 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking projective simulation in navigation problems
Apr 23, 2018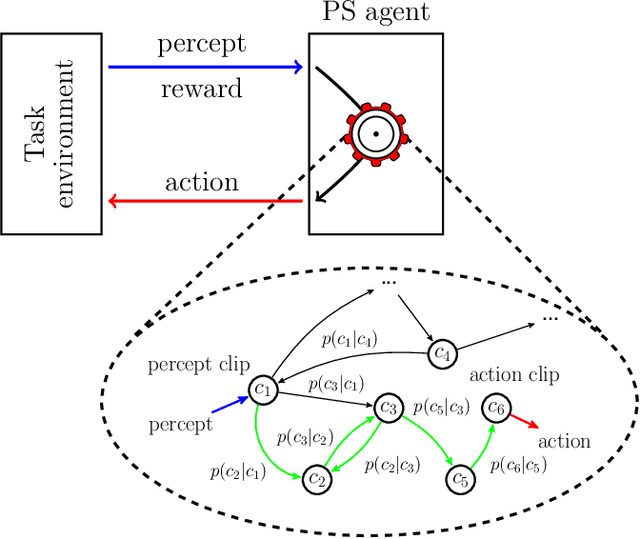
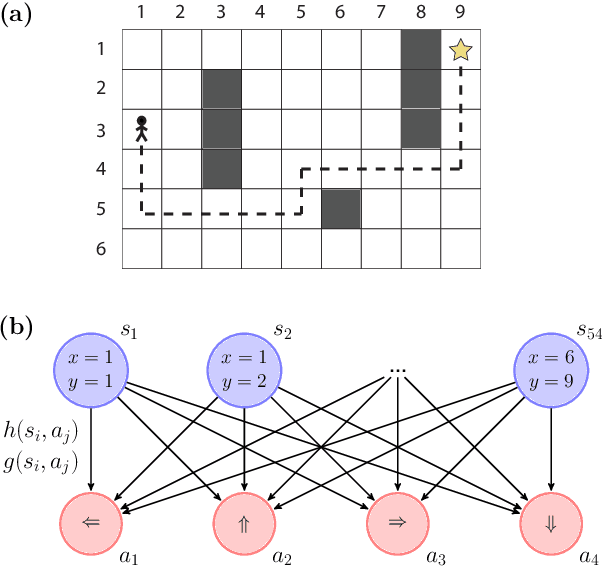
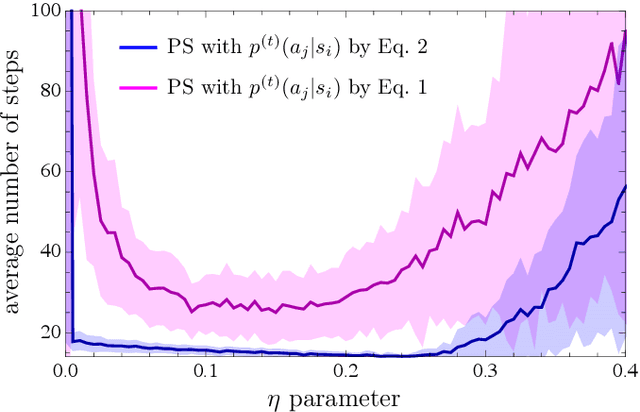
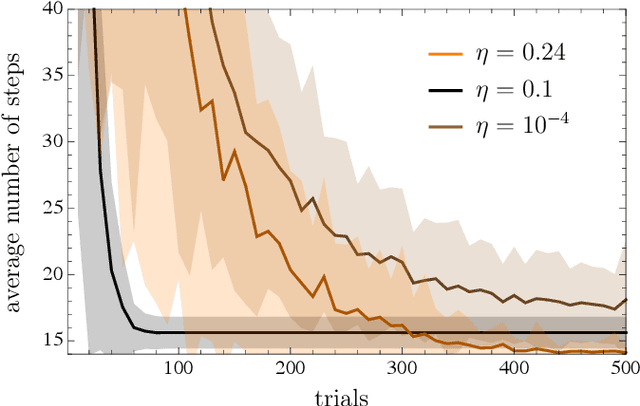
Projective simulation (PS) is a model for intelligent agents with a deliberation capacity that is based on episodic memory. The model has been shown to provide a flexible framework for constructing reinforcement-learning agents, and it allows for quantum mechanical generalization, which leads to a speed-up in deliberation time. PS agents have been applied successfully in the context of complex skill learning in robotics, and in the design of state-of-the-art quantum experiments. In this paper, we study the performance of projective simulation in two benchmarking problems in navigation, namely the grid world and the mountain car problem. The performance of PS is compared to standard tabular reinforcement learning approaches, Q-learning and SARSA. Our comparison demonstrates that the performance of PS and standard learning approaches are qualitatively and quantitatively similar, while it is much easier to choose optimal model parameters in case of projective simulation, with a reduced computational effort of one to two orders of magnitude. Our results show that the projective simulation model stands out for its simplicity in terms of the number of model parameters, which makes it simple to set up the learning agent in unknown task environments.
