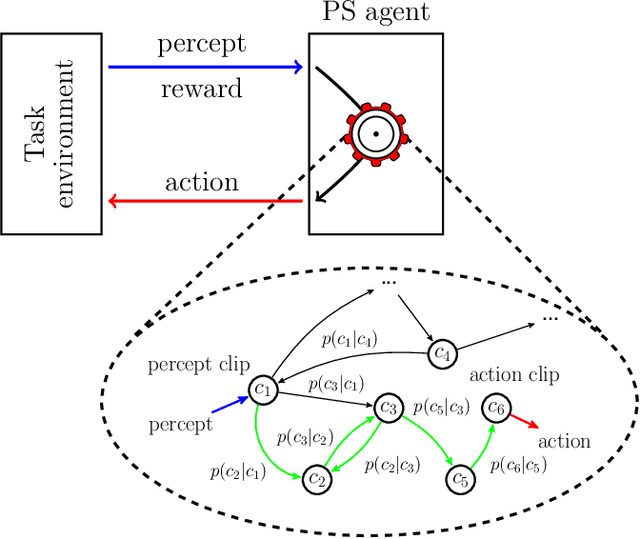
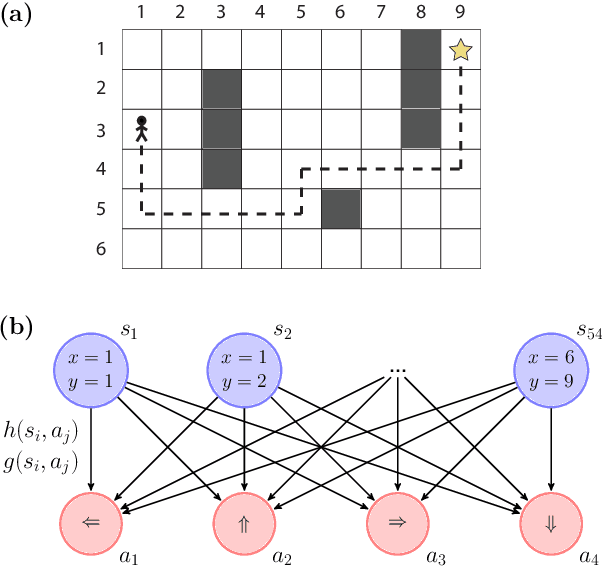
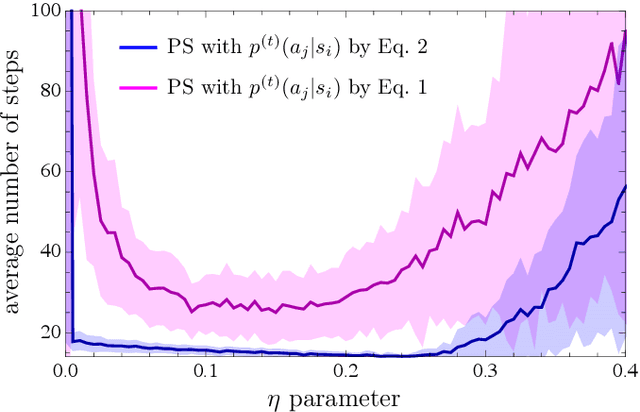
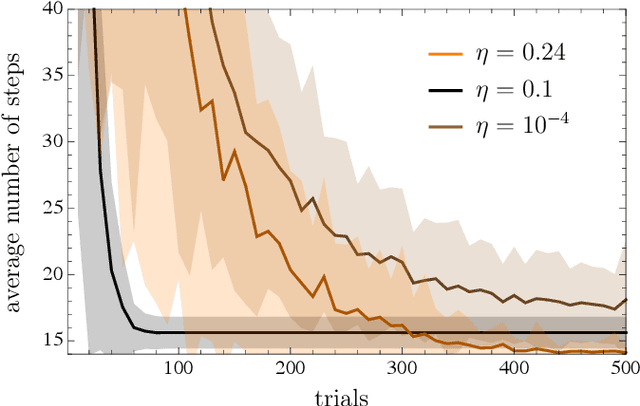
Projective simulation (PS) is a model for intelligent agents with a deliberation capacity that is based on episodic memory. The model has been shown to provide a flexible framework for constructing reinforcement-learning agents, and it allows for quantum mechanical generalization, which leads to a speed-up in deliberation time. PS agents have been applied successfully in the context of complex skill learning in robotics, and in the design of state-of-the-art quantum experiments. In this paper, we study the performance of projective simulation in two benchmarking problems in navigation, namely the grid world and the mountain car problem. The performance of PS is compared to standard tabular reinforcement learning approaches, Q-learning and SARSA. Our comparison demonstrates that the performance of PS and standard learning approaches are qualitatively and quantitatively similar, while it is much easier to choose optimal model parameters in case of projective simulation, with a reduced computational effort of one to two orders of magnitude. Our results show that the projective simulation model stands out for its simplicity in terms of the number of model parameters, which makes it simple to set up the learning agent in unknown task environments.
