 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSIR: Spectral Client Identification and Relabeling for Federated Learning with Noisy Labels
Apr 22, 2026Federated learning (FL) enables collaborative model training without sharing raw data; however, the presence of noisy labels across distributed clients can severely degrade the learning performance. In this paper, we propose FedSIR, a multi-stage framework for robust FL under noisy labels. Different from existing approaches that mainly rely on designing noise-tolerant loss functions or exploiting loss dynamics during training, our method leverages the spectral structure of client feature representations to identify and mitigate label noise. Our framework consists of three key components. First, we identify clean and noisy clients by analyzing the spectral consistency of class-wise feature subspaces with minimal communication overhead. Second, clean clients provide spectral references that enable noisy clients to relabel potentially corrupted samples using both dominant class directions and residual subspaces. Third, we employ a noise-aware training strategy that integrates logit-adjusted loss, knowledge distillation, and distance-aware aggregation to further stabilize federated optimization. Extensive experiments on standard FL benchmarks demonstrate that FedSIR consistently outperforms state-of-the-art methods for FL with noisy labels. The code is available at https://github.com/sinagh72/FedSIR.
FB-NLL: A Feature-Based Approach to Tackle Noisy Labels in Personalized Federated Learning
Apr 21, 2026Personalized Federated Learning (PFL) aims to learn multiple task-specific models rather than a single global model across heterogeneous data distributions. Existing PFL approaches typically rely on iterative optimization-such as model update trajectories-to cluster users that need to accomplish the same tasks together. However, these learning-dynamics-based methods are inherently vulnerable to low-quality data and noisy labels, as corrupted updates distort clustering decisions and degrade personalization performance. To tackle this, we propose FB-NLL, a feature-centric framework that decouples user clustering from iterative training dynamics. By exploiting the intrinsic heterogeneity of local feature spaces, FB-NLL characterizes each user through the spectral structure of the covariances of their feature representations and leverages subspace similarity to identify task-consistent user groupings. This geometry-aware clustering is label-agnostic and is performed in a one-shot manner prior to training, significantly reducing communication overhead and computational costs compared to iterative baselines. Complementing this, we introduce a feature-consistency-based detection and correction strategy to address noisy labels within clusters. By leveraging directional alignment in the learned feature space and assigning labels based on class-specific feature subspaces, our method mitigates corrupted supervision without requiring estimation of stochastic noise transition matrices. In addition, FB-NLL is model-independent and integrates seamlessly with existing noise-robust training techniques. Extensive experiments across diverse datasets and noise regimes demonstrate that our framework consistently outperforms state-of-the-art baselines in terms of average accuracy and performance stability.
Transmit or Idle: Efficient AoI Optimal Transmission Policy for Gossiping Receivers
Feb 12, 2026We study the optimal transmission and scheduling policy for a transmitter (source) communicating with two gossiping receivers aiming at tracking the source's status over time using the age of information (AoI) metric. Gossiping enables local information exchange in a decentralized manner without relying solely on the transmitter's direct communication, which we assume incurs a transmission cost. On the other hand, gossiping may be communicating stale information, necessitating the transmitter's intervention. With communication links having specific success probabilities, we formulate an average-cost Markov Decision Process (MDP) to jointly minimize the sum AoI and transmission cost for such a system in a time-slotted setting. We employ the Relative Value Iteration (RVI) algorithm to evaluate the optimal policy for the transmitter and then prove several structural properties showing that it has an age-difference threshold structure with minimum age activation in the case where gossiping is relatively more reliable. Specifically, direct transmission is optimal only if the minimum AoI of the receivers is large enough and their age difference is below a certain threshold. Otherwise, the transmitter idles to effectively take advantage of gossiping and reduce direct transmission costs. Numerical evaluations demonstrate the significance of our optimal policy compared to multiple baselines. Our result is a first step towards characterizing optimal freshness and transmission cost trade-offs in gossiping networks.
