 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Model for Forecasting Short-Term Electricity Demand
May 20, 2022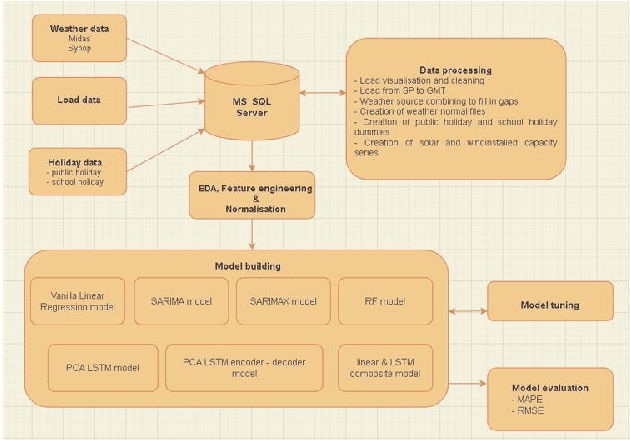
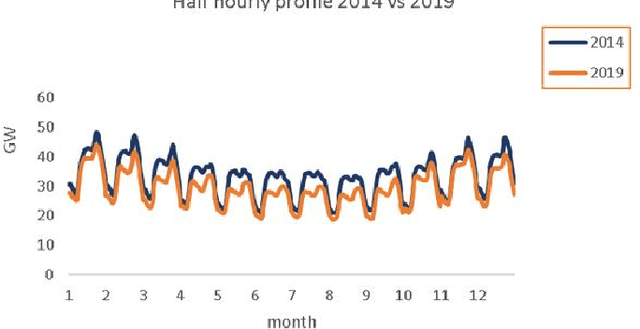
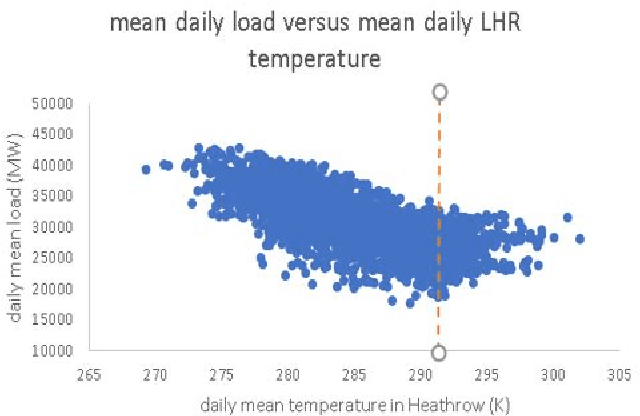
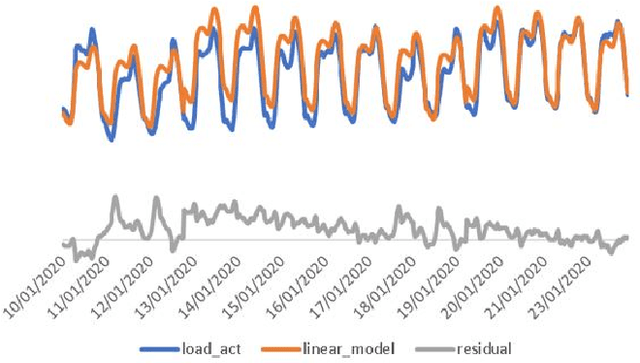
Currently the UK Electric market is guided by load (demand) forecasts published every thirty minutes by the regulator. A key factor in predicting demand is weather conditions, with forecasts published every hour. We present HYENA: a hybrid predictive model that combines feature engineering (selection of the candidate predictor features), mobile-window predictors and finally LSTM encoder-decoders to achieve higher accuracy with respect to mainstream models from the literature. HYENA decreased MAPE loss by 16\% and RMSE loss by 10\% over the best available benchmark model, thus establishing a new state of the art for the UK electric load (and price) forecasting.
Predicting Seriousness of Injury in a Traffic Accident: A New Imbalanced Dataset and Benchmark
May 20, 2022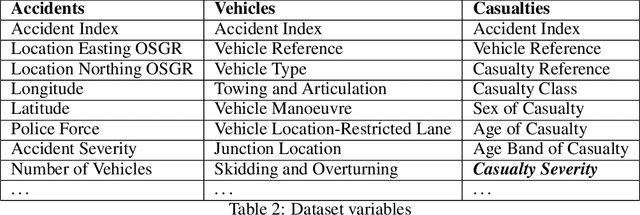
The paper introduces a new dataset to assess the performance of machine learning algorithms in the prediction of the seriousness of injury in a traffic accident. The dataset is created by aggregating publicly available datasets from the UK Department for Transport, which are drastically imbalanced with missing attributes sometimes approaching 50\% of the overall data dimensionality. The paper presents the data analysis pipeline starting from the publicly available data of road traffic accidents and ending with predictors of possible injuries and their degree of severity. It addresses the huge incompleteness of public data with a MissForest model. The paper also introduces two baseline approaches to create injury predictors: a supervised artificial neural network and a reinforcement learning model. The dataset can potentially stimulate diverse aspects of machine learning research on imbalanced datasets and the two approaches can be used as baseline references when researchers test more advanced learning algorithms in this area.