Active learning machine learns to create new quantum experiments
Feb 08, 2018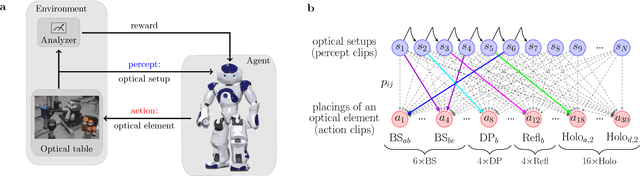
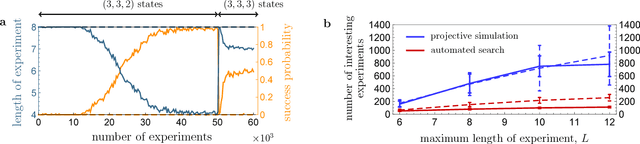
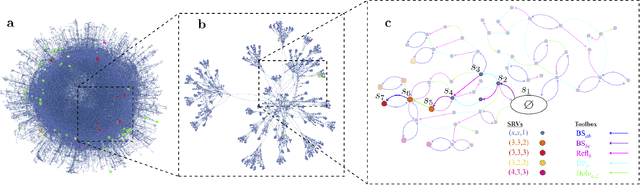
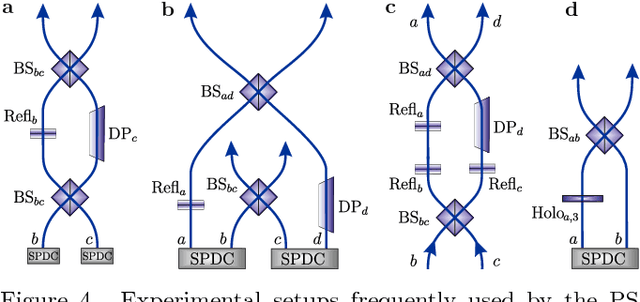
How useful can machine learning be in a quantum laboratory? Here we raise the question of the potential of intelligent machines in the context of scientific research. A major motivation for the present work is the unknown reachability of various entanglement classes in quantum experiments. We investigate this question by using the projective simulation model, a physics-oriented approach to artificial intelligence. In our approach, the projective simulation system is challenged to design complex photonic quantum experiments that produce high-dimensional entangled multiphoton states, which are of high interest in modern quantum experiments. The artificial intelligence system learns to create a variety of entangled states, and improves the efficiency of their realization. In the process, the system autonomously (re)discovers experimental techniques which are only now becoming standard in modern quantum optical experiments - a trait which was not explicitly demanded from the system but emerged through the process of learning. Such features highlight the possibility that machines could have a significantly more creative role in future research.
