 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Diagnoses of Acute Lymphoblastic Leukemia Using YOLOv8 and YOLOv11 Deep Learning Models
Oct 14, 2024



Thousands of individuals succumb annually to leukemia alone. This study explores the application of image processing and deep learning techniques for detecting Acute Lymphoblastic Leukemia (ALL), a severe form of blood cancer responsible for numerous annual fatalities. As artificial intelligence technologies advance, the research investigates the reliability of these methods in real-world scenarios. The study focuses on recent developments in ALL detection, particularly using the latest YOLO series models, to distinguish between malignant and benign white blood cells and to identify different stages of ALL, including early stages. Additionally, the models are capable of detecting hematogones, which are often misclassified as ALL. By utilizing advanced deep learning models like YOLOv8 and YOLOv11, the study achieves high accuracy rates reaching 98.8%, demonstrating the effectiveness of these algorithms across multiple datasets and various real-world situations.
Efficient Large-Scale Vision Representation Learning
May 24, 2023



In this article, we present our approach to single-modality vision representation learning. Understanding vision representations of product content is vital for recommendations, search, and advertising applications in e-commerce. We detail and contrast techniques used to fine tune large-scale vision representation learning models in an efficient manner under low-resource settings, including several pretrained backbone architectures, both in the convolutional neural network as well as the vision transformer family. We highlight the challenges for e-commerce applications at-scale and highlight the efforts to more efficiently train, evaluate, and serve visual representations. We present ablation studies for several downstream tasks, including our visually similar ad recommendations. We evaluate the offline performance of the derived visual representations in downstream tasks. To this end, we present a novel text-to-image generative offline evaluation method for visually similar recommendation systems. Finally, we include online results from deployed machine learning systems in production at Etsy.
adSformers: Personalization from Short-Term Sequences and Diversity of Representations in Etsy Ads
Feb 02, 2023