A Sentiment Analysis Approach to the Prediction of Market Volatility
Dec 10, 2020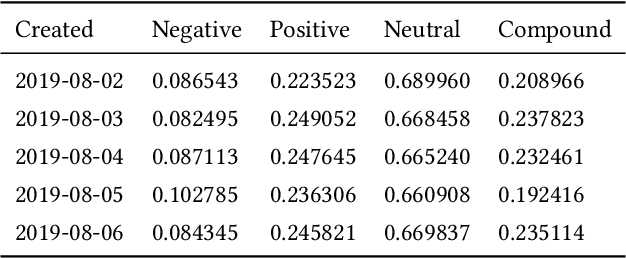
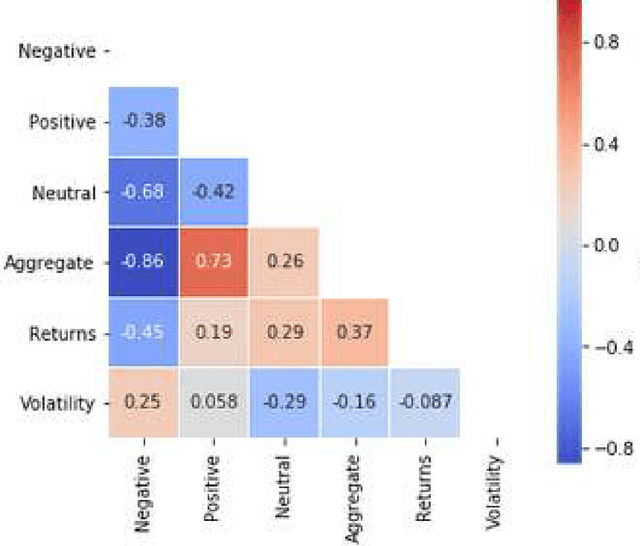
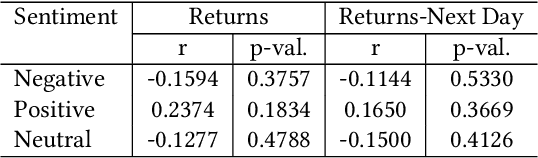
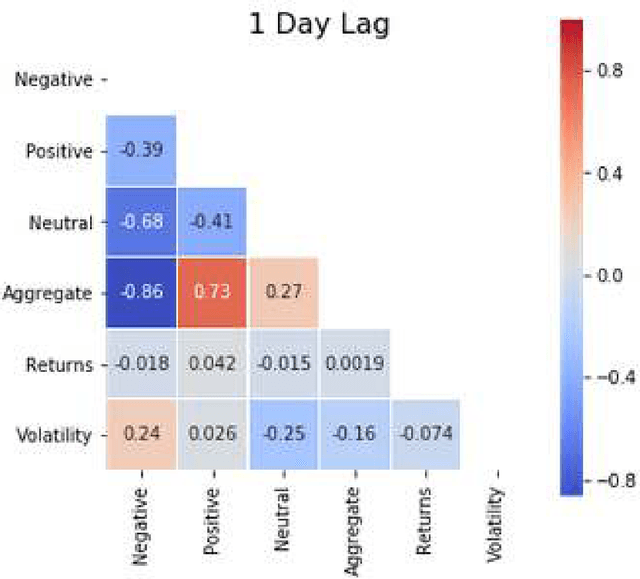
Prediction and quantification of future volatility and returns play an important role in financial modelling, both in portfolio optimization and risk management. Natural language processing today allows to process news and social media comments to detect signals of investors' confidence. We have explored the relationship between sentiment extracted from financial news and tweets and FTSE100 movements. We investigated the strength of the correlation between sentiment measures on a given day and market volatility and returns observed the next day. The findings suggest that there is evidence of correlation between sentiment and stock market movements: the sentiment captured from news headlines could be used as a signal to predict market returns; the same does not apply for volatility. Also, in a surprising finding, for the sentiment found in Twitter comments we obtained a correlation coefficient of -0.7, and p-value below 0.05, which indicates a strong negative correlation between positive sentiment captured from the tweets on a given day and the volatility observed the next day. We developed an accurate classifier for the prediction of market volatility in response to the arrival of new information by deploying topic modelling, based on Latent Dirichlet Allocation, to extract feature vectors from a collection of tweets and financial news. The obtained features were used as additional input to the classifier. Thanks to the combination of sentiment and topic modelling our classifier achieved a directional prediction accuracy for volatility of 63%.