* 11 pages, 6 figures, 1 table; A. A. Melnikov and H. Poulsen Nautrup contributed equally to this work
Projective simulation with generalization
Oct 31, 2017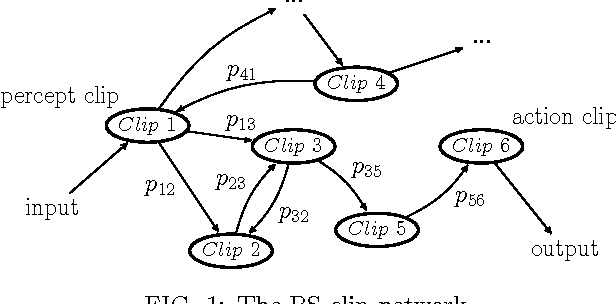
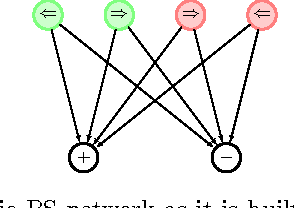
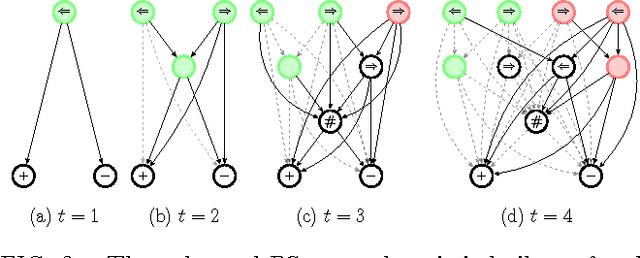
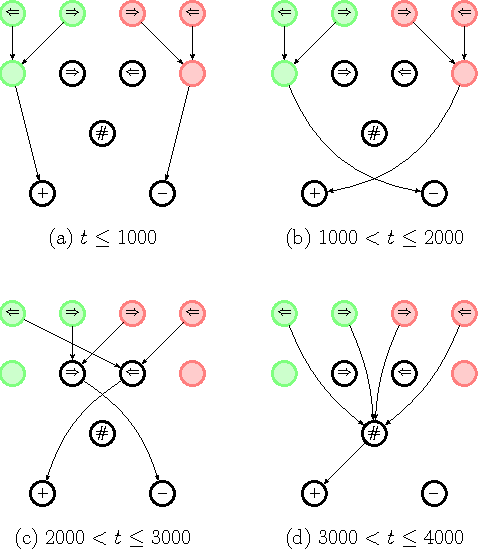
The ability to generalize is an important feature of any intelligent agent. Not only because it may allow the agent to cope with large amounts of data, but also because in some environments, an agent with no generalization capabilities cannot learn. In this work we outline several criteria for generalization, and present a dynamic and autonomous machinery that enables projective simulation agents to meaningfully generalize. Projective simulation, a novel, physical approach to artificial intelligence, was recently shown to perform well in standard reinforcement learning problems, with applications in advanced robotics as well as quantum experiments. Both the basic projective simulation model and the presented generalization machinery are based on very simple principles. This allows us to provide a full analytical analysis of the agent's performance and to illustrate the benefit the agent gains by generalizing. Specifically, we show that already in basic (but extreme) environments, learning without generalization may be impossible, and demonstrate how the presented generalization machinery enables the projective simulation agent to learn.
* 14 pages, 9 figures
Meta-learning within Projective Simulation
Feb 25, 2016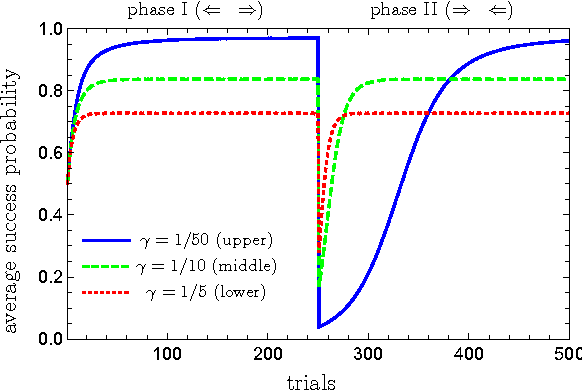
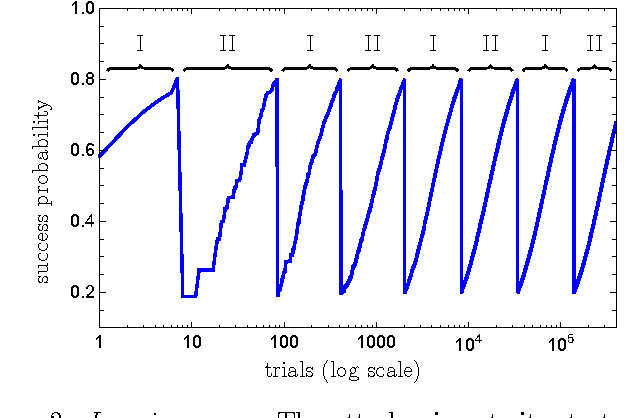
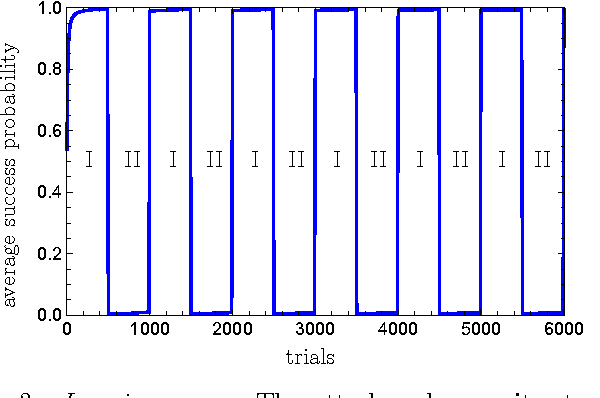
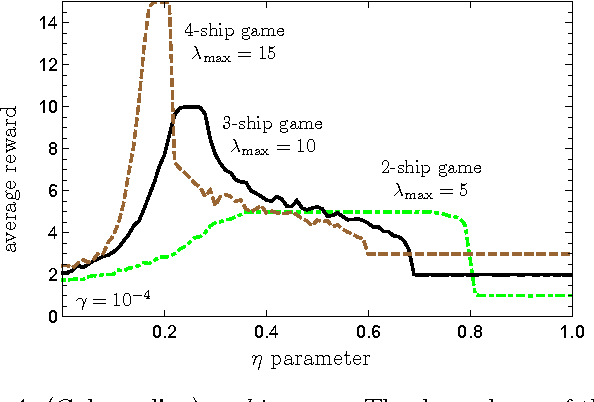
Learning models of artificial intelligence can nowadays perform very well on a large variety of tasks. However, in practice different task environments are best handled by different learning models, rather than a single, universal, approach. Most non-trivial models thus require the adjustment of several to many learning parameters, which is often