 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForm follows Function: Text-to-Text Conditional Graph Generation based on Functional Requirements
Nov 01, 2023



This work focuses on the novel problem setting of generating graphs conditioned on a description of the graph's functional requirements in a downstream task. We pose the problem as a text-to-text generation problem and focus on the approach of fine-tuning a pretrained large language model (LLM) to generate graphs. We propose an inductive bias which incorporates information about the structure of the graph into the LLM's generation process by incorporating message passing layers into an LLM's architecture. To evaluate our proposed method, we design a novel set of experiments using publicly available and widely studied molecule and knowledge graph data sets. Results suggest our proposed approach generates graphs which more closely meet the requested functional requirements, outperforming baselines developed on similar tasks by a statistically significant margin.
A Hybrid Model for Forecasting Short-Term Electricity Demand
May 20, 2022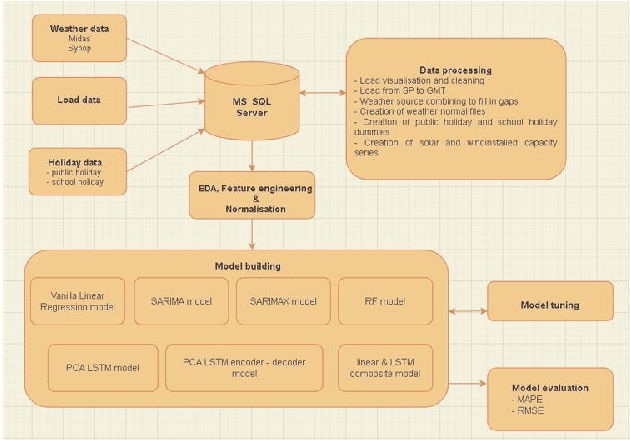
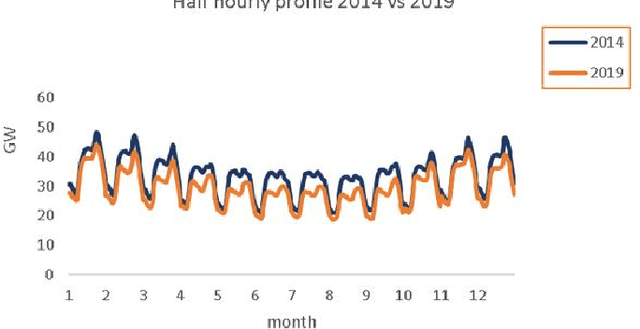
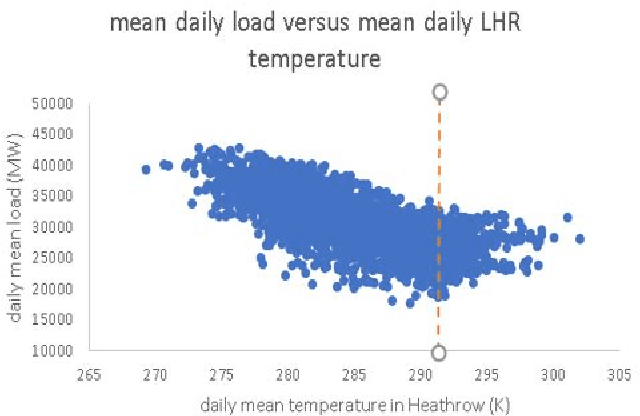
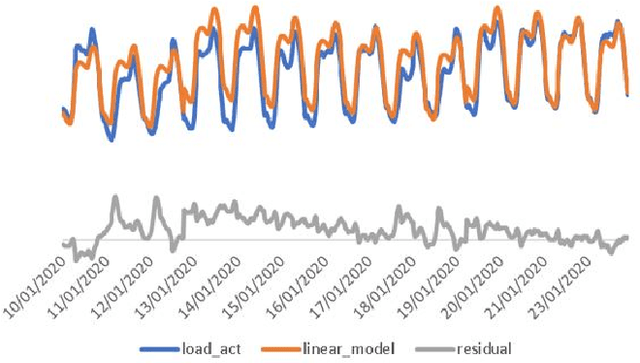
Currently the UK Electric market is guided by load (demand) forecasts published every thirty minutes by the regulator. A key factor in predicting demand is weather conditions, with forecasts published every hour. We present HYENA: a hybrid predictive model that combines feature engineering (selection of the candidate predictor features), mobile-window predictors and finally LSTM encoder-decoders to achieve higher accuracy with respect to mainstream models from the literature. HYENA decreased MAPE loss by 16\% and RMSE loss by 10\% over the best available benchmark model, thus establishing a new state of the art for the UK electric load (and price) forecasting.
