 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Learning Take on the Concordance Index for Survival Analysis
Feb 23, 2023The introduction of machine learning (ML) techniques to the field of survival analysis has increased the flexibility of modeling approaches, and ML based models have become state-of-the-art. These models optimize their own cost functions, and their performance is often evaluated using the concordance index (C-index). From a statistical learning perspective, it is therefore an important problem to analyze the relationship between the optimizers of the C-index and those of the ML cost functions. We address this issue by providing C-index Fisher-consistency results and excess risk bounds for several of the commonly used cost functions in survival analysis. We identify conditions under which they are consistent, under the form of three nested families of survival models. We also study the general case where no model assumption is made and present a new, off-the-shelf method that is shown to be consistent with the C-index, although computationally expensive at inference. Finally, we perform limited numerical experiments with simulated data to illustrate our theoretical findings.
Max-Margin is Dead, Long Live Max-Margin!
Jun 18, 2021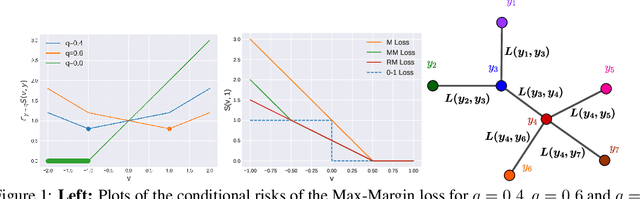
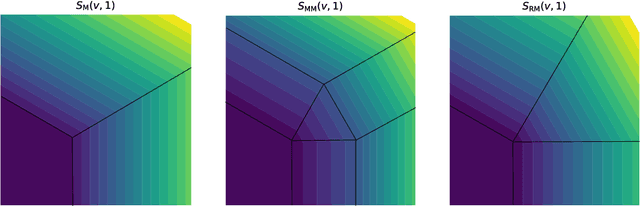
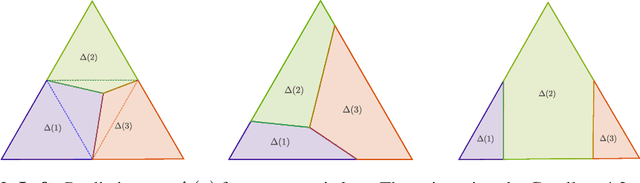
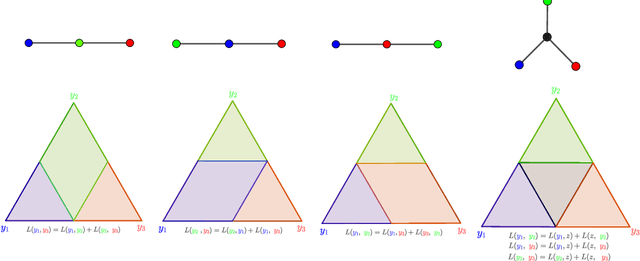
The foundational concept of Max-Margin in machine learning is ill-posed for output spaces with more than two labels such as in structured prediction. In this paper, we show that the Max-Margin loss can only be consistent to the classification task under highly restrictive assumptions on the discrete loss measuring the error between outputs. These conditions are satisfied by distances defined in tree graphs, for which we prove consistency, thus being the first losses shown to be consistent for Max-Margin beyond the binary setting. We finally address these limitations by correcting the concept of Max-Margin and introducing the Restricted-Max-Margin, where the maximization of the loss-augmented scores is maintained, but performed over a subset of the original domain. The resulting loss is also a generalization of the binary support vector machine and it is consistent under milder conditions on the discrete loss.