done on a case-by-case basis by an external party. Meta-learning refers to the ability of an agent to autonomously and dynamically adjust its own learning parameters, or meta-parameters. In this work we show how projective simulation, a recently developed model of artificial intelligence, can naturally be extended to account for meta-learning in reinforcement learning settings. The projective simulation approach is based on a random walk process over a network of clips. The suggested meta-learning scheme builds upon the same design and employs clip networks to monitor the agent's performance and to adjust its meta-parameters "on the fly". We distinguish between "reflexive adaptation" and "adaptation through learning", and show the utility of both approaches. In addition, a trade-off between flexibility and learning-time is addressed. The extended model is examined on three different kinds of reinforcement learning tasks, in which the agent has different optimal values of the meta-parameters, and is shown to perform well, reaching near-optimal to optimal success rates in all of them, without ever needing to manually adjust any meta-parameter.
* 14 pages, 12 figures
Projective simulation applied to the grid-world and the mountain-car problem
May 21, 2014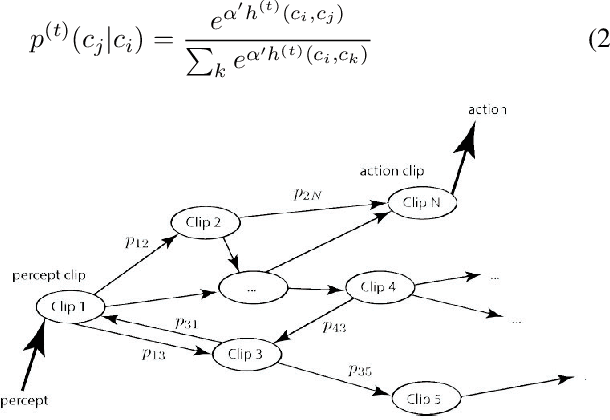

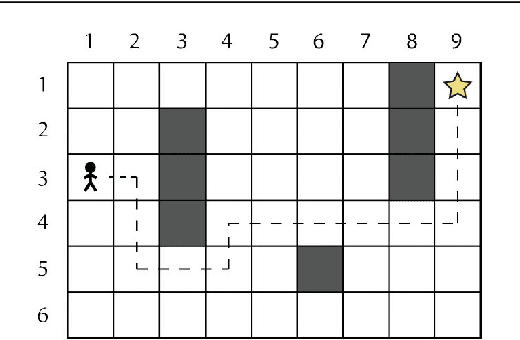

We study the model of projective simulation (PS) which is a novel approach to artificial intelligence (AI). Recently it was shown that the PS agent performs well in a number of simple task environments, also when compared to standard models of reinforcement learning (RL). In this paper we study the performance of the PS agent further in more complicated scenarios. To that end we chose two well-studied benchmarking problems, namely the "grid-world" and the "mountain-car" problem, which challenge the model with large and continuous input space. We compare the performance of the PS agent model with those of existing models and show that the PS agent exhibits competitive performance also in such scenarios.