Projective simulation with generalization
Oct 31, 2017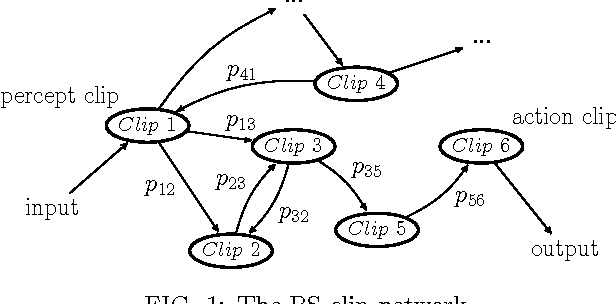
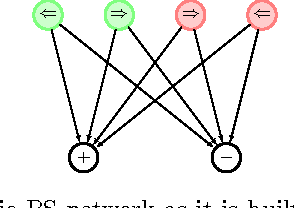
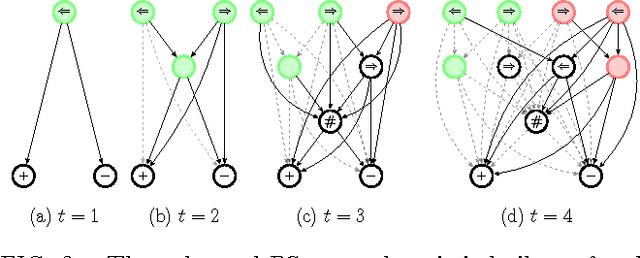
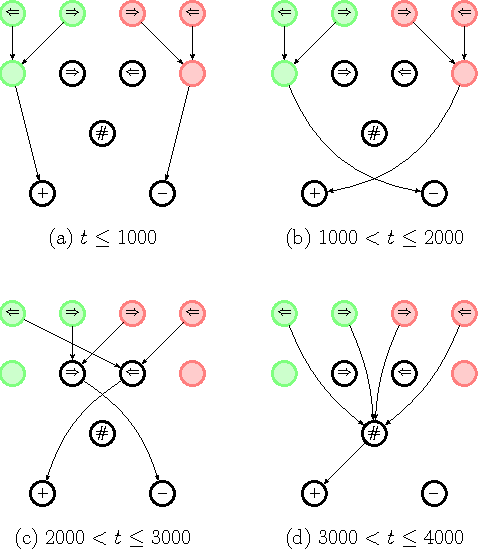
The ability to generalize is an important feature of any intelligent agent. Not only because it may allow the agent to cope with large amounts of data, but also because in some environments, an agent with no generalization capabilities cannot learn. In this work we outline several criteria for generalization, and present a dynamic and autonomous machinery that enables projective simulation agents to meaningfully generalize. Projective simulation, a novel, physical approach to artificial intelligence, was recently shown to perform well in standard reinforcement learning problems, with applications in advanced robotics as well as quantum experiments. Both the basic projective simulation model and the presented generalization machinery are based on very simple principles. This allows us to provide a full analytical analysis of the agent's performance and to illustrate the benefit the agent gains by generalizing. Specifically, we show that already in basic (but extreme) environments, learning without generalization may be impossible, and demonstrate how the presented generalization machinery enables the projective simulation agent to learn.