In this article, we present our approach to personalizing Etsy Ads through encoding and learning from short-term (one-hour) sequences of user actions and diverse representations. To this end we introduce a three-component adSformer diversifiable personalization module (ADPM) and illustrate how we use this module to derive a short-term dynamic user representation and personalize the Click-Through Rate (CTR) and Post-Click Conversion Rate (PCCVR) models used in sponsored search (ad) ranking. The first component of the ADPM is a custom transformer encoder that learns the inherent structure from the sequence of actions. ADPM's second component enriches the signal through visual, multimodal and textual pretrained representations. Lastly, the third ADPM component includes a "learned" on the fly average pooled representation. The ADPM-personalized CTR and PCCVR models, henceforth referred to as adSformer CTR and adSformer PCCVR, outperform the CTR and PCCVR production baselines by $+6.65\%$ and $+12.70\%$, respectively, in offline Precision-Recall Area Under the Curve (PR AUC). At the time of this writing, following the online gains in A/B tests, such as $+5.34\%$ in return on ad spend, a seller success metric, we are ramping up the adSformers to $100\%$ traffic in Etsy Ads.
Analysis and Optimal Edge Assignment For Hierarchical Federated Learning on Non-IID Data
Dec 10, 2020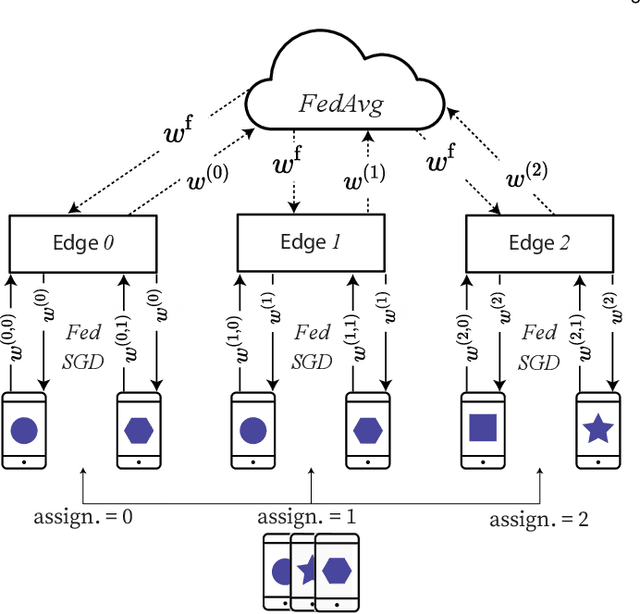
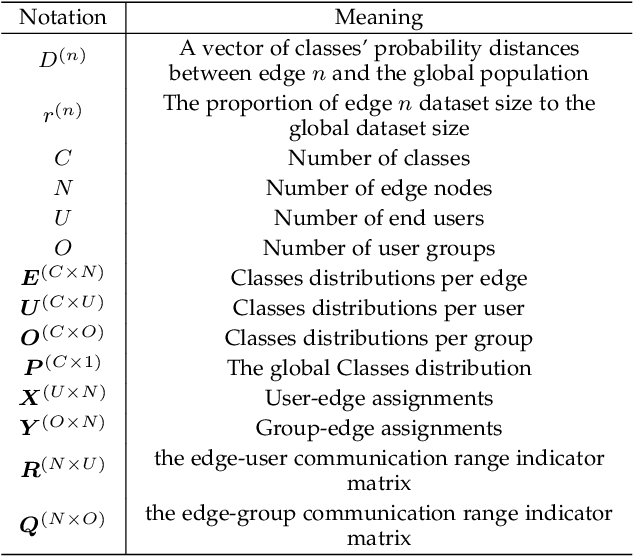
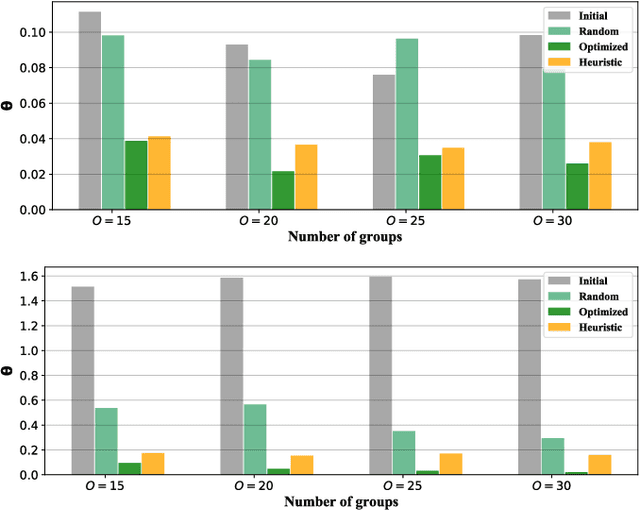
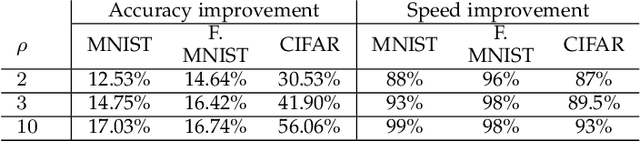
Learning-based applications have demonstrated practical use cases in ubiquitous environments and amplified interest in exploiting the data stored on users' mobile devices. Distributed learning algorithms aim to leverage such distributed and diverse data to learn a global phenomena by performing training amongst participating devices and repeatedly aggregating their local models' parameters into a global model. Federated learning is a promising paradigm that allows for extending local training among the participant devices before aggregating the parameters, offering better communication efficiency. However, in the cases where the participants' data are strongly skewed (i.e., non-IID), the model accuracy can significantly drop. To face this challenge, we leverage the edge computing paradigm to design a hierarchical learning system that performs Federated Gradient Descent on the user-edge layer and Federated Averaging on the edge-cloud layer. In this hierarchical architecture, the users are assigned to different edges, such that edge-level data distributions turn to be close to IID. We formalize and optimize this user-edge assignment problem to minimize classes' distribution distance between edge nodes, which enhances the Federated Averaging performance. Our experiments on multiple real-world datasets show that the proposed optimized assignment is tractable and leads to faster convergence of models towards a better accuracy value.