Consistent Structured Prediction with Max-Min Margin Markov Networks
Jul 02, 2020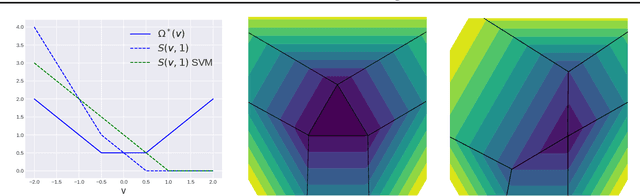
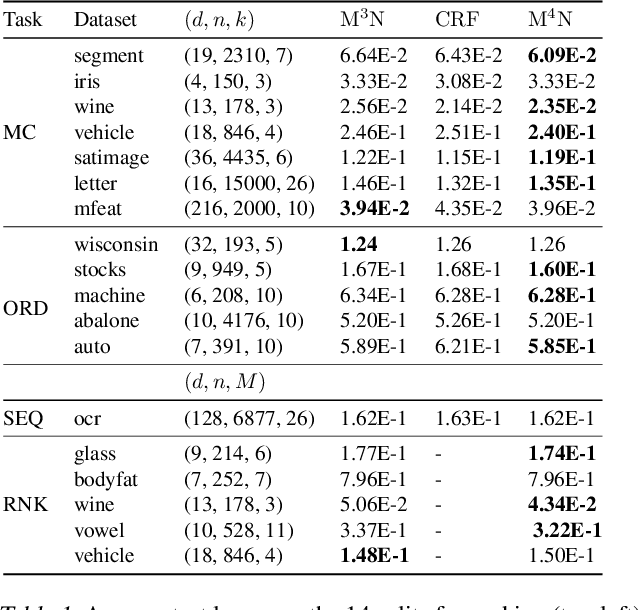

Max-margin methods for binary classification such as the support vector machine (SVM) have been extended to the structured prediction setting under the name of max-margin Markov networks ($M^3N$), or more generally structural SVMs. Unfortunately, these methods are statistically inconsistent when the relationship between inputs and labels is far from deterministic. We overcome such limitations by defining the learning problem in terms of a "max-min" margin formulation, naming the resulting method max-min margin Markov networks ($M^4N$). We prove consistency and finite sample generalization bounds for $M^4N$ and provide an explicit algorithm to compute the estimator. The algorithm achieves a generalization error of $O(1/\sqrt{n})$ for a total cost of $O(n)$ projection-oracle calls (which have at most the same cost as the max-oracle from $M^3N$). Experiments on multi-class classification, ordinal regression, sequence prediction and matching demonstrate the effectiveness of the proposed method.
Structured and Localized Image Restoration
Jun 16, 2020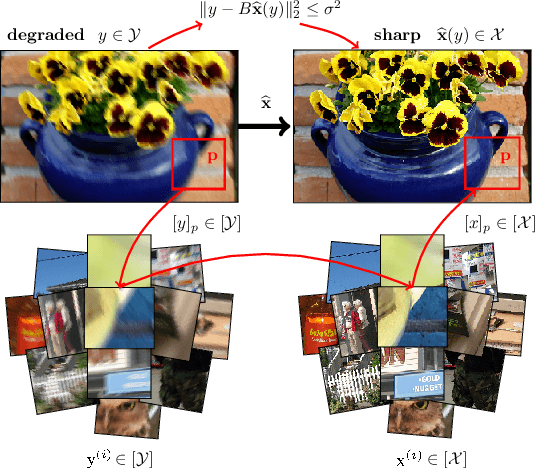


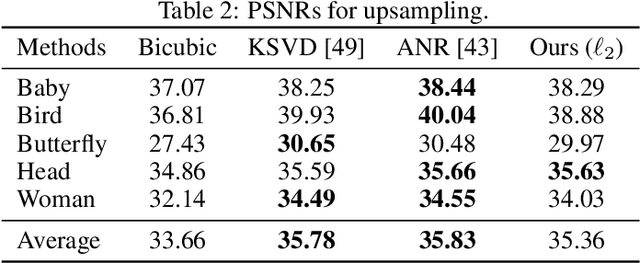
We present a novel approach to image restoration that leverages ideas from localized structured prediction and non-linear multi-task learning. We optimize a penalized energy function regularized by a sum of terms measuring the distance between patches to be restored and clean patches from an external database gathered beforehand. The resulting estimator comes with strong statistical guarantees leveraging local dependency properties of overlapping patches. We derive the corresponding algorithms for energies based on the mean-squared and Euclidean norm errors. Finally, we demonstrate the practical effectiveness of our model on different image restoration problems using standard benchmarks.
