 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Machine Learning with Computational Fluid Dynamics using OpenFOAM and SmartSim
Feb 25, 2024Combining machine learning (ML) with computational fluid dynamics (CFD) opens many possibilities for improving simulations of technical and natural systems. However, CFD+ML algorithms require exchange of data, synchronization, and calculation on heterogeneous hardware, making their implementation for large-scale problems exceptionally challenging. We provide an effective and scalable solution to developing CFD+ML algorithms using open source software OpenFOAM and SmartSim. SmartSim provides an Orchestrator that significantly simplifies the programming of CFD+ML algorithms and a Redis database that ensures highly scalable data exchange between ML and CFD clients. We show how to leverage SmartSim to effectively couple different segments of OpenFOAM with ML, including pre/post-processing applications, solvers, function objects, and mesh motion solvers. We additionally provide an OpenFOAM sub-module with examples that can be used as starting points for real-world applications in CFD+ML.
In Situ Framework for Coupling Simulation and Machine Learning with Application to CFD
Jun 22, 2023Recent years have seen many successful applications of machine learning (ML) to facilitate fluid dynamic computations. As simulations grow, generating new training datasets for traditional offline learning creates I/O and storage bottlenecks. Additionally, performing inference at runtime requires non-trivial coupling of ML framework libraries with simulation codes. This work offers a solution to both limitations by simplifying this coupling and enabling in situ training and inference workflows on heterogeneous clusters. Leveraging SmartSim, the presented framework deploys a database to store data and ML models in memory, thus circumventing the file system. On the Polaris supercomputer, we demonstrate perfect scaling efficiency to the full machine size of the data transfer and inference costs thanks to a novel co-located deployment of the database. Moreover, we train an autoencoder in situ from a turbulent flow simulation, showing that the framework overhead is negligible relative to a solver time step and training epoch.
Using Machine Learning at Scale in HPC Simulations with SmartSim: An Application to Ocean Climate Modeling
Apr 13, 2021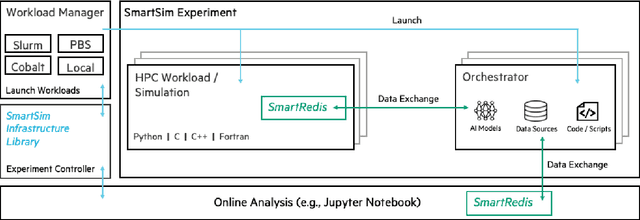

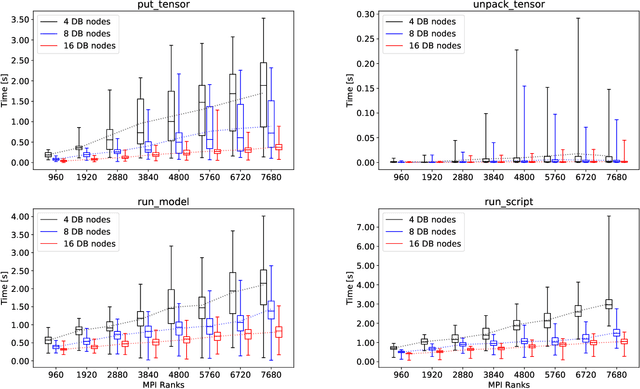
We demonstrate the first climate-scale, numerical ocean simulations improved through distributed, online inference of Deep Neural Networks (DNN) using SmartSim. SmartSim is a library dedicated to enabling online analysis and Machine Learning (ML) for traditional HPC simulations. In this paper, we detail the SmartSim architecture and provide benchmarks including online inference with a shared ML model on heterogeneous HPC systems. We demonstrate the capability of SmartSim by using it to run a 12-member ensemble of global-scale, high-resolution ocean simulations, each spanning 19 compute nodes, all communicating with the same ML architecture at each simulation timestep. In total, 970 billion inferences are collectively served by running the ensemble for a total of 120 simulated years. Finally, we show our solution is stable over the full duration of the model integrations, and that the inclusion of machine learning has minimal impact on the simulation runtimes.