Age-Aware Edge-Blind Federated Learning via Over-the-Air Aggregation
Feb 02, 2026We study federated learning (FL) over wireless fading channels where multiple devices simultaneously send their model updates. We propose an efficient \emph{age-aware edge-blind over-the-air FL} approach that does not require channel state information (CSI) at the devices. Instead, the parameter server (PS) uses multiple antennas and applies maximum-ratio combining (MRC) based on its estimated sum of the channel gains to detect the parameter updates. A key challenge is that the number of orthogonal subcarriers is limited; thus, transmitting many parameters requires multiple Orthogonal Frequency Division Multiplexing (OFDM) symbols, which increases latency. To address this, the PS selects only a small subset of model coordinates each round using \emph{AgeTop-\(k\)}, which first picks the largest-magnitude entries and then chooses the \(k\) coordinates with the longest waiting times since they were last selected. This ensures that all selected parameters fit into a single OFDM symbol, reducing latency. We provide a convergence bound that highlights the advantages of using a higher number of antenna array elements and demonstrates a key trade-off: increasing \(k\) decreases compression error at the cost of increasing the effect of channel noise. Experimental results show that (i) more PS antennas greatly improve accuracy and convergence speed; (ii) AgeTop-\(k\) outperforms random selection under relatively good channel conditions; and (iii) the optimum \(k\) depends on the channel, with smaller \(k\) being better in noisy settings.
Version Age of Information with Contact Mobility in Gossip Networks
Sep 18, 2025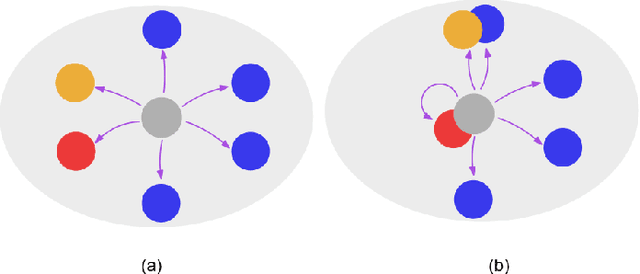



A gossip network is considered in which a source node updates its status while other nodes in the network aim at keeping track of it as it varies over time. Information gets disseminated by the source sending status updates to the nodes, and the nodes gossiping with each other. In addition, the nodes in the network are mobile, and can move to other nodes to get information, which we term contact mobility. The goal for the nodes is to remain as fresh as possible, i.e., to have the same information as the source's. To evaluate the freshness of information, we use the Version Age-of-Information (VAoI) metric, defined as the difference between the version of information available at a given node and that at the source. We analyze the effect of contact mobility on information dissemination in the gossip network using a Stochastic Hybrid System (SHS) framework for different topologies and mobility scalings with increasing number of nodes. It is shown that with the presence of contact mobility the freshness of the network improves in both ends of the network connectivity spectrum: disconnected and fully connected gossip networks. We mathematically analyze the average version age scalings and validate our theoretical results via simulations. Finally, we incorporate the cost of mobility for the network by formulating and solving an optimization problem that minimizes a weighted sum of version age and mobility cost. Our results show that contact mobility, with optimized mobility cost, improves the average version age in the network.
Status Updating with Time Stamp Errors
Apr 07, 2025A status updating system is considered in which multiple processes are sampled and transmitted through a shared channel. Each process has its dedicated server that processes its samples before time stamping them for transmission. Time stamps, however, are prone to errors, and hence the status updates received may not be credible. Our setting models the time stamp error rate as a function of the servers' busy times. Hence, to reduce errors and enhance credibility, servers need to process samples on a relatively prolonged schedule. This, however, deteriorates timeliness, which is captured through the age of information (AoI) metric. An optimization problem is formulated whose goal to characterize the optimal processes' schedule and sampling instances to achieve the optimal trade-off between timeliness and credibility. The problem is first solved for a single process setting, where it is shown that a threshold-based sleep-wake schedule is optimal, in which the server wakes up and is allowed to process newly incoming samples only if the AoI surpasses a certain threshold that depends on the required timeliness-credibility trade-off. Such insights are then extended to the multi-process setting, where two main scheduling and sleep-wake policies, namely round-robin scheduling with threshold-waiting and asymmetric scheduling with zero-waiting, are introduced and analyzed.