A General Theory for Structured Prediction with Smooth Convex Surrogates
Feb 13, 2019
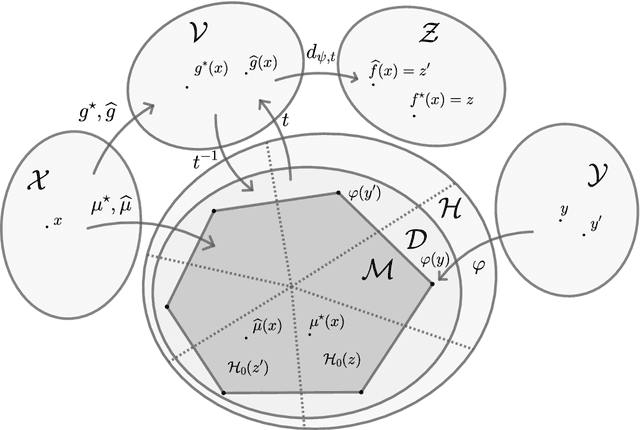
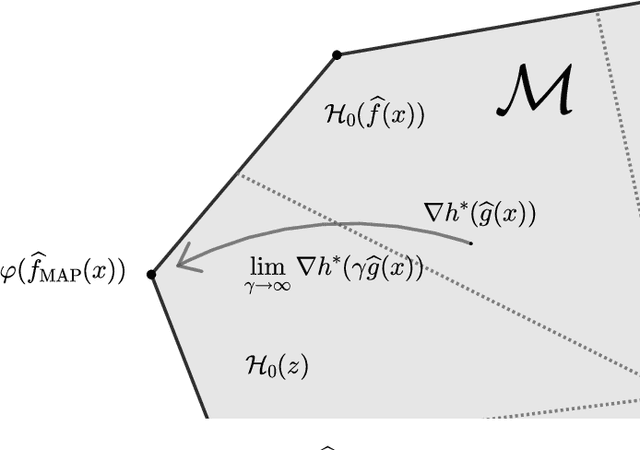
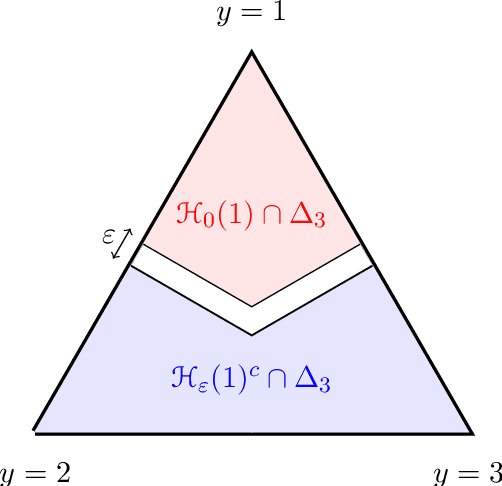
In this work we provide a theoretical framework for structured prediction that generalizes the existing theory of surrogate methods for binary and multiclass classification based on estimating conditional probabilities with smooth convex surrogates (e.g. logistic regression). The theory relies on a natural characterization of structural properties of the task loss and allows to derive statistical guarantees for many widely used methods in the context of multilabeling, ranking, ordinal regression and graph matching. In particular, we characterize the smooth convex surrogates compatible with a given task loss in terms of a suitable Bregman divergence composed with a link function. This allows to derive tight bounds for the calibration function and to obtain novel results on existing surrogate frameworks for structured prediction such as conditional random fields and quadratic surrogates.