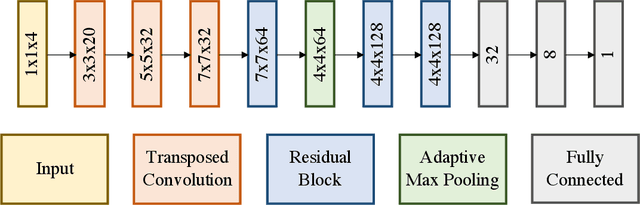
DC-S3GD: Delay-Compensated Stale-Synchronous SGD for Large-Scale Decentralized Neural Network Training
Nov 06, 2019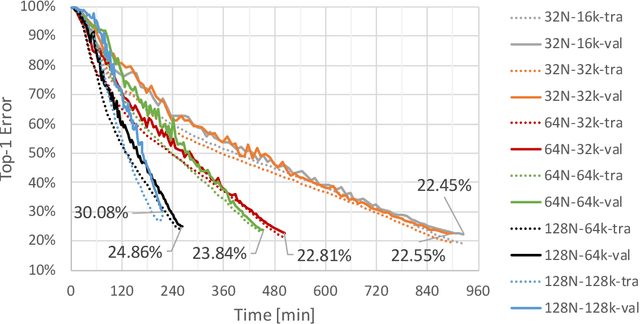
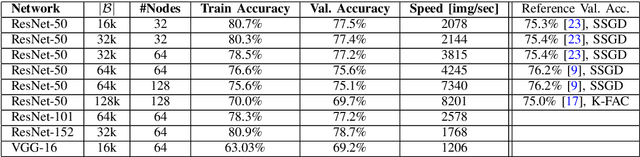
Data parallelism has become the de facto standard for training Deep Neural Network on multiple processing units. In this work we propose DC-S3GD, a decentralized (without Parameter Server) stale-synchronous version of the Delay-Compensated Asynchronous Stochastic Gradient Descent (DC-ASGD) algorithm. In our approach, we allow for the overlap of computation and communication, and compensate the inherent error with a first-order correction of the gradients. We prove the effectiveness of our approach by training Convolutional Neural Network with large batches and achieving state-of-the-art results.
Recombination of Artificial Neural Networks
Jan 12, 2019
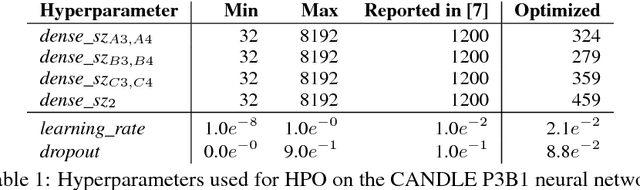
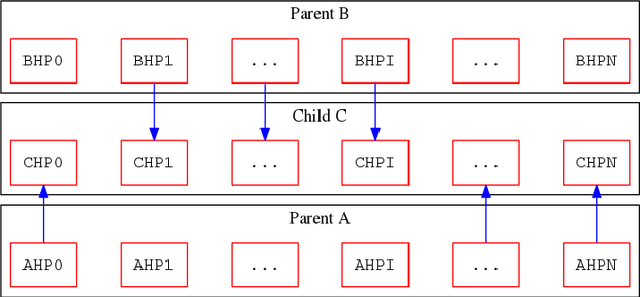

We propose a genetic algorithm (GA) for hyperparameter optimization of artificial neural networks which includes chromosomal crossover as well as a decoupling of parameters (i.e., weights and biases) from hyperparameters (e.g., learning rate, weight decay, and dropout) during sexual reproduction. Children are produced from three parents; two contributing hyperparameters and one contributing the parameters. Our version of population-based training (PBT) combines traditional gradient-based approaches such as stochastic gradient descent (SGD) with our GA to optimize both parameters and hyperparameters across SGD epochs. Our improvements over traditional PBT provide an increased speed of adaptation and a greater ability to shed deleterious genes from the population. Our methods improve final accuracy as well as time to fixed accuracy on a wide range of deep neural network architectures including convolutional neural networks, recurrent neural networks, dense neural networks, and capsule networks.