Qsmodels: ASP Planning in Interactive Gaming Environment
May 27, 2015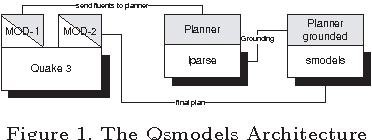
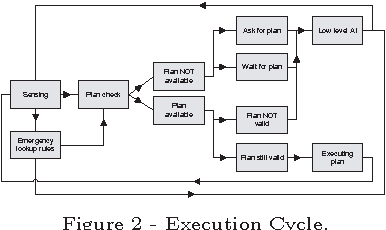
Qsmodels is a novel application of Answer Set Programming to interactive gaming environment. We describe a software architecture by which the behavior of a bot acting inside the Quake 3 Arena can be controlled by a planner. The planner is written as an Answer Set Program and is interpreted by the Smodels solver.
RDF annotation of Second Life objects: Knowledge Representation meets Social Virtual reality
Apr 09, 2015

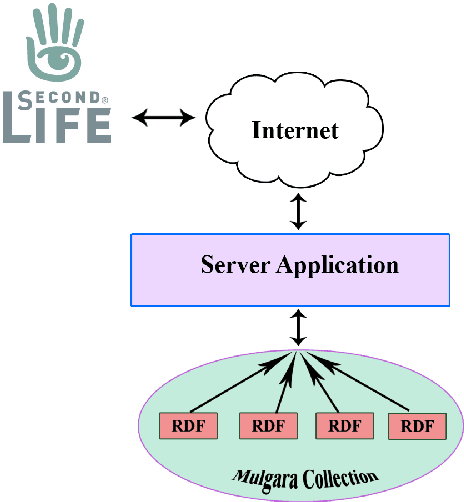
We have designed and implemented an application running inside Second Life that supports user annotation of graphical objects and graphical visualization of concept ontologies, thus providing a formal, machine-accessible description of objects. As a result, we offer a platform that combines the graphical knowledge representation that is expected from a MUVE artifact with the semantic structure given by the Resource Framework Description (RDF) representation of information.
* The final publication is available at link.springer.com
Characterizing and computing stable models of logic programs: The non-stratified case
Feb 21, 2014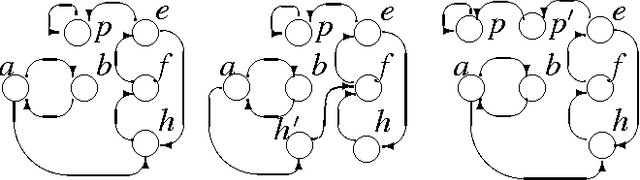
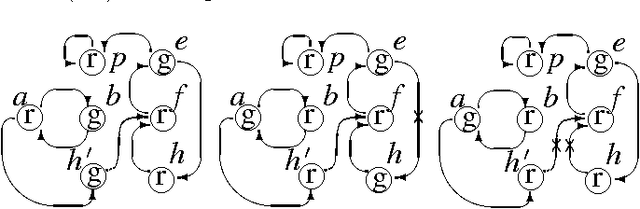
Stable Logic Programming (SLP) is an emergent, alternative style of logic programming: each solution to a problem is represented by a stable model of a deductive database/function-free logic program encoding the problem itself. Several implementations now exist for stable logic programming, and their performance is rapidly improving. To make SLP generally applicable, it should be possible to check for consistency (i.e., existence of stable models) of the input program before attempting to answer queries. In the literature, only rather strong sufficient conditions have been proposed for consistency, e.g., stratification. This paper extends these results in several directions. First, the syntactic features of programs, viz. cyclic negative dependencies, affecting the existence of stable models are characterized, and their relevance is discussed. Next, a new graph representation of logic programs, the Extended Dependency Graph (EDG), is introduced, which conveys enough information for reasoning about stable models (while the traditional Dependency Graph does not). Finally, we show that the problem of the existence of stable models can be reformulated in terms of coloring of the EDG.
A primer on Answer Set Programming
Aug 23, 2005A introduction to the syntax and Semantics of Answer Set Programming intended as an handout to [under]graduate students taking Artificial Intlligence or Logic Programming classes.
Normal forms for Answer Sets Programming
Oct 06, 2004Normal forms for logic programs under stable/answer set semantics are introduced. We argue that these forms can simplify the study of program properties, mainly consistency. The first normal form, called the {\em kernel} of the program, is useful for studying existence and number of answer sets. A kernel program is composed of the atoms which are undefined in the Well-founded semantics, which are those that directly affect the existence of answer sets. The body of rules is composed of negative literals only. Thus, the kernel form tends to be significantly more compact than other formulations. Also, it is possible to check consistency of kernel programs in terms of colorings of the Extended Dependency Graph program representation which we previously developed. The second normal form is called {\em 3-kernel.} A 3-kernel program is composed of the atoms which are undefined in the Well-founded semantics. Rules in 3-kernel programs have at most two conditions, and each rule either belongs to a cycle, or defines a connection between cycles. 3-kernel programs may have positive conditions. The 3-kernel normal form is very useful for the static analysis of program consistency, i.e., the syntactic characterization of existence of answer sets. This result can be obtained thanks to a novel graph-like representation of programs, called Cycle Graph which presented in the companion article \cite{Cos04b}.