RCC-PFL: Robust Client Clustering under Noisy Labels in Personalized Federated Learning
Mar 25, 2025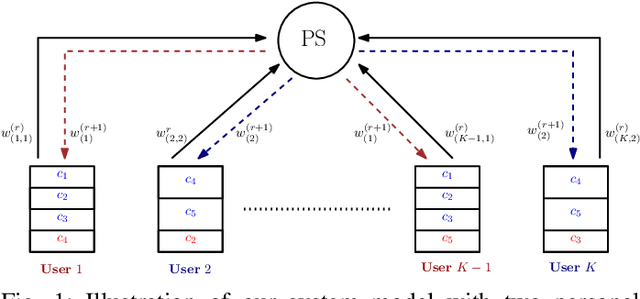
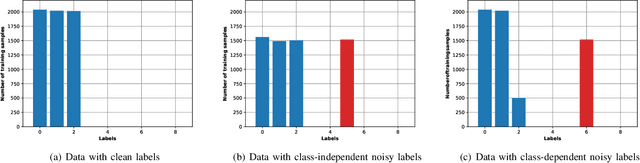
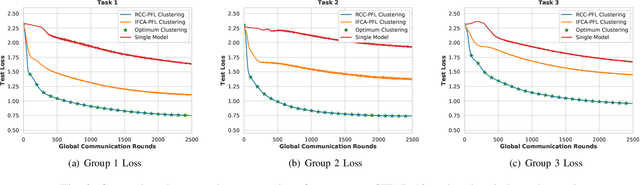
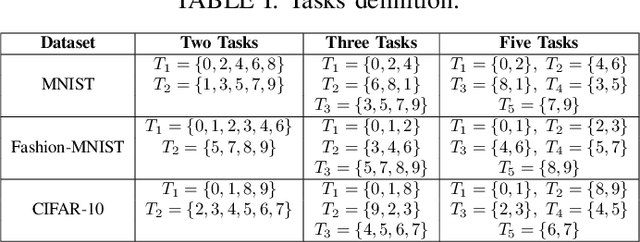
We address the problem of cluster identity estimation in a personalized federated learning (PFL) setting in which users aim to learn different personal models. The backbone of effective learning in such a setting is to cluster users into groups whose objectives are similar. A typical approach in the literature is to achieve this by training users' data on different proposed personal models and assign them to groups based on which model achieves the lowest value of the users' loss functions. This process is to be done iteratively until group identities converge. A key challenge in such a setting arises when users have noisy labeled data, which may produce misleading values of their loss functions, and hence lead to ineffective clustering. To overcome this challenge, we propose a label-agnostic data similarity-based clustering algorithm, coined RCC-PFL, with three main advantages: the cluster identity estimation procedure is independent from the training labels; it is a one-shot clustering algorithm performed prior to the training; and it requires fewer communication rounds and less computation compared to iterative-based clustering methods. We validate our proposed algorithm using various models and datasets and show that it outperforms multiple baselines in terms of average accuracy and variance reduction.