Sharp Analysis of Learning with Discrete Losses
Oct 16, 2018

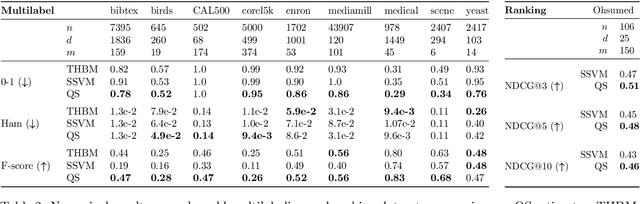
The problem of devising learning strategies for discrete losses (e.g., multilabeling, ranking) is currently addressed with methods and theoretical analyses ad-hoc for each loss. In this paper we study a least-squares framework to systematically design learning algorithms for discrete losses, with quantitative characterizations in terms of statistical and computational complexity. In particular we improve existing results by providing explicit dependence on the number of labels for a wide class of losses and faster learning rates in conditions of low-noise. Theoretical results are complemented with experiments on real datasets, showing the effectiveness of the proposed general approach.
Divide and Conquer Networks
Oct 14, 2018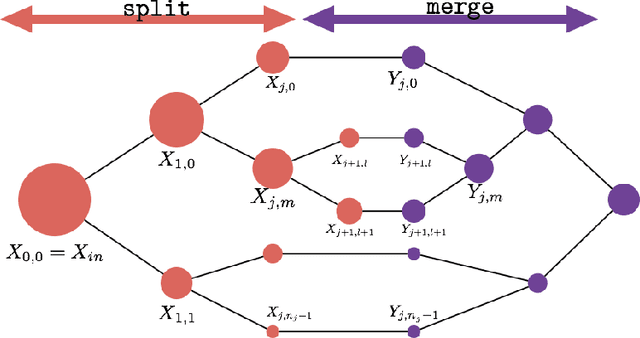
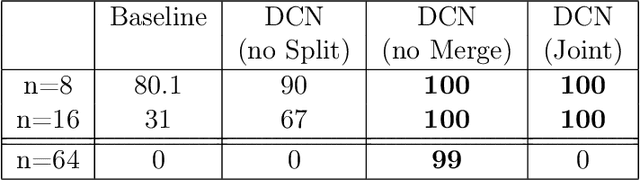
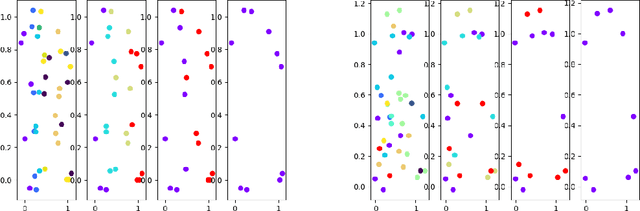
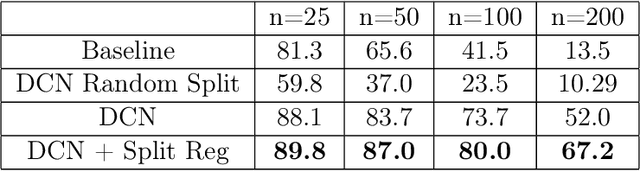
We consider the learning of algorithmic tasks by mere observation of input-output pairs. Rather than studying this as a black-box discrete regression problem with no assumption whatsoever on the input-output mapping, we concentrate on tasks that are amenable to the principle of divide and conquer, and study what are its implications in terms of learning. This principle creates a powerful inductive bias that we leverage with neural architectures that are defined recursively and dynamically, by learning two scale-invariant atomic operations: how to split a given input into smaller sets, and how to merge two partially solved tasks into a larger partial solution. Our model can be trained in weakly supervised environments, namely by just observing input-output pairs, and in even weaker environments, using a non-differentiable reward signal. Moreover, thanks to the dynamic aspect of our architecture, we can incorporate the computational complexity as a regularization term that can be optimized by backpropagation. We demonstrate the flexibility and efficiency of the Divide-and-Conquer Network on several combinatorial and geometric tasks: convex hull, clustering, knapsack and euclidean TSP. Thanks to the dynamic programming nature of our model, we show significant improvements in terms of generalization error and computational complexity.