 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Seriousness of Injury in a Traffic Accident: A New Imbalanced Dataset and Benchmark
May 20, 2022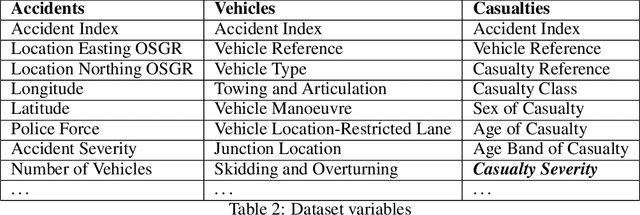
The paper introduces a new dataset to assess the performance of machine learning algorithms in the prediction of the seriousness of injury in a traffic accident. The dataset is created by aggregating publicly available datasets from the UK Department for Transport, which are drastically imbalanced with missing attributes sometimes approaching 50\% of the overall data dimensionality. The paper presents the data analysis pipeline starting from the publicly available data of road traffic accidents and ending with predictors of possible injuries and their degree of severity. It addresses the huge incompleteness of public data with a MissForest model. The paper also introduces two baseline approaches to create injury predictors: a supervised artificial neural network and a reinforcement learning model. The dataset can potentially stimulate diverse aspects of machine learning research on imbalanced datasets and the two approaches can be used as baseline references when researchers test more advanced learning algorithms in this area.
Adapting Resilient Propagation for Deep Learning
Sep 16, 2015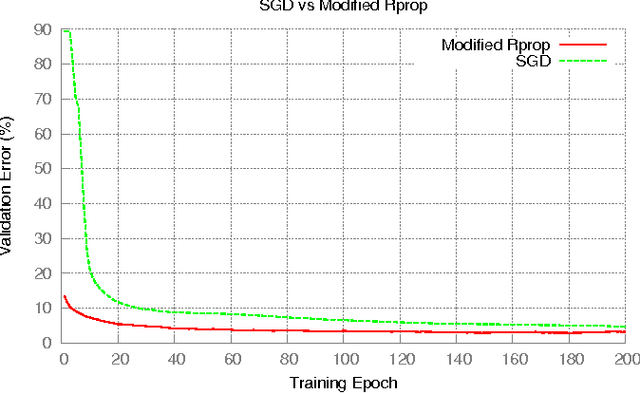
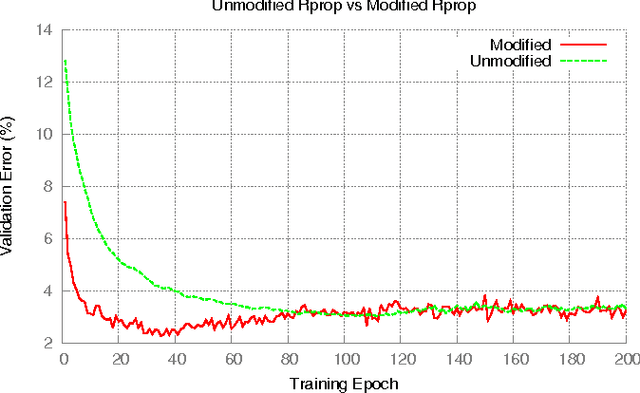
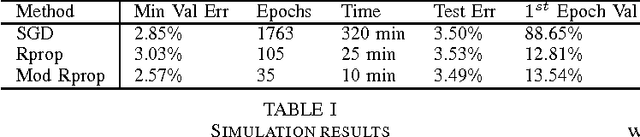
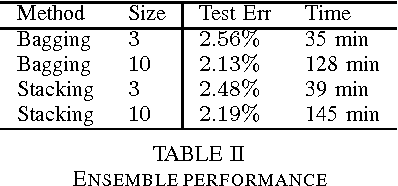
The Resilient Propagation (Rprop) algorithm has been very popular for backpropagation training of multilayer feed-forward neural networks in various applications. The standard Rprop however encounters difficulties in the context of deep neural networks as typically happens with gradient-based learning algorithms. In this paper, we propose a modification of the Rprop that combines standard Rprop steps with a special drop out technique. We apply the method for training Deep Neural Networks as standalone components and in ensemble formulations. Results on the MNIST dataset show that the proposed modification alleviates standard Rprop's problems demonstrating improved learning speed and accuracy.
Transfer learning approach for financial applications
Sep 09, 2015



Artificial neural networks learn how to solve new problems through a computationally intense and time consuming process. One way to reduce the amount of time required is to inject preexisting knowledge into the network. To make use of past knowledge, we can take advantage of techniques that transfer the knowledge learned from one task, and reuse it on another (sometimes unrelated) task. In this paper we propose a novel selective breeding technique that extends the transfer learning with behavioural genetics approach proposed by Kohli, Magoulas and Thomas (2013), and evaluate its performance on financial data. Numerical evidence demonstrates the credibility of the new approach. We provide insights on the operation of transfer learning and highlight the benefits of using behavioural principles and selective breeding when tackling a set of diverse financial applications problems.
Evolving Stochastic Learning Algorithm Based on Tsallis Entropic Index
Dec 13, 2005



In this paper, inspired from our previous algorithm, which was based on the theory of Tsallis statistical mechanics, we develop a new evolving stochastic learning algorithm for neural networks. The new algorithm combines deterministic and stochastic search steps by employing a different adaptive stepsize for each network weight, and applies a form of noise that is characterized by the nonextensive entropic index q, regulated by a weight decay term. The behavior of the learning algorithm can be made more stochastic or deterministic depending on the trade off between the temperature T and the q values. This is achieved by introducing a formula that defines a time--dependent relationship between these two important learning parameters. Our experimental study verifies that there are indeed improvements in the convergence speed of this new evolving stochastic learning algorithm, which makes learning faster than using the original Hybrid Learning Scheme (HLS). In addition, experiments are conducted to explore the influence of the entropic index q and temperature T on the convergence speed and stability of the proposed method.