Data Similarity-Based One-Shot Clustering for Multi-Task Hierarchical Federated Learning
Oct 03, 2024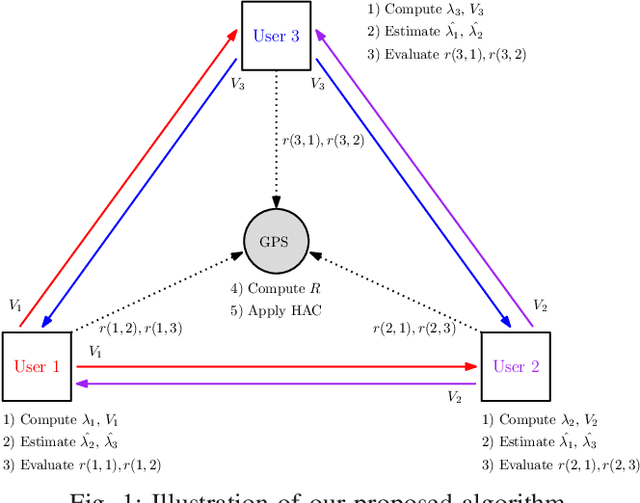
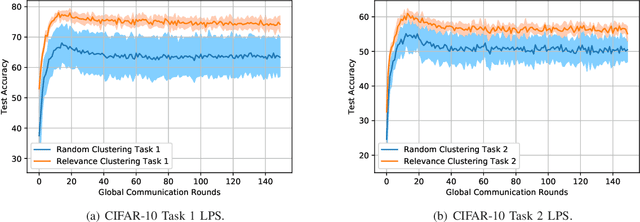
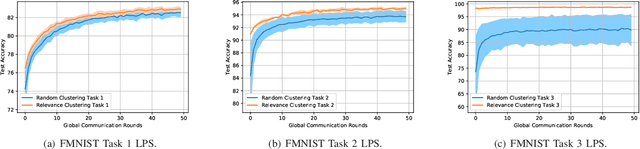
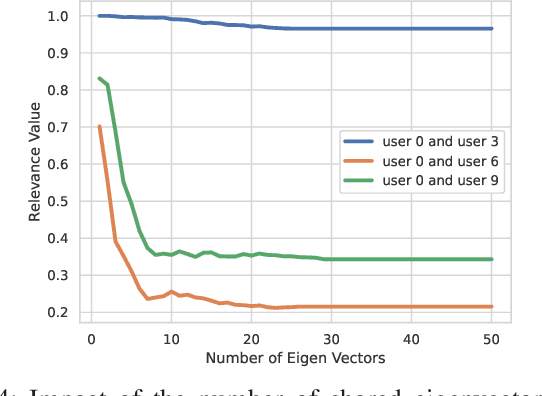
We address the problem of cluster identity estimation in a hierarchical federated learning setting in which users work toward learning different tasks. To overcome the challenge of task heterogeneity, users need to be grouped in a way such that users with the same task are in the same group, conducting training together, while sharing the weights of feature extraction layers with the other groups. Toward that end, we propose a one-shot clustering algorithm that can effectively identify and group users based on their data similarity. This enables more efficient collaboration and sharing of a common layer representation within the federated learning system. Our proposed algorithm not only enhances the clustering process, but also overcomes challenges related to privacy concerns, communication overhead, and the need for prior knowledge about learning models or loss function behaviors. We validate our proposed algorithm using various datasets such as CIFAR-10 and Fashion MNIST, and show that it outperforms the baseline in terms of accuracy and variance reduction.
Age and Value of Information Optimization for Systems with Multi-Class Updates
Aug 22, 2024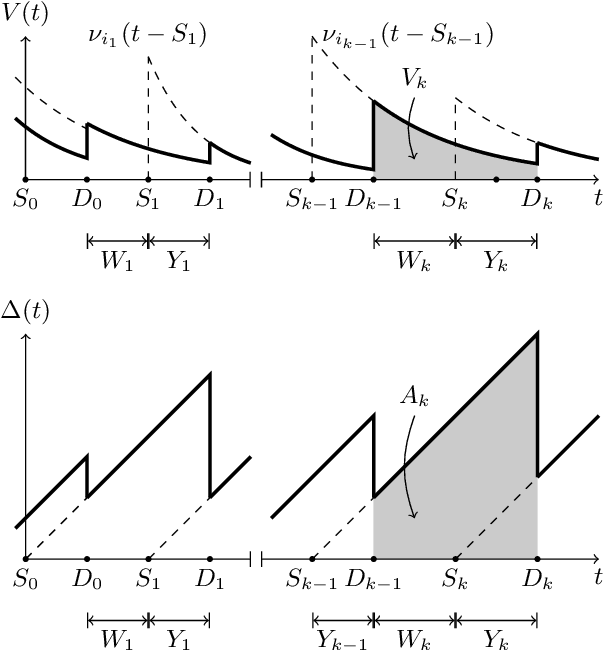
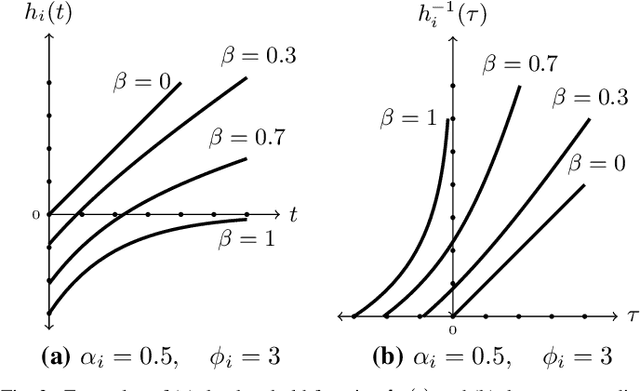
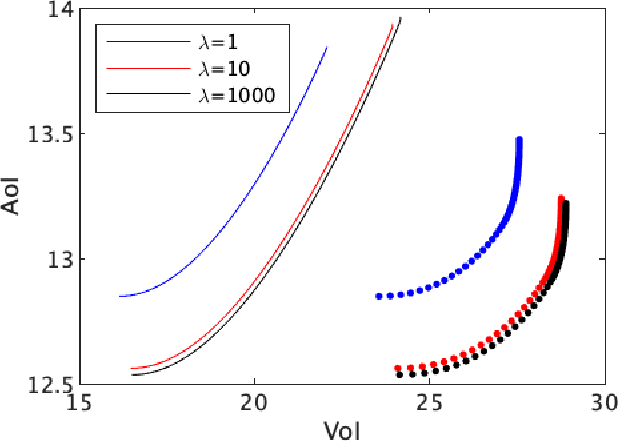
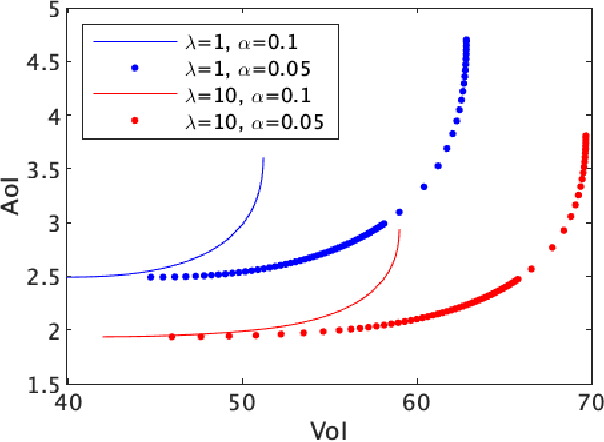
Received samples of a stochastic process are processed by a server for delivery as updates to a monitor. Each sample belongs to a class that specifies a distribution for its processing time and a function that describes how the value of the processed update decays with age at the monitor. The class of a sample is identified when the processed update is delivered. The server implements a form of M/G/1/1 blocking queue; samples arriving at a busy server are discarded and samples arriving at an idle server are subject to an admission policy that depends on the age and class of the prior delivered update. For the delivered updates, we characterize the average age of information (AoI) and average value of information (VoI). We derive the optimal stationary policy that minimizes the convex combination of the AoI and (negative) VoI. It is shown that the policy has a threshold structure, in which a new sample is allowed to arrive to the server only if the previous update's age and value difference surpasses a certain threshold that depends on the specifics of the value function and system statistics.
Private Status Updating with Erasures: A Case for Retransmission Without Resampling
Feb 23, 2023

A status updating system is considered in which a source updates a destination over an erasure channel. The utility of the updates is measured through a function of their age-of-information (AoI), which assesses their freshness. Correlated with the status updates is another process that needs to be kept private from the destination. Privacy is measured through a leakage function that depends on the amount and time of the status updates received: stale updates are more private than fresh ones. Different from most of the current AoI literature, a post-sampling waiting time is introduced in order to provide a privacy cover at the expense of AoI. More importantly, it is also shown that, depending on the leakage budget and the channel statistics, it can be useful to retransmit stale status updates following erasure events without resampling fresh ones.