Deep Incremental Boosting
Aug 11, 2017



This paper introduces Deep Incremental Boosting, a new technique derived from AdaBoost, specifically adapted to work with Deep Learning methods, that reduces the required training time and improves generalisation. We draw inspiration from Transfer of Learning approaches to reduce the start-up time to training each incremental Ensemble member. We show a set of experiments that outlines some preliminary results on some common Deep Learning datasets and discuss the potential improvements Deep Incremental Boosting brings to traditional Ensemble methods in Deep Learning.
Adapting Resilient Propagation for Deep Learning
Sep 16, 2015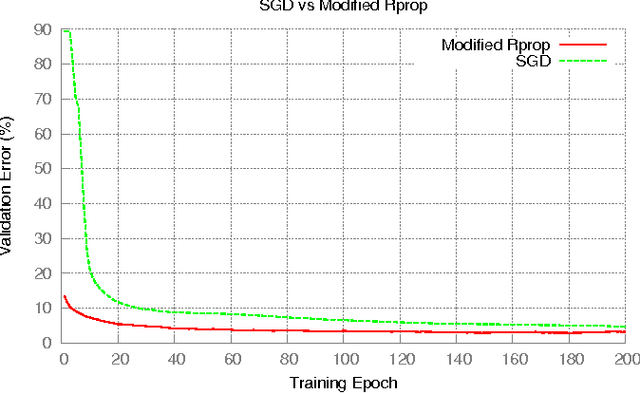
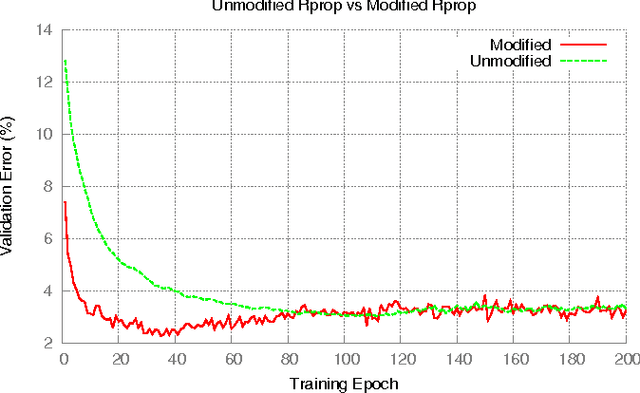
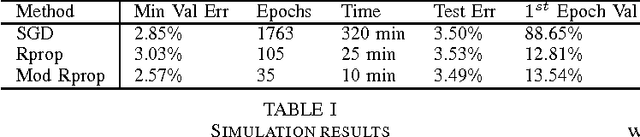
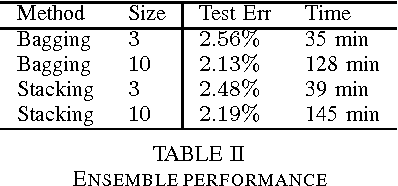
The Resilient Propagation (Rprop) algorithm has been very popular for backpropagation training of multilayer feed-forward neural networks in various applications. The standard Rprop however encounters difficulties in the context of deep neural networks as typically happens with gradient-based learning algorithms. In this paper, we propose a modification of the Rprop that combines standard Rprop steps with a special drop out technique. We apply the method for training Deep Neural Networks as standalone components and in ensemble formulations. Results on the MNIST dataset show that the proposed modification alleviates standard Rprop's problems demonstrating improved learning speed and accuracy.