* 14 pages, 9 figures
Meta-learning within Projective Simulation
Feb 25, 2016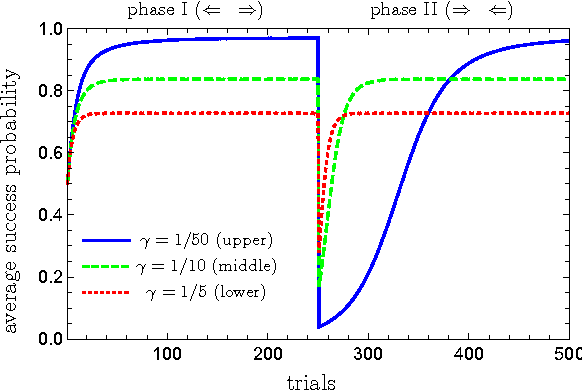
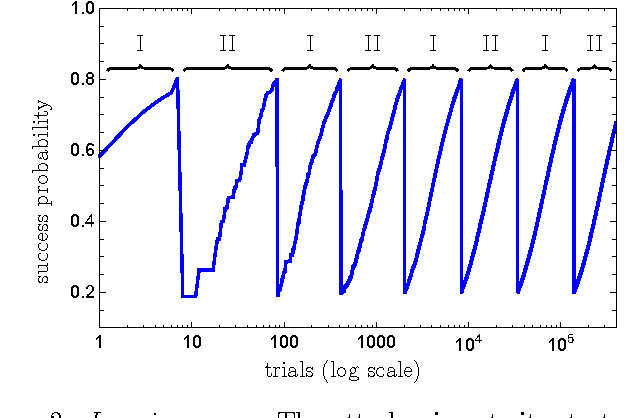
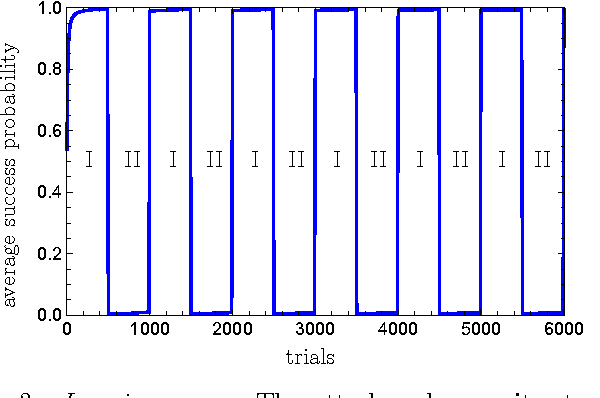
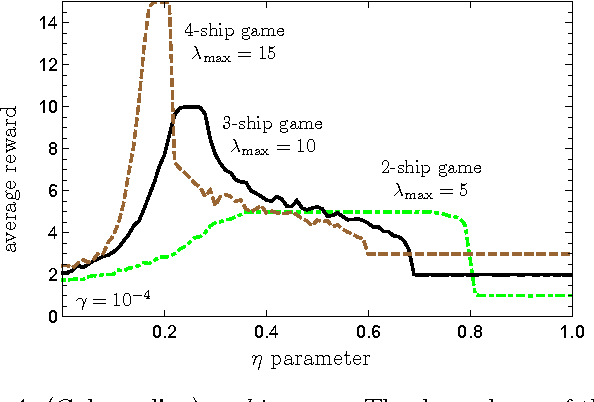
Learning models of artificial intelligence can nowadays perform very well on a large variety of tasks. However, in practice different task environments are best handled by different learning models, rather than a single, universal, approach. Most non-trivial models thus require the adjustment of several to many learning parameters, which is often done on a case-by-case basis by an external party. Meta-learning refers to the ability of an agent to autonomously and dynamically adjust its own learning parameters, or meta-parameters. In this work we show how projective simulation, a recently developed model of artificial intelligence, can naturally be extended to account for meta-learning in reinforcement learning settings. The projective simulation approach is based on a random walk process over a network of clips. The suggested meta-learning scheme builds upon the same design and employs clip networks to monitor the agent's performance and to adjust its meta-parameters "on the fly". We distinguish between "reflexive adaptation" and "adaptation through learning", and show the utility of both approaches. In addition, a trade-off between flexibility and learning-time is addressed. The extended model is examined on three different kinds of reinforcement learning tasks, in which the agent has different optimal values of the meta-parameters, and is shown to perform well, reaching near-optimal to optimal success rates in all of them, without ever needing to manually adjust any meta-parameter.
* 14 pages, 12 figures
Projective simulation for classical learning agents: a comprehensive investigation
Dec 01, 2014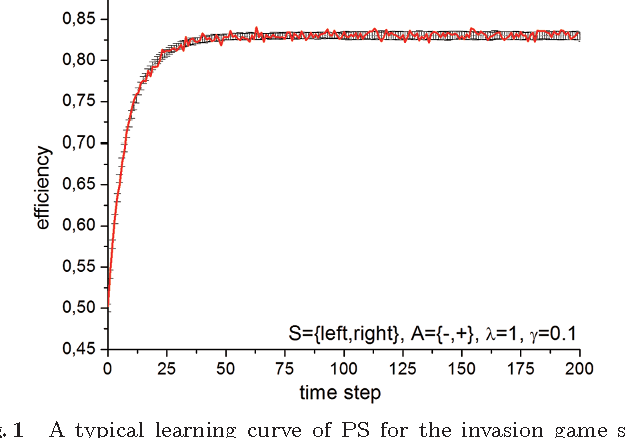

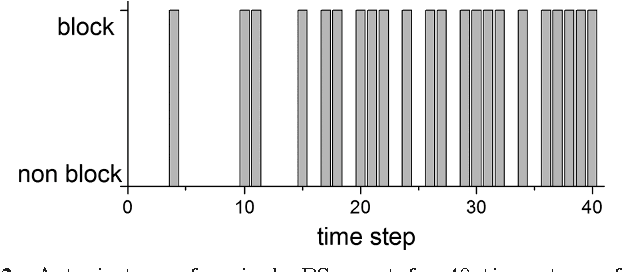
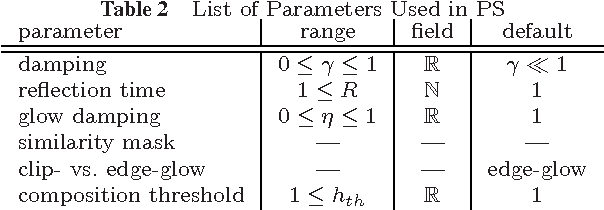
We study the model of projective simulation (PS), a novel approach to artificial intelligence based on stochastic processing of episodic memory which was recently introduced [H.J. Briegel and G. De las Cuevas. Sci. Rep. 2, 400, (2012)]. Here we provide a detailed analysis of the model and examine its performance, including its achievable efficiency, its learning times and the way both properties scale with the problems' dimension. In addition, we situate the PS agent in different learning scenarios, and study its learning abilities. A variety of new scenarios are being considered, thereby demonstrating the model's flexibility. Furthermore, to put the PS scheme in context, we compare its performance with those of Q-learning and learning classifier systems, two popular models in the field of reinforcement learning. It is shown that PS is a competitive artificial intelligence model of unique properties and strengths.
* Accepted for publication in New Generation Computing. 23 pages, 23 figures
Projective simulation applied to the grid-world and the mountain-car problem
May 21, 2014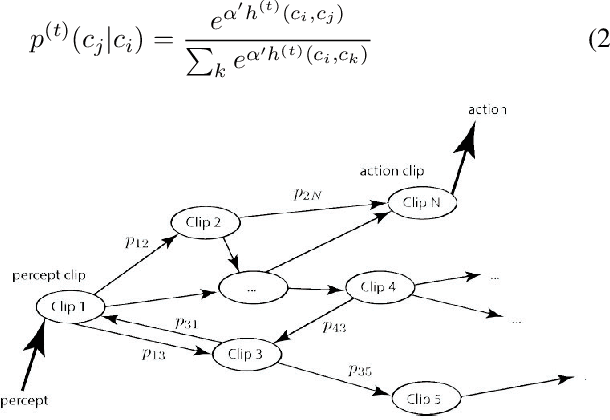

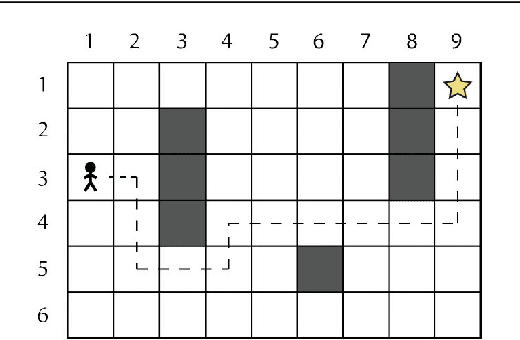

We study the model of projective simulation (PS) which is a novel approach to artificial intelligence (AI). Recently it was shown that the PS agent performs well in a number of simple task environments, also when compared to standard models of reinforcement learning (RL). In this paper we study the performance of the PS agent further in more complicated scenarios. To that end we chose two well-studied benchmarking problems, namely the "grid-world" and the "mountain-car" problem, which challenge the model with large and continuous input space. We compare the performance of the PS agent model with those of existing models and show that the PS agent exhibits competitive performance also